
By Pascal LIBENZI.
On entend de plus en plus parler de Cloud Native Applications, souvent pour décrire des systèmes complexes distribués qui sont déployés sur des infrastructures Cloud, qu’elles soient publiques ou privées.
Mais quelle est réellement la définition d’une Cloud Native Application ? Quels sont les avantages que l’on tire de l’architecture Cloud Native ? Est-ce qu’on peut et est-ce qu’on veut migrer une partie ou tout notre existant vers ce type d’architecture ? Pourquoi les architectures traditionnelles ne conviennent plus ?
Vous trouverez dans ce blog post les éléments de réponses à ces différentes questions.
Comprendre la notion de Cloud Native Application :
La CNCF (Cloud Native Computing Foundation, partenaire de SoKube) définit une Cloud Native Application (ou application nativement cloud) comme une application spécifiquement conçue pour fonctionner efficacement dans un environnement Cloud (ceci s’applique aussi aux environnements on-premise).
Une application dite Cloud Native est construite en utilisant des principes et des pratiques qui exploitent les avantages de l’infrastructure offerte par le Cloud, tels que la mise à l’échelle automatique, la résilience, la flexibilité, la sécurité "by design" et la gestion efficace des ressources.
Les caractéristiques essentielles d’une application Cloud Native selon la CNCF sont les suivantes :
Conteneurisation : les applications Cloud Native sont empaquetées dans des conteneurs. Cette approche permet une portabilité et une gestion simplifiée de l’application, vous détache de l’infrastructure sous-jacente et supprime le lien fort que vous pourriez avoir en utilisant un service spécifique de votre Cloud plutôt qu’un conteneur. Attention ceci ne veut pas dire qu’il ne faut pas utiliser les services proposés autour de votre application, mais simplement qu’il faut les utiliser à bon escient, pour ne pas vous retrouver dans une situation où votre application devrait être réécrite pour changer d’infrastructure si le besoin se présente.
Orchestration : avec les conteneurs vient souvent l’orchestration de conteneurs (cluster Kubernetes, managé ou non) pour les gérer : leur déploiement, leur mise à l’échelle automatique, et leur répartition de charge notamment.
Microservices : l’architecture microservices est prônée dans cette approche. L’application est décomposée en composants fonctionnels indépendants, appelés microservices avec une API claire et explicite. L’indépendance de ces microservices permet une mise à l’échelle au besoin uniquement de ce qui est nécessaire , c’est à dire d’une partie de votre système applicatif et non pas de l’entièreté de celui-ci, en plus d’aider à l’évolutivité de la solution. Nous verrons plus tard le "faux" débat entre microservices et monolithe.
Développement itératif : Les applications cloud natives sont généralement développées selon des méthodologies agiles, favorisant des cycles de développement courts et des itérations fréquentes. Cela permet aux équipes de développement d’itérer rapidement sur les fonctionnalités, de réagir aux besoins changeants et de livrer de manière continue de nouvelles fonctionnalités. Il faut noter que ceci découle de l’essence même de l’architecture microservices qui implique de réaliser de plus petits modules (on parle bien de microservices et pas de nano-services) et donc d’avoir une capacité de réaction et de mise sur le marché accrues.
Comme expliqué lors de la définition de ce qu’est une CNA, l’architecture recommandée est une architecture microservices.
Les avantages d’une architecture microservices sont nombreux, mais voici ce qu’ils apportent essentiellement :
| Monolithe | SOA | Microservices | |
|---|---|---|---|
| Surcoût ponctuel mémoire (Gb) | 8 | 3 | 0.2 |
Découplage : Comme c’est une architecture où chaque domaine de votre solution peut être développé de manière autonome, cela signifie qu’on peut choisir le langage de programmation réellement en fonction du besoin et de l’affinité de l’équipe en charge du module. Il n’y a surtout pas de dépendance directe forte au démarrage de l’application (autres services, base de données, …) évitant ainsi une orchestration de démarrage complexe lors des mises en production ou suite à des redémarrages non planifiés. De plus, le microservice en question peut être testé indépendamment, à ceci prêt qu’il faut trouver une solution pour tester les interactions avec d’autres microservices. Le service doit pouvoir démarrer rapidement et accéder aux ressources nécessaires plus tard. Si celles-ci sont absente il faut prévoir un mode "dégradé", où le microservice peut fonctionner sans remplir l’entièreté de ses fonctions.
Évolutivité : Avec le découplage et l’autonomie d’un microservice, son cycle de vie peut être très court, ce qui amène à pouvoir le faire évoluer, ajouter des fonctionnalités, corriger des comportements, relivrer, sans compromettre les autres microservices et leur livraison.
Déploiement : Le déploiement est grandement simplifié, notamment car le scope de la phase de tests est réduit. On ne cherche pas à tester l’entièreté de la solution et on peut donc déployer souvent en toute sérénité. Le déploiement est plus sécurisé, car le risque de casser une fonctionnalité est grandement amoindri. On peut même y voir l’occasion de faire du déploiement continu, sans trop de contrôle humain, car le risque d’anomalie est faible, et si une anomalie survient elle peut être rapidement corrigée (moins de code dans un microservice, ce qui veut dire plus de faciliter à comprendre la source d’une anomalie et donc une plus grande réactivité pour la corriger). En résumé nous réduisons fortement le risque !
Aucune architecture n’étant absolument parfaite, ce type de découpage d’une solution en microservices amène son lot de challenges, essentiellement les suivants :
communication inter-composants accrue : contrairement à une architecture monolithique ou tout se passe dans le même package et donc finalement où la communication dépasse se package uniquement pour des appels externes, nous avons là un besoin de gestion plus important de la gestion des APIs. Certains composants peuvent être amenés à devoir communiquer entre eux pour répondre à un besoin d’agrégation par exemple. La gestion des appels réseau, des protocoles de communication, des erreurs et des latences peut devenir complexe, surtout lorsque le nombre de microservices augmente.
gestion du cycle de vie du produit : dans une architecture monolithique, le composant est le produit par définition et donc la gestion de version inhérente de celui-ci est assez simpliste. Contrairement à cela, si vous devez définir une version de produit dans une architecture distribuée, comme les microservices, même si il n’existe normalement pas de dépendance "forte" entre deux composants il reste la question des dépendances "faibles" (fonctionnalité présente ou non dans un service contacté par un autre service via une API). Il vous faut alors pouvoir facilement gérer ceci de manière à définir simplement ce qu’est une version de votre produit par rapport à la version de chaque microservice.
gestion des déploiements: de manière inhérente finalement à la gestion du cycle de vie, la gestion du déploiement et si besoin du rollback de tel ou tel microservice peut impliquer, si il n’y a pas de vision produit, des soucis en terme de compatibilité, la gestion des APIs est essentielle dans cette architecture et la rétrocompatibilité doit toujours être assurée au moins pendant des périodes de transition (votre nouvelle API doit voir le jour sans supprimer l’ancienne, vous devez la marquer comme dépréciée pour quelques versions le temps que les autres services autour s’adapte avant de la supprimer définitivement).
sécurité et gestion des autorisations : l’authentification et les autorisations pour tout appel à une API doivent être assurées. Si nous n’avons que des microservices, alors il faut implémenter cette logique dans chacun de ces microservices, et chaque modification de ces méthodes d’authentification et d’autorisations doit être répercutée N fois. Qui plus est toute communication entre les utilisateurs et la porte d’entrée de votre application, ou encore entre deux microservices doivent être chiffrées.
observabilité : il faut être capable à la fois de surveiller la performance intrinsèque à l’utilisation d’un microservice, mais aussi être capable d’agréger ces résultats pour les faire correspondre à des flux métiers. Il se peut effectivement qu’un microservice soit performant unitairement mais que comme celui-ci est appelé X fois par un autre microservice cela nuise à la performance d’une fonctionnalité. Il faut aussi savoir agréger vos traces et vos logs, pouvoir les corréler pour pouvoir avoir une vision clair de ce qui se produit dans l’applicatif en temps réel.
piège du nanoservice: il faut faire attention à ne pas pousser à l’extrême le besoin de découpage. Il arrive bien souvent d’entendre qu’il y a des soucis en terme de nombres de composants, qu’on ne sait plus dans quel service coder telle ou telle fonctionnalité. Attention, il s’agit là de nanoservices, et c’est une erreur souvent produite par le "tout ou rien". Un découpage en microservice ne doit pas être guidé par la technique, chaque microservice doit assurer les fonctionnalités d’un domaine, et pas seulement un subset de fonctionnalités de ce domaine, car ceci est trop extrémiste et amène alors bien des inconvénients.
On entend aussi souvent parler de "rollback de l’architecture microservice" vers des architectures plus proche du monolithe. Attention, quand Amazon explique par exemple avoir repensé son modèle serverless pour aller vers du "monolithe", et la question est alors : est-ce qu’on parle vraiment d’un monolithe ? Il est évoqué un monolithe, mais qui est sur un scope si réduit que c’est en fait… un microservice (le process dans AWS est tout simplement un microservice, stateless, qui ne remplit qu’un domaine fonctionnel), voici le schéma de ce "rollback":
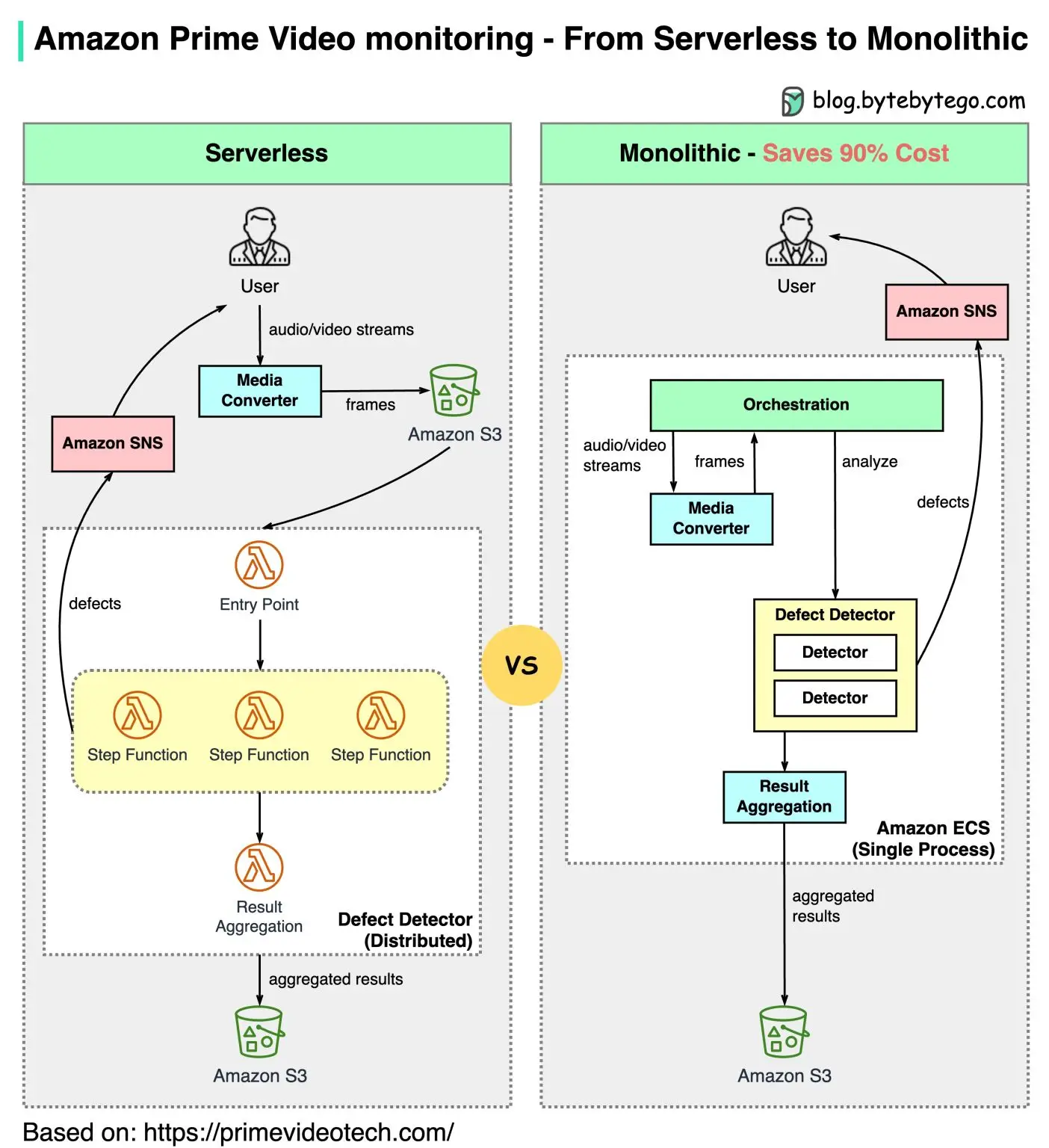
Cependant l’architecture Cloud Native ne se limite pas juste à une architecture microservices. Une architecture microservices n’impose par ailleurs pas la conteneurisation, ni l’orchestration des conteneurs.
Si vous avez l’habitude de développer des microservices en suivant les bonnes pratiques de la twelve-factor app, alors vous savez que vous traitez n’importe quel service externe dont vous avez besoin dans votre microservice comme une ressource. Prenons l’exemple des secrets : si votre destination est dans un Cloud, alors vos secrets seront très certainement stockés dans un coffre-fort (de préférence managé dans le cas d’un Cloud public). Vos microservices doivent alors savoir comment aller récupérer ce type de secret, vu comme une ressource (et doivent bien entendu y être autorisés), en ayant le moins d’adhérence possible à l’infrastructure sous-jacente. Il en va de même pour différents services plus standard, tels que les bases de données, les services de messagerie, …
L’architecture d’une Cloud Native Application a aussi une contrainte forte liée à la possibilité de mise à l’échelle horizontale : les microservices doivent être stateless pour pouvoir être correctement répliqués sans effet de bord et dédier la notion d’état à des services spécialisés (bases de données, services de messagerie, cache répliqué, …).
Il est très fréquent lors de la conception de Cloud Native Applications de trouver des éléments tels que :
Un aspect imposé par l’architecture Cloud Native porte sur l’observabilité du système. Avec les multiples microservices et ressources externes qui sont mis en place au sein de ces applications, il faut s’assurer que tout fonctionne correctement et que tout est correctement sécurisé.
L’observabilité est essentielle, en voici quelques points clefs:
Pour finir sur ce qu’ajoute une architecture Cloud Native, on doit pouvoir retrouver la configuration de l’infrastructure de manière déclarative, ce qui permet une gestion plus simple de l’infrastructure, la possibilité de pouvoir recréer rapidement un environnement à l’identique, la détection de drifts de configuration.
Finalement une architecture Cloud Native est une architecture orientée microservices qui prend en compte tous les aspects du Cloud sur laquelle elle va reposer, et s’appuie sur les ressources disponibles dans cett infrastructure.
Tout ceci étant posé, on voit bien que malgré tous les avantages avancés par une architecture de type microservices, les inconvénients peuvent être de véritables pain points.
Mais nous voulons aller vers du Cloud Native, et il est essentiel pour nous, afin de prétendre au Cloud Native d’avoir des applications architecturées en microservices.
Il faut alors prendre en considération les outils proposés autour de notre cluster Kubernetes pour essayer de nous réconcilier complètement avec cette architecture.
Il faut aussi clairement avoir une vision produit et ne pas voir son système comme juste des microservices qui n’ont rien à voir les uns avec les autres. L’indépendance des microservices n’est pas synonyme d’une autonomie totale pour réaliser l’ensemble d’une fonctionnalité de manière parfaite. Ce qui ne veut pas dire que nous voulons un monolithe "distribué".
Exemple de cas concret où effectivement nous avons une dépendance faible entre les microservices : une fonctionnalité où le frontend veut renvoyer une liste de patients et leur activité cardiaque au quotidien.
Voici un schéma très sommaire du fonctionnement dégradé ci-dessus :
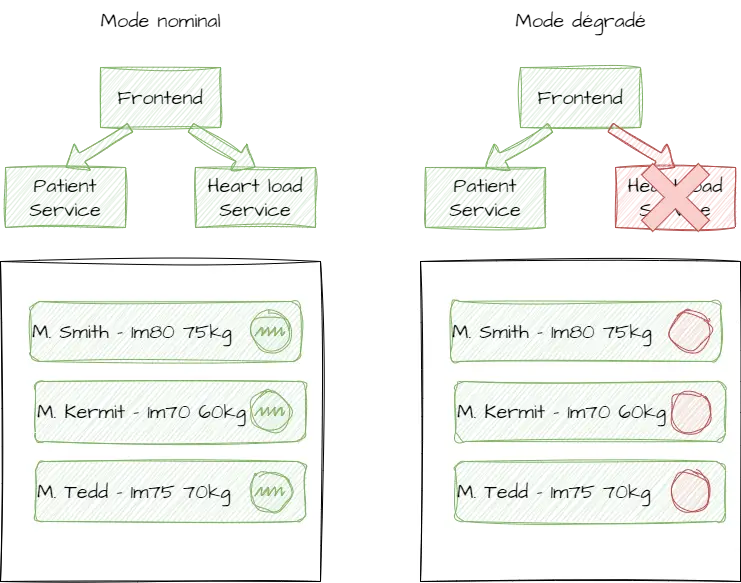
Cet exemple démontre bien que les microservices sont indépendants (aucun n’est bloqué par rapport à l’autre) mais pas autonome pour remplir l’intégralité une fonctionnalité qui nécessite une agrégation. On parle alors d’architecture résiliente aux phénomènes extérieurs et de "Design for failure".
Afin de diminuer la douleur dûe à une architecture distribuée (on parle beaucoup de microservices, mais ces pain points sont en fait dûs au caractère distribué de cette architecture), il existe des outils pour nous permettre de se faciliter la vie.
Quelle que soit l’implémentation choisie, le standard OpenTelemetry aide à tracer les différents événements autour et dans le microservice. La plupart des implémentations utilisent un identifiant de trace, qui peut être propagé à partir du point d’entrée de l’invocation dans le système jusqu’au retour, ce qui permet d’agréger ces traces et debugger en cas de souci en voyant les différentes invocations unitaires. Tous les langages ou presque sont supportés par certaines implémentations, et celles-ci fournissent des librairies que vous pouvez très facilement ajouter à votre microservice pour pouvoir réaliser le tracing en un temps record.
GitOps apporte une vision déclarative de votre produit, et de ses différents composants, avec pour chacun leur version, leur configuration, … Ceci vous donne une vision de ce qui est réellement déployé et des potentiels écarts qui ont pu être réalisés manuellement. (voir notre article Promouvoir les changements et les releases avec GitOps
Le gitops est ce qui vous permet d’avoir une approche produit. Une vision "produit" peut être définie par un simple fichier YAML avec une liste de microservices, leurs versions, et la configuration associée. On essaie alors de déployer toujours tout cet ensemble afin de s’assurer à minima qu’il n’y ait pas quelque chose de complètement cassé et que les services puissent à minima se lancer et exécuter des fonctions de base (login par exemple).
On peut bien sûr aller vers ce type d’implémentation sans même avoir de cluster Kubernetes, ou d’outil qui fasse de déploiement automatique à partir d’une base de code, mais cela requiert une charge de travail et une phase de conception beaucoup plus importante, en tenant en compte différents aspects (Git flow utilisé, quand veut-on déployer de manière automatique, quels sont les contrôles en place).
Si nous reprenons le schéma précédent sur notre application de suivi de charge cardiaque des patients dans le temps, alors nous pourrions avoir un descriptif de notre produit qui ressemblerait à ceci dans un Chart Helm avec des subcharts pour les différents composants:
patient-followup-product:
product:
version: 0.0.1-2tx65i8
branch: main
patient-service:
version: 0.3.0-4heu83ju
branch: main
hearload-service:
version: 0.2.0-49rte32u
branch: main
# <...>Notons que dans les charts Helm, la branche ne nous intéresse potentiellement pas dans ce fichier déclaratif. Cependant dans une approche de type produit composée de différents microservices, il est souvent beaucoup plus simple pour comprendre où nous en sommes d’avoir cette information, ainsi même quelqu’un qui est un peu moins proche du développement peut comprendre d’où vient la version actuellement déployée de tel ou tel microservice.
Notons aussi que la version d’un microservice est composée de sa version applicative et de son identifiant de commit au format court. On pourrait conserver uniquement l’identifiant du commit qui et unique et décrit donc clairement la version du composant, mais il est souvent préféré par les équipes de développement de conserver la version applicative afin de bénéficier du versionnement sémantique pour comprendre l’impact potentiel entre deux versions.
Le service Mesh est très certainement votre meilleur ami si vos déploiements sont réalisés sur Kubernetes. Nous essayons ici de résumer les principaux avantages liés à l’utilisation d’un service Mesh, et les points communs sur la plupart des services Mesh. Le but étant d’enlever le maximum de complexité technique à vos micro-services et de déléguer cela au service mesh.
Nous voyons bien souvent des entreprises hésiter sur la mise en place d’un service mesh, et comme cela reste quelque chose qui résoud beaucoup de choses complexes, nous pouvons craindre la complexité de la mise en place de cet outil. Nous démystifierons dans des articles dédiés les différents services mesh, et nous verrons à quel point il est simple de mettre en place à minima les fonctionnalités de base de ceux-ci, qui vous aideront à résoudre les soucis les plus gênants dûs à cette architecture distribuée.
Le premier avantage, et pas des moindres, d’un service Mesh, est qu’il vous permet de faire du chiffrement de traffic entre tous vos services. Ceci est primordial dans une approche Zero-trust et se fait très facilement dans tous les services Mesh.
Ainsi, vous savez que même si quelqu’un essaie de corrompre votre cluster Kubernetes car il a réussi à y gagner l’accès, il ne pourra pas intercepter les communications et déchiffrer la donnée de manière simple (si vous contrôlez de manière rigoureuse ce qui peut être déployé comme ressource sur votre cluster Kubernetes et par qui).
On peut très facilement définir des règles pour définir très précisément quel service a le droit de communiquer avec quel service. En temps normal, dans un cluster Kubernetes, vous pouvez gérer cela avec des Network Policies. C’est déjà très bien mais cela peut mener à une complexité non négligeable. Les services Mesh proposent différentes options qui permettent de simplifier les permissions de communications entre composants. On peut définir les sources et les destinations de manière plus génériques (par exemple avec l’utilisation de labels, de headers, ou encore d’expressions régulières).
Un service Mesh permet de voir rapidement les points de blocage dans le réseau, de manière visuelle pour certains. Ce qui est très pratique quand on couple cela à des permissions de trafic. Plusieurs approches sont bien entendu possibles, ma préférée étant de globalement se permettre de fermer toutes les vannes sur un environnement dédié à cela, exécuter les tests et rouvrir les vannes nécessaires une par une. Ceci permet aussi, lors de la mise en place d’un nouveau composant, d’identifier très rapidement quelles sont les permissions de trafic qui lui sont nécessaire.
La plupart des services mesh proposent aussi d’automatiquement ajouter un mécanisme d’authentification avant d’accéder à un service.
Imaginons le cas suivant :
Un service Mesh permet généralement de réaliser cela, en ajoutant une règle d’authentification au-dessus du service B, et en précisant les différentes informations sur le fournisseur du jeton (URI, audiences, jwks, …)
Les services Mesh vous permettent généralement d’effectuer des types de déploiement plus avancés que le simple rollout par défaut inclus dans Kubernetes. En effet, on peut souvent trouver du Canary Deployment (couper le traffic en deux entre deux versions d’un microservice pour tester la nouvelle version avec un set d’utilisateurs qui peut être défini – ou pas – en fonction de headers dans les requêtes), ou encore du Blue/Green Deployment (le trafic va progressivement aller vers la nouvelle version si il n’y a pas un taux d’erreur trop fort).
Voici ce qu’on peut par exemple observer de manière très visuelle en utilisant Kiali si notre service Mesh est Istio (les exemples sont tirés directement ici de la documentation Kiali) :
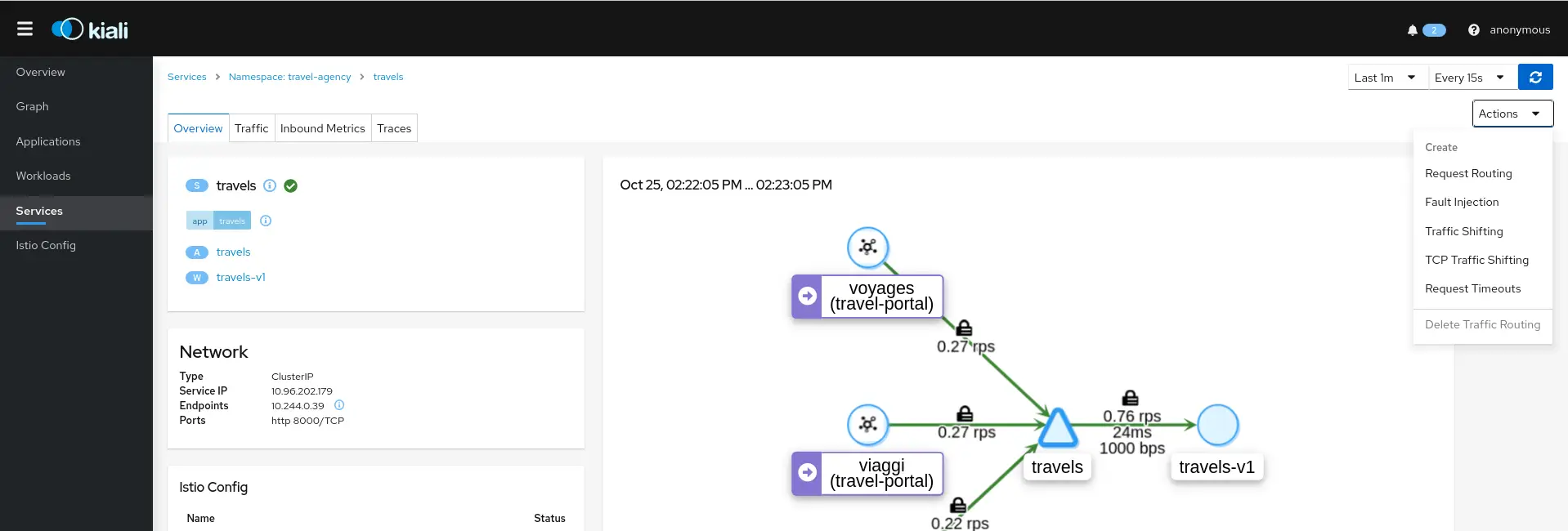
On peut voir ici que le mTLS est activé entre les microservices par un simple coup d’œil, il s’agit du cadenas positionné au-dessus des flèches de communication.
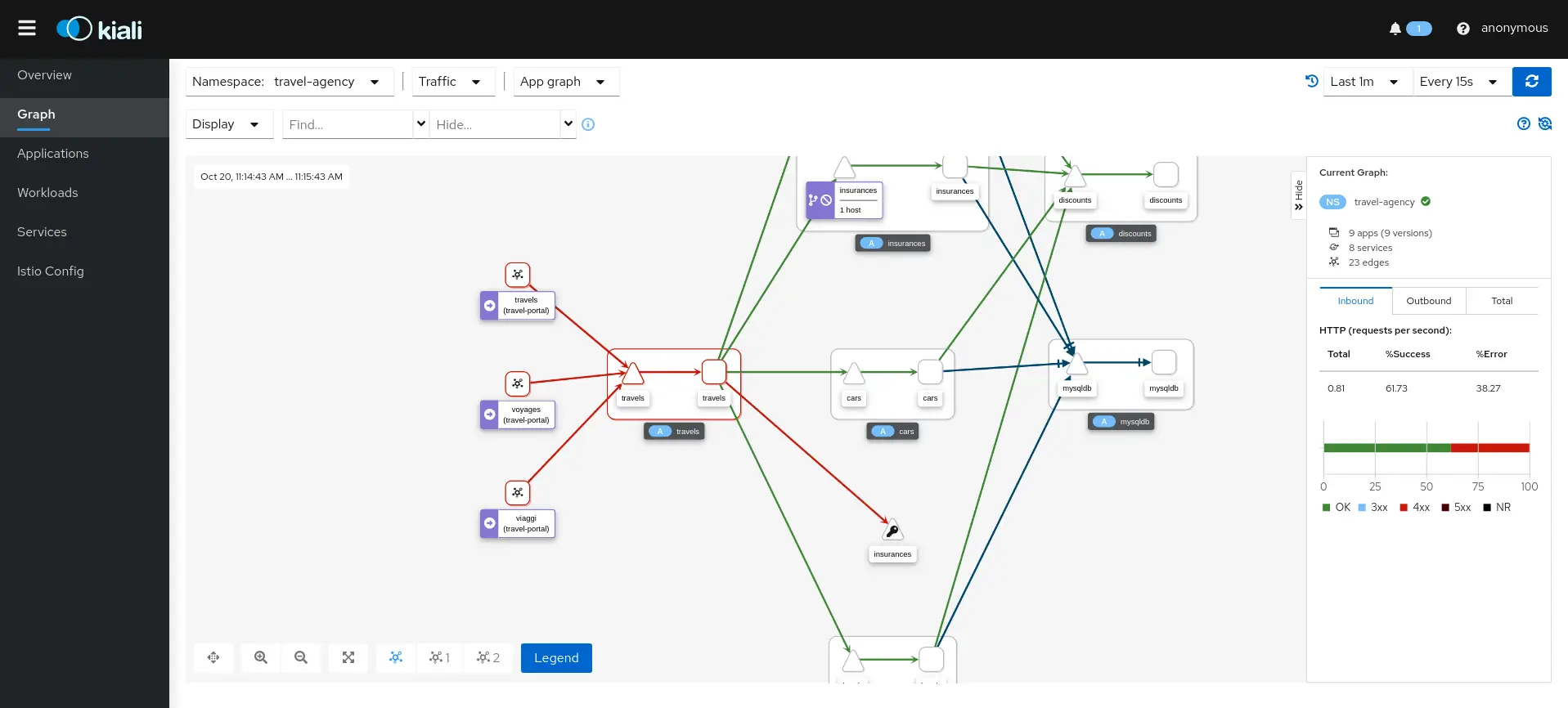
Sur cette impression écran nous pouvons voir quels services et appels posent problème.
Notons que bien d’autres fonctionnalités sont disponibles en utilisant Istio et Kiali par exemple (injection d’erreurs, agrégation des traces applicatives, vérification de la configuration du service Mesh, et bien d’autres fonctionnalités encore). Nous ne détaillons pas aujourd’hui les différentes fonctionnalités qui feront l’objet d’un article dédié sur Istio lors de la série sur les services Mesh.
Si le chemin n’est pas simple, la réponse à cette question est pourtant, à de très rares exceptions près, un grand oui.
Cela ne veut pas dire que vous allez pouvoir tout migrer d’un coup, et la route est forcément beaucoup plus longue pour un produit existant que pour quelque chose qui débute à peine.
Cela ne veut pas non plus dire que vous allez vouloir faire cet effort. Parfois le jeu n’en vaut pas la chandelle, et accepter qu’une partie de notre produit a simplement été adaptée pour aller dans le Cloud peut être acceptable. Il y a là une question d’envie, et une vraie question de coût à se poser avant d’entamer une telle démarche. Et aussi un enjeu stratégique dans la modernisation de votre IT.
Il n’est pas rare de voir des entreprises tout miser sur leurs nouvelles approches. Bien que ce soit tout à leur honneur, finalement il n’est pas rare de se rendre compte que la charge de migrer sur une nouvelle approche est énorme et que le gain apporté n’est pas toujours celui espéré, par exemple parce que le temps que la migration se fasse le composant est obsolète et est remplacé par un autre. Et finalement on peut parfois en arriver à se demander si la migration est un succès, non pas parce que ça ne fonctionne pas, ou qu’on n’en tirerait pas les avantages imaginés, mais juste parce que cela a fini par coûter trop cher.
Si il est très important lorsqu’on choisit une nouvelle approche d’essayer de maximiser l’homogénéisation de l’existant et de la nouvelle approche, il faut rester pragmatique et savoir faire les bons choix aux bons moments.
On peut aussi en venir à parler de "Cloud Ready Application", qui est un terme non-officiel mais désigne simplement une application, ou un ensemble de services existants, qu’on aura simplement traité de manière à les pousser sur notre nouvelle infrastructure. Ces applications ne bénéficient pas forcément de tous les avantages de notre nouvelle plateforme (Kubernetes managé, Kubernetes on-premise, …) mais elles s’y adaptent et peuvent y être déployées tout en minimisant les coûts de refactorisation.
On peut par exemple prendre un service parfois un peu gros d’une architecture orientée SOA, et aller vers le strict minimum :
De même, si nous avons un service assez vieillissant et qui est stateful, il faudra faire attention car certaines choses ne seront pas possibles nativement et simplement (la mise à l’échelle au niveau horizontale sera alors très complexe, et peut-être donc qu’il faudra faire ce sacrifice, n’avoir qu’une unique instance)
Nous sommes bien évidemment là sur une liste très minimaliste, ce qui aura évidemment des implications sur l’élasticité des ressources et la forme de communication possible avec ce composant.
Je me suis décidé et je veux migrer mon monolithe des années 2000, qui a beaucoup évolué depuis et fait maintenant des millions de lignes de code, en une Cloud Native Application, comment dois-je m’y prendre ?
Pensez d’ores et déjà à quelle proportion vous voulez changer. Vous allez devoir réécrire des choses, et on ne va pas se mentir, le voyage sera long.
Pensez aussi à ce que vous souhaitez (ou ce que vous avez d’accessible) :
Voici une liste, non exhaustive, de points à considérer pour migrer vers une architecture cloud Native:
Durant le processus de restructuration de votre architecture, il est très important de valider au fur et à mesure les différentes évolutions, du mieux possible. Si vous n’avez pas de tests de bout en bout, c’est le moment d’en créer, avant de commencer (qu’ils soient manuels ou automatiques, il faut pouvoir s’assurer de la non-régression – bien évidemment des tests automatisés sont grandement préférables). Bien entendu vous pouvez commencer par un premier scope (le premier microservice que vous allez extraire) puis continuer en parallélisant avec les différentes migrations.
Identifiez les différents microservices qui devraient exister, et si vous avez des besoins ponctuels, ce qui devrait être en serverless – attention toutefois à ce que votre use-case corresponde vraiment à du serverless, un article de blog sera aussi prochainement disponible sur ce sujet.
Identifiez les différents flux qui doivent alors exister dans ce nouveau monde, entre vos microservices, et entre votre système applicatif et le monde extérieur
Identifiez les ressources que vous pourriez utiliser dans votre Cloud
Identifiez comment reconstruire la base de votre infrastructure de manière autonome, facilement reproductible
Implémenter l’infrastructure en IaC
Terraform et Ansible sont souvent vos alliés pour cela
Déployer l’infrastructure – on considère ici l’infrastructure au sens large :
Choisissez la stack technologique pour votre premier microservice : maintenant il va falloir déployer un premier microservice, et donc le "détacher" du monolithe. Prenez les choses simples en premier, et ne viser pas d’extraire tout le module sous forme de microservice, commencez par une fonctionnalité simple.
Choisissez le langage en fonction de votre module, ne cherchez pas nécessairement à tout implémenter dans le même langage, ce n’est absolument pas le but d’une telle architecture. Pensez en terme de besoin de performances, de connaissances internes à votre équipe, et de la consommation que peut engendrer tel ou tel langage, particulièrement si vous êtes dans un Cloud public (l’utilisation excessive de vCPU ou de mémoire par certains langages en fait parfois des langages à écarter).
Choisissez la première fonctionnalité à migrer
Nous allons maintenant nous intéresser à la sécurisation des APIs, jusqu’ici ignorée volontairement. La première chose est d’identifier quel type d’authentification vous utilisiez jusque-là pour les utilisateurs et les services. vous souhaitez peut-être migrer votre mécanisme d’authentification, et vous avez pour l’instant le monolithe qui fait office de passe-plat entre le frontend et votre microservice. Il faut donc que l’ancienne application, le monolithe, puisse vous faire suivre les informations de l’utilisateur et soit "transparent" afin de vous permettre dans le nouveau module de valider si l’utilisateur a les droits pour accéder à telle ou telle fonction. Nous ne rentrons pas ici dans les détails de l’implémentation, mais ceci est réalisable en appelant (par exemple) votre provider oAuth avec les informations utilisateur afin de récupérer un jeton JWT et le transférer au microservice.
Une fois cet ajout de RBAC dans les fonctionnalités passe-plat du monolithe réalisé, vous pouvez ajouter les autorisations nécessaires à chaque API.
Déployez maintenant votre microservice dans un environnement stable mais pas encore en production, puis votre version du monolithe qui prend en charge les communications avec celui-ci
Testez, et retestez. Ne lésinez pas sur cet aspect, le succès de votre migration dépend de la qualité de vos tests, et votre nouvelle architecture ne sera adoptée et appréciée que si vous minimisez le risque de régression au maximum.
Passez à une nouvelle fonctionnalité à partir du point 8, puis une autre, jusqu’à avoir complètement fini avec ce premier microservice.
Déployez en production votre nouveau microservice, puis votre nouvelle version du monolithe.
Réitérez à partir du point 7 pour chaque microservice.
Faites en sorte que votre frontend passe directement (ou indirectement si vous avez une API Gateway) par vos nouveaux microservices, sans avoir besoin du passe-plat. Lors de cette étape vous devrez potentiellement implémenter le lien entre votre frontend et votre oAuth Provider afin de fournir le jeton JWT aux différents services backend sans passer par le monolithe.
Bien entendu, si vous souhaitez commencer à paralléliser la mise en place de microservices parce que vous en avez la capacité et que votre degré de maturité sur ce type de migration est suffisamment élevé, vous pouvez. Ici nous avons pris l’exemple ou nous partirions de zéro, et il va de soi alors qu’un premier microservice doit être fait sans chercher à paralléliser, pour "se mettre dans le bain".
Migrer vers du Cloud Native n’est pas toujours évident, et il faut donc mesurer le pour et le contre, se poser la question de ce qu’on doit migrer en Cloud Native Applications et ce qu’on va adapter pour faire de certains composants des Cloud Ready Applications.
Il faut bien comprendre que si toute cette architecture s’inspire des bonnes pratiques du Cloud, faire un tel effort est aussi très utile en cas d’infrastructure on-premise. Ceci vous permettra d’aller vers le monde des conteneurs, peut-être en partie dans le Cloud, parfois même d’utiliser des technologies comme le serverless à bon escient pour pouvoir économiser vos ressources là où c’est possible. Vous bénéficierez alors d’une mise à l’échelle en adéquation avec vos besoins, et d’une amélioration du temps de mise sur le marché pour vos nouvelles fonctionnalités, tout en rendant votre produit plus fiable.
Si vous souhaitez plonger plus en profondeur dans ce vaste sujet, SoKube fournit une formation Cloud Native Applications.
Les prochains articles de cette série sur les applications Cloud Native tourneront autour de différents services Mesh, et le premier sera disponible d’ici fin Juin, restez connectés!