
By Pascal LIBENZI.
Cloud Native Applications are more and more being talked about, often to describe complex distributed systems that are deployed on Cloud infrastructures, whether public or private.
You will find answers to these questions in this blog post.
Understand what is a Cloud Native Application:
The Cloud Native Computing Foundation, which is a SoKube partner, defines a Cloud Native Application as an application designed to operate efficiently in a Cloud environment (this also applies to on-premise environments).
A Cloud Native application is built using principles and practices that leverage the advantages offered by the Cloud infrastructure, such as:
The essential characteristics of a Cloud Native application, according to the CNCF:
Containerization: Cloud Native applications are packaged in containers. This approach enables portability and simplify the application’s management, detaching it from the underlying infrastructure and removing the strong coupling that may exist when using a specific Cloud service rather than a container. This doesn’t mean that you should not use the services provided around your application, but rather that you should use them appropriately, so that you don’t find yourself in a situation where your application needs to be rewritten to change the underlying infrastructure if needed.
Orchestration: With containers comes container orchestration (such as Kubernetes, managed or not), which handles deployment, automatic scaling, and load balancing.
Microservices: The microservices architecture is advocated in this approach. The application is decomposed into independent functional components called microservices, each with a clear and explicit API. The independence of these microservices allows scaling only what is necessary, i.e., a part of your application system, rather than the entire system. We will discuss later in this post about the "false" debate between microservices and monolith later.
Iterative development: Cloud Native applications are usually developed using agile methodologies, favoring short development cycles and frequent iterations. This enables development teams to iterate quickly on features, respond to changing requirements, and continuously deliver new functionalities. It’s important to note that this comes from the microservices architecture, which involves building smaller modules (microservices, not nano-services) and therefore having enhanced responsiveness and time-to-market capabilities.
As explained in the definition of what is a Cloud Native Application, the recommended architecture is a microservices architecture.
The advantages of a microservices architecture are numerous, but here is what they essentially bring:
| Monolithe | SOA | Microservices | |
|---|---|---|---|
| One-time memory overhead (GB) | 8 | 3 | 0.2 |
Decoupling: Since it is an architecture where each domain of your solution can be developed autonomously, it means that you can choose the programming language based on the actual need and the affinity of the team responsible for the microservice. You should not have direct dependency at the start of the application (other services, databases, etc.), avoiding complex startup orchestration during production deployments or unplanned restarts. Additionally, the microservice in question can be tested independently, with the exception of finding a solution to test interactions with other microservices. The service should be able to start quickly and access necessary resources later. If a resource is absent when the microservice needs it, a "degraded" mode should be provided, where the microservice can work without fulfilling all its functions.
Scalability: With decoupling and the autonomy of a microservice, its lifecycle can be very short, which allows for evolution, adding features, correcting behaviors, and redeploying without compromising other microservices and their delivery.
Deployment: Deployment is very simplified, mainly because the scope of the testing phase is reduced. We are not trying to test the entire solution, so we can deploy frequently with peace of mind. Deployment is more secure because the risk of breaking something is greatly reduced. We can even see it as an opportunity for continuous deployment, with less human checks needed, as the risk of bugs is low, and if a bug occurs, it can be quickly fixed (less code in a microservice, which means it is easier to understand the source of an anomaly and therefore greater responsiveness to fix it). In summary, we sorely reduce the risk!
No architecture is absolutely perfect, and this type of decomposition of a solution into microservices brings its fair share of challenges, primarily the following:
Increased inter-component communication: Unlike a monolithic architecture where everything happens within the same package, and network communication mostly occurs for external calls, there is a greater need for managing APIs and inter-components communication in a microservices architecture. Some components may need to communicate with each other to fulfill aggregation requirements, for example. Managing network calls, communication protocols, errors, and latency can become complex, especially when the number of microservices increases.
Product lifecycle management: In a monolithic architecture, the component is the product by definition, and therefore, inherent version management is relatively straightforward. In contrast, in a distributed architecture like microservices, even though there is normally no "strong" dependency between components, there are still considerations "weak" dependencies at runtime (presence or absence of functionality in a service accessed by another service using its API). You should be able to manage this easily in order to define what means a version of your product in terms of version for each microservice.
Deployment management: This is inherent to the product lifecycle management. Deploying (and, if necessary, rolling back) a microservice can involve compatibility issues if there is no product vision. API management is crucial in this architecture, and backward compatibility should always be ensured, at least during transition periods. Your new API should be introduced without breaking the existing one; instead, you should mark it as deprecated for a few versions, allowing other surrounding services to adapt before removing it permanently.
Security and authorization management: Authentication and authorization for API calls must be ensured. If you have only microservices, this logic must be implemented in each of these microservices, and any modification to these authentication and authorization methods must be replicated N times. Moreover, all communication between users and the application’s entrypoint or between microservices must be encrypted.
Observability: You need to be able to monitor both the performance of using a microservice and aggregate these results to match them with business flows. It is possible that a microservice performs well individually, but if it is called X times by another microservice, it may affect the performance of a functionality. You also want to aggregate your traces and logs, and correlate them to have a clear real-time view of what is happening in the application.
The nanoservice trap: Take care to not push too hardly the need for decomposition. It is often heard that there are issues with the number of components, and it becomes unclear in which service to implement a particular functionality. However, this refers to nanoservices, and it is a mistake often caused by the "all or nothing" mindset. Microservice decomposition should not be only driven by technical considerations. Each microservice should provide the functionalities of a business domain, not just a subset of functionalities, as this approach is too extreme and leads to many disadvantages.
There is also frequent mention of "rolling back to a monolithic architecture" when discussing microservices. However, when examples like Amazon explains the shift from a serverless model to a "monolith," it is important to question whether it is truly a monolith. In some cases, what is referred to as a monolith may actually be a microservice with a very narrow scope (e.g., a stateless process in AWS that fulfills a specific functional domain). Here is a diagram illustrating this "rollback":
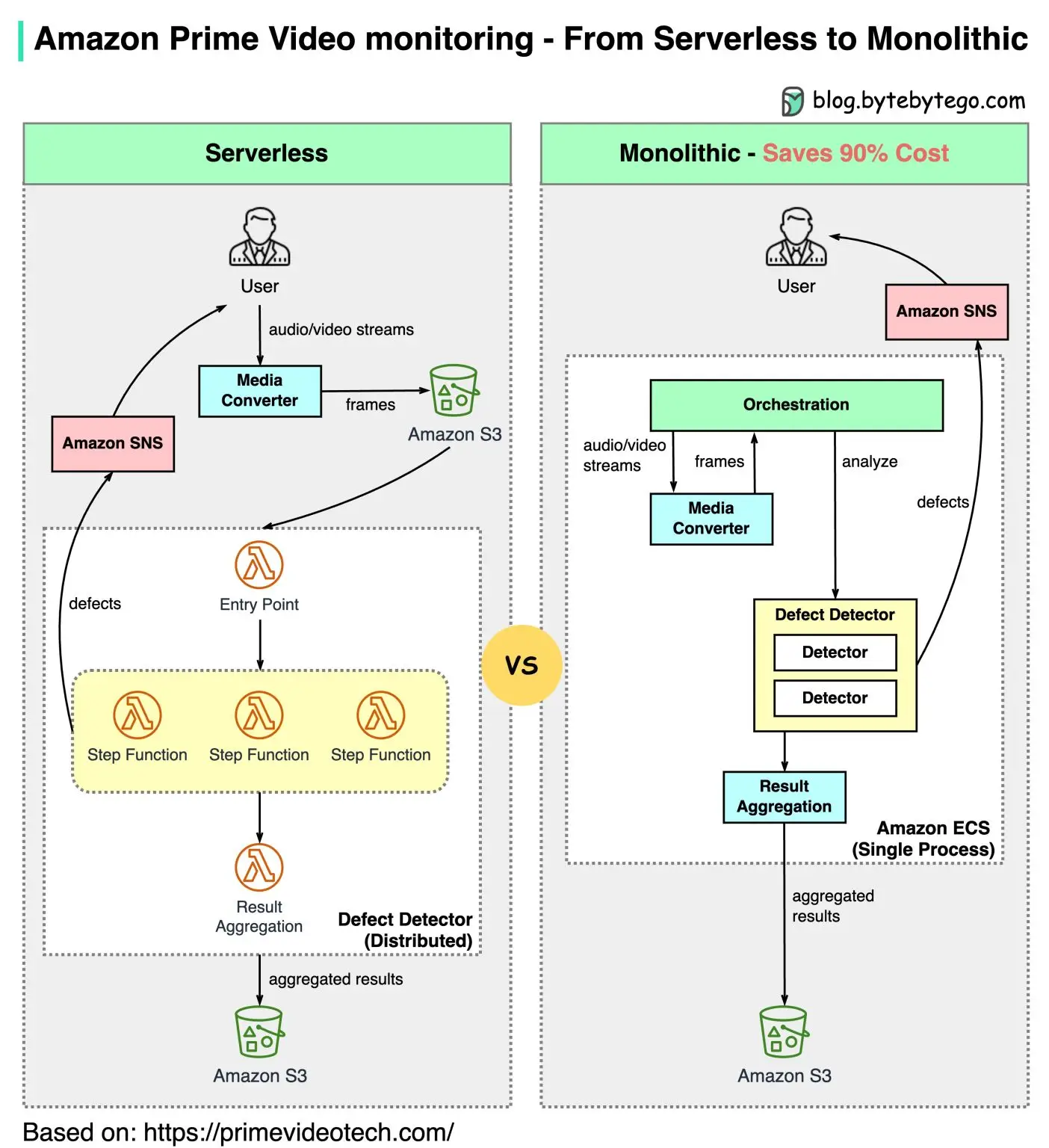
It is crucial to understand that each company and project have specific needs and contexts. There is no one-size-fits-all solution, and it is essential to consider the advantages and disadvantages of each approach. Decomposing into microservices can offer benefits such as scalability, ease of deployment, and isolation of functional domains. However, it requires careful planning and a good understanding of the system’s requirements.
It is recommended to consult additional resources, study real-world use cases, and gather practical insights before making major architectural decisions.
However, Cloud Native architecture is not limited to just a microservices architecture. A microservices architecture does not necessarily require containerization or container orchestration.
If you use to to develop microservices following the best practices of the twelve-factor app, then you know that any external service you need in your microservice should be considered as an external resource. Let’s take the example of secrets: if your deployment is in the cloud, then your secrets will probably be stored in a secure vault (preferably managed in the case of a public cloud). Your microservices should know how to retrieve such secrets as a resource (with the appropriate authorization) while having minimal coupling to the underlying infrastructure. The same principle applies to other standard services, such as databases and messaging services.
The architecture of a Cloud Native Application has a strong constraint related to horizontal scalability. Microservices must be stateless to be properly replicated without side effects, and the concept of state should be delegated to specialized services such as databases, messaging services, and replicated caches.
During the design of Cloud Native Applications, it is common to think about elements such as:
Observability is a crucial aspect imposed by Cloud Native architecture. With multiple microservices and external resources in place within these applications, it is essential to ensure that everything is working properly and is secured.
Observability encompasses several key points:
Finally, a Cloud Native architecture adds the requirement for infrastructure configuration to be declarative, enabling easier infrastructure management, quick recreation of identical environments, and detection of configuration drifts.
In a nutshell, a Cloud Native architecture is a microservices-oriented architecture that considers all aspects of the underlying cloud infrastructure and leverages the available resources within that infrastructure.
Given all of this, we can see that despite there are many advantages offered by a microservices architecture, there can also be significant challenges.
However, if our goal is to move toward a Cloud Native approach, it is essential for our applications to be architectured using microservices.
We need to consider the tools provided by our Kubernetes cluster to fully embrace this architecture.
We must also have a clear product vision and not view our system as just a collection of unrelated microservices. The independence of microservices does not imply complete autonomy in implementing an entire functionality perfectly. However, this does not mean that we desire a "distributed monolith".
Here’s a concrete example that illustrates a situation where there is indeed a weak runtime dependency between microservices: a functionality where the frontend wants to display a list of patients and their daily heart rate activity.
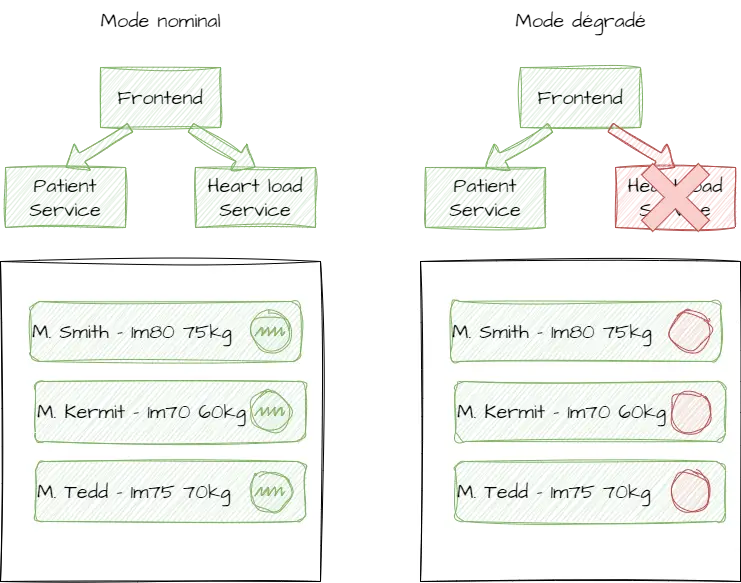
This example demonstrates that microservices are independent (none of them is blocked by the other) but not autonomous in fulfilling an entire functionality that requires aggregation. This is where resilient architecture to external factors and the concept of "Design for failure" come into play.
In order to minimize the challenges associated with a distributed architecture (often referred to as microservices, but these pain points are actually due to the distributed nature of this architecture), there are tools available to make our lives easier.
Regardless of the chosen implementation, the OpenTelemetry standard helps trace various events surrounding and within the microservice.
Most implementations use a trace identifier that can be propagated from the entry point of the invocation in the system to the return, allowing these traces to be aggregated and debugged in case of issues by examining the individual invocations. Almost all languages are supported by certain implementations, and these implementations provide libraries that can be easily added to your microservice to enable tracing quickly.
GitOps provides a declarative view of your product and its different components, each with its version, configuration, etc. This gives you a view of what is actually deployed and any potential drifts that may have been manually made. (See our article Promote changes and releases with GitOps)
GitOps allows you to have a product-centric approach. A "product" view can be defined by a simple YAML file with a list of microservices, their versions, and the associated configuration. The goal is to always deploy this complete set to ensure that nothing is completely broken and that the services can launch and perform basic functions (such as login). This type of implementation can be implemented even without a Kubernetes cluster or a tool that performs automatic deployment from a codebase, but it requires more work and a more extensive design phase, taking into account various aspects (Git flow used, when to deploy automatically, what controls must be setup).
If we revisit the previous diagram of our application for tracking patients’ cardiac activity over time, we could have a description of our product that looks like this in a Helm Chart with subcharts for the different components:
patient-followup-product:
product:
version: 0.0.1-2tx65i8
branch: main
patient-service:
version: 0.3.0-4heu83ju
branch: main
hearload-service:
version: 0.2.0-49rte32u
branch: main
# <...>Note that in Helm charts, the branch is not relevant in this declarative file. However, in a product-oriented approach composed by different microservices, it is often much simpler to have this information to understand where we stand. This way, even someone who is not closely involved in development can understand the currently deployed version of a specific microservice.
Also, note that the version of a microservice consists of its application version and its short-format commit identifier. We could keep only the unique commit identifier, which clearly describes the component’s version. However, development teams often prefer to retain the application version to benefit from semantic versioning and understand the potential impact between two versions of a component.
The service mesh can be your best friend if your deployments stands on Kubernetes. Here, we summarize the main advantages of using a service mesh and the features offered by most of the service mesh solutions. The goal is to remove as much technical complexity as possible from your microservices and delegate it to the service mesh.
We often see companies hesitate to implement a service mesh because, while it solves many complex issues, the setup of this tool can appear to be hard. In dedicated articles, we will demystify the different service mesh solutions and show how easy it is to set up at least their basic functionalities, which will help you address the most troublesome issues caused by this distributed architecture.
The first and significant advantage of a service mesh is that it allows you to encrypt traffic between all your services. This is crucial in a Zero Trust approach and can be easily done with any service mesh solution. Therefore, even if someone tries to compromise your Kubernetes cluster by gaining access to it, they will not be able to intercept communications and decrypt the data easily (provided you rigorously control what can be deployed as a resource on your Kubernetes cluster and by whom).
You can easily define rules to precisely determine which service is allowed to communicate with which service. In a Kubernetes cluster, this can be managed with Network Policies, which is already a good implementation, but can lead to significant complexity. Service mesh solutions offer different options to simplify communication permissions between components. You can define sources and destinations more generically (e.g., using labels, headers, or regular expressions).
A service mesh allows you to quickly identify bottlenecks in the network, often visually. This is very convenient when combined with traffic permissions. Several ways are possible, but my preferred one is to initially close all the valves in a dedicated environment, run tests, and then gradually open the necessary valves one by one. This also helps identify quickly which traffic permissions a new component requires during its implementation.
Most service mesh solutions also offer the ability to add an authentication mechanism before accessing a service. Let’s consider the following scenario:
Service mesh solutions generally allow you to perform more advanced deployment types than the simple default rollout included in Kubernetes. For example, you can often find Canary Deployment (dividing traffic between two versions of a microservice to test the new version with a user-defined set of users, based on headers in requests) or Blue/Green Deployment (gradually shifting traffic to the new version if the error rate is not too high).
Here is an example of what you can visually observe using Kiali if your service mesh is Istio (the examples are directly taken from Kiali’s documentation):
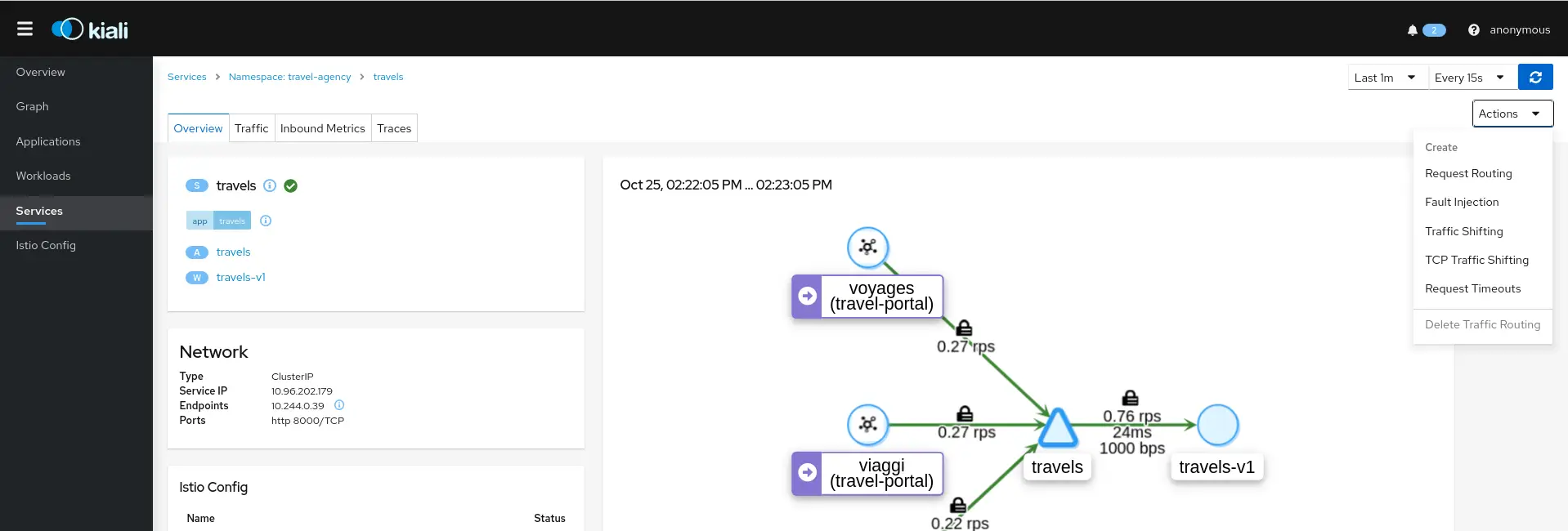
Here, you can see at a glance that mTLS is enabled between the microservices, indicated by the padlock positioned above the communication arrows.

In this screenshot, you can see which services and calls are causing issues.
Note that many other features are available when using Istio and Kiali, for example, error injection, aggregation of application traces, verification of the service mesh configuration, and many more. We are not detailing the different functionalities today, as they will be covered in a dedicated article on Istio during the service mesh series.
Although the not be spathimple, the answer to this question is, with very few exceptions, a resounding yes. This doesn’t mean that you will be able to migrate everything at once, and the journey is inevitably much longer for an existing product than for something that is just starting from scratch. It also doesn’t mean that you will necessarily want to make this effort for everything. Sometimes, it’s better not to migrate, and accept that part of our product has simply been adapted to go into the cloud can be acceptable. There is a question of palatability and costs to consider before going forward on such a migration process. There is also a strategic challenge in modernizing your IT.
Very often we can see companies betting everything on their new approaches. While this is commendable, it is common to realize that the burden of migrating to a new approach is huge and that the gain achieved is not always as expected; for instance, because by the time the migration is completed, the component is obsolete and replaced by another. And sometimes, we may wonder if the migration is a success, not because it doesn’t work or doesn’t bring the anticipated benefits, but simply because it ended up costing too much.
While it is really important to maximize the homogenization of the existing and new approaches when choosing a new one, it is important to remain pragmatic and make the right choices at the right time.
We can also talk about "Cloud Ready Applications," which is an unofficial term that simply refers to an application or a set of existing services that have been treated in a way that pushes them onto our new infrastructure. These applications may not necessarily enjoy all the advantages of our new platform (managed Kubernetes, on-premise Kubernetes, etc.), but they adapt to it and can be deployed on it while minimizing refactoring costs.
For example, we can take a large service in a SOA-oriented architecture and move towards the bare minimum:
Similarly, if we have an aging and stateful service, we need to be careful because some things may not be possible natively and easily (scaling horizontally will then be very complex, so we may have to make the sacrifice of having only a single instance).
We are, of course, dealing with a very minimalist list here, which will have implications for resource elasticity and the form of communication possible with this component.
I have made the decision to migrate my monolithic application from the 2000’s, which has evolved significantly and now consists of millions of lines of code, into a Cloud Native Application. How should I proceed?
First, consider the extent to which you want to make changes. You will need to rewrite certain parts, and let’s be honest, the journey will be long. Also, consider what you want (or what is accessible to you):
Here is a non-exhaustive list of points to consider when migrating to a Cloud Native architecture:
During the process of restructuring your architecture, it is crucial to validate the different evolutions as much as possible. If you don’t have end-to-end tests, now is the time to create them (whether manual or automated) to ensure non-regression. Start with a minimal scope, such as extracting the first microservice, and then parallelize the migrations.
Identify the microservices that should exist and if you feel the need to have some serverless components. However, ensure that your use case truly aligns with serverless architecture. An upcoming blog post will provide more information on this topic.
Identify the different flows that should exist in this new world, both between your microservices and between your application system and the external world.
Identify the resources you can use in your cloud environment:
Determine how to autonomously and easily rebuild the foundation of your infrastructure. Implementing infrastructure as code (IaC) using tools like Terraform and Ansible can be helpful.
Deploy the infrastructure, considering various components such as VMs, managed cloud services, databases, messaging buses, Kubernetes clusters, service mesh, and API gateways.
Choose the technology stack for your first microservice. Start with simple components and avoid implementing everything in the same language. Consider performance needs, internal team knowledge, and the resource consumption of different languages, especially if you’re using a public cloud.
Select the first functionality to migrate. For example, if you’re extracting a "user" module as a separate microservice, focus on a simple feature within that module. Implement basic CRUD operations in this new microservice and expose them through APIs. Initially, don’t worry about securing these APIs; the goal is to detach the module and not deploy it to production immediately. Instead of directly calling the module in the monolith, call the operations via APIs in the microservice, using the monolith as a pass-through between the frontend and microservice.
Now, focus on securing the APIs, which was intentionally ignored until this point. Identify the authentication mechanism you were using for users and services. You may consider migrating your authentication mechanism. Since the monolith acts as a pass-through between the frontend and the microservice, it needs to forward user information and be "transparent" to allow the new module to validate whether the user has the necessary rights to access certain functions. The implementation details out of scope here, but one approach is to call your OAuth provider with user information to obtain a JWT token and transfer it to the microservice.
After adding Role-Based Access Control (RBAC) to the pass-through functionalities of the monolith, add the required permissions to each API.
Deploy your microservice in a stable environment (not in production yet) along with your version of the monolith that supports communication with the microservice.
Test thoroughly. The success of your migration depends on the quality of your tests. Minimizing the risk of regression is crucial for the adoption and appreciation of your new architecture.
Move on to the next functionality from step 8, and then to the next one, until you complete the migration of the first microservice.
Deploy the new microservice and the updated version of the monolith in production.
Repeat the process from step 7 for each microservice.
Make sure your frontend directly (or indirectly, via an API gateway) interacts with the new microservices without needing the pass-through. At this stage, you may need to establish the link between your frontend and the OAuth provider to provide JWT tokens to the various backend services without involving the monolith.
Keep in mind that if you have the capability and a high level of maturity in this type of migration, you can parallelize the implementation of microservices. In the example given, we started from scratch, but it’s important to begin with a single microservice to get acquainted with the process.
In conclusion, migrating to a Cloud Native architecture is not always straightforward. It’s important to weigh the pros and cons and consider which components should be migrated as Cloud Native Applications and which can be adapted as Cloud Ready Applications.
Understanding that this architecture is inspired by cloud best practices, making such an effort is also valuable for on-premise infrastructures. It allows you to embrace containerization, potentially utilize technologies like serverless to optimize resource usage, scale according to your needs, and improve time-to-market for new features while enhancing the reliability of your product.
If you want to delve deeper into this vast subject, SoKube provides a Cloud Native Applications.
The upcoming articles in this Cloud Native Applications series will focus on various service meshes, with the first article expected to be available by the end of June. Stay tuned!