
By Maxime Ancellin, Romain Boulanger & Yann Albou
Une édition enrichissante, la KubeCon + CloudNativeCon Europe 2025 à Londres a montré un cloud‑native arrivé à maturité : Kubernetes gère encore mieux les GPU, tandis qu’OpenTelemetry, GitOps et le platform engineering s’imposent comme standards de facto.
Ce blog propose de revenir sur ces tendances majeures, décrypter les chiffres clés et tirer les leçons d’une conférence qui montre un écosystème à la fois mature, innovant et résolument tourné vers un futur
Les sujets abordés sont les suivants:
La KubeCon + CloudNativeCon Europe 2025 s’est tenue à Londres du 17 au 19 avril, rassemblant plus de 12 500 participants passionnés par l’écosystème cloud natif. Cette édition a mis en lumière plusieurs thématiques majeures qui façonnent l’avenir du cloud computing :
Fait notable, bien que Kubernetes reste le socle technologique de référence, les discussions ont largement dépassé les aspects purement techniques pour aborder des problématiques plus larges d’architecture, de gouvernance et d’adoption.
Les replays de la conférence sont disponibles sur la chaîne YouTube officielle de la CNCF
Des chiffres toujours plus élevés, avec plus de 12 500 participants, 459 session et des centaines d’heures de conférences.

Les maintainers track sur les produits de la CNCF remportent le plus de succès avec 84 Sessions soit 18.3% du total.
Il est toujours intéressant de voir aussi les statistiques des mots clés du programme de cette édition ainsi que les sociétés les plus citées:
| # | Mots clés | # | Sociétés |
|---|---|---|---|
| 1 | Kubernetes/k8s (634) | 1 | Google (56) |
| 2 | Security (197) | 2 | Red Hat (41) |
| 3 | Observability (129) | 3 | Microsoft (22) |
| 4 | OpenTelemetry/OTel (75) | 4 | NVIDIA (19) |
| 5 | Platform Engineering (64) | 5 | AWS (16) |
| 6 | CI (44) | 6 | IBM (14) |
| 7 | Prometheus (41) | 7 | Datadog (13) |
| 8 | WASM (37) | 8 | Crossplane (12) |
| 9 | Mesh (35) | 9 | Cisco (11) |
| 10 | Gateway API (33) | 10 | Isovalent (10) |
| 11 | Envoy (27) | 11 | Dynatrace (8) |
| 12 | eBPF (26) | 12 | Huawei (8) |
| 13 | Helm (25) | 13 | Grafana Labs (8) |
| 14 | CD (25) | 14 | SUSE (8) |
| 15 | Istio (21) | 15 | VMware (8) |
| 16 | CAPI/Cluster API (21) | 16 | Solo.io (6) |
| 17 | Grafana (19) | 17 | Buoyant (5) |
| 18 | Argo (18) | 18 | Intel (5) |
| 19 | Flux (17) | 19 | JFrog (4) |
| 20 | AWS (16) | 20 | Oracle (4) |
| 21 | Multicluster (16) | 21 | Mirantis (3) |
| 22 | Backstage (15) | 22 | Confluent (1) |
| 23 | Docker (14) | 23 | F5 (1) |
| 24 | Chaos (14) | 24 | Loft (1) |
Le Programme est bien étudié et représente un clairement les tendances et les acteurs principaux.
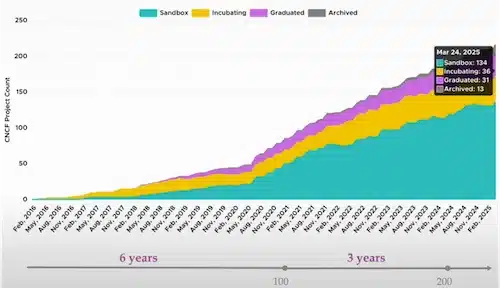
Nous avons pu constater que certains standards de la Cloud Native Computing Foundation (CNCF) sont devenus incontournables dans le monde du cloud native:
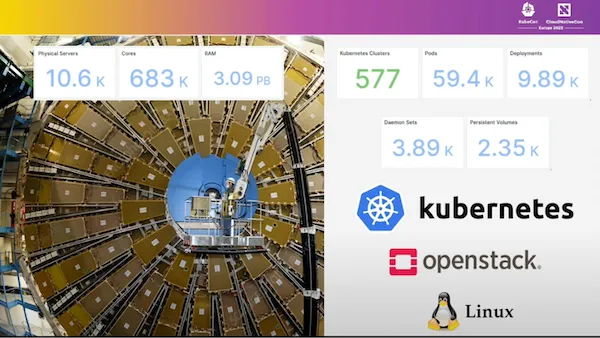
Avec ce genre de volumétrie (prêt de 600 Clusters Kubernetes, 60 000 pods, 2 500 persistent volumes, …) on ne peu plus douter que Kubernetes est capable de gérer des charges de travail à l’échelle !!!
La CNCF a annoncé les prochaines éditions de la KubeCon, avec notamment la confirmation des événements européens pour 2026 et 2027.
Un moment historique approche également avec la toute première KubeCon India qui se tiendra en août, marquant ainsi l’expansion continue et l’internationalisation croissante de la CNCF qui ne cesse de renforcer sa présence mondiale.
Même si cela n’a pas été mentionné par la CNCF, il faut espérer que la KubeCon LATAM (une communauté très active dans le monde Cloud Native) pourra compléter la liste (NA, EMEA, India, China). Merci au Corsair d’avoir porté cette information à notre attention.

La CNCF a annoncé l’évolution de son programme de certification Kubestronaut, qui récompense les professionnels ayant obtenu les principales certifications Kubernetes. Le titre de Kubestronaut est décerné aux personnes détenant les certifications CKA (Certified Kubernetes Administrator), CKAD (Certified Kubernetes Application Developer), CKS (Certified Kubernetes Security Specialist), KCNA (Kubernetes and Cloud Native Associate) et KCSA (Kubernetes and Cloud Native Security Associate).
Un nouveau niveau, le Golden Kubestronaut, a également été introduit pour reconnaître les experts qui possèdent non seulement toutes les certifications Kubestronaut, mais aussi l’ensemble des autres certifications CNCF ainsi que la certification LFCS (Linux Foundation Certified System Administrator). Ce programme vise à valoriser l’expertise approfondie dans l’écosystème cloud native et à encourager le développement professionnel continu dans ce domaine.
Plus d’informations sur le site de la CNCF : https://www.cncf.io/training/kubestronaut/

La Fondation Open Infrastructure (OpenInfra) a annoncé son rapprochement avec la Linux Foundation (LF), l’organisation mère de la CNCF. Cette fusion stratégique va permettre d’enrichir l’écosystème LF et CNCF avec de nouveaux projets majeurs. Parmi les projets notables qui rejoindront cet écosystème, on peut notamment citer OpenStack, la plateforme de cloud computing open source, ainsi que Kata Containers, le projet de conteneurs sécurisés. Cette consolidation renforce la position de la Linux Foundation comme acteur central de l’open source dans le domaine du cloud et des infrastructures.
L’initiative NeoNephos, soutenue par l’Union Européenne, représente une avancée majeure dans la quête de souveraineté numérique européenne. Ce projet ambitieux vise à créer une infrastructure cloud européenne basée sur les technologies open source, en particulier celles issues de la CNCF. L’objectif est de réduire la dépendance aux fournisseurs non-européens tout en garantissant un haut niveau de sécurité et de confidentialité des données. L’Union Européenne a démontré son engagement en investissant massivement dans ce projet stratégique, qui s’inscrit dans le cadre plus large de sa stratégie numérique. Cette initiative illustre parfaitement la volonté européenne de développer ses propres solutions cloud tout en restant alignée avec les standards internationaux de l’industrie.
La CNCF a annoncé que Headlamp deviendra l’interface graphique officielle de Kubernetes. Ce projet, toujours en développement actif au sein de la communauté, offre une interface web moderne et intuitive pour la gestion des clusters Kubernetes. Sa conception modulaire permet l’ajout d’extensions et de plugins pour étendre ses fonctionnalités selon les besoins spécifiques des utilisateurs.
Cette décision marque une étape importante dans la standardisation des outils de gestion visuelle pour Kubernetes.
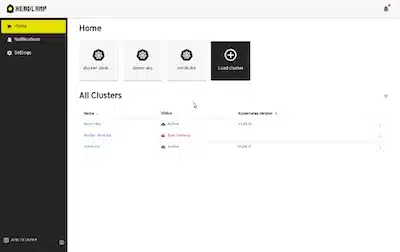
Une démo est disponible dans ce repo Github : Headlamp Demo
Lors de sa keynote « Rust in the Linux Kernel: A New Era for Cloud-Native Performance and Security », Greg Kroah-Hartman a souligné que le noyau Linux comporte désormais environ 25 000 lignes de Rust — une goutte d’eau face aux 34 millions de lignes C, mais déjà suffisante pour prouver que la mémoire sûre de Rust élimine toute une classe de bogues et permet au noyau de tomber de façon contrôlée plutôt que de corrompre la RAM.
Au-delà du gain technique, l’enjeu majeur est culturel : après trente ans de monoculture C, accepter un second langage bouscule les méthodes de revue, les chaînes d’outillage et même les valeurs des mainteneurs, certains voyant dans Rust une opportunité de moderniser le projet, d’autres redoutant un éclatement des efforts.
Autrement dit, introduire Rust dans le kernel, c’est moins remplacer du code que faire évoluer les mentalités et la gouvernance vers un modèle où sécurité par conception et collaboration multi-langages deviennent la norme.

Désormais deuxième projet le plus actif de la CNCF derrière Kubernetes, OpenTelemetry est né de la fusion stratégique d’OpenTracing et OpenCensus, d’abord incubée en Sandbox avant de gravir les échelons de la fondation. Véritable boîte à outils unifiée, il fournit des API et SDK cohérents pour générer métriques, logs et traces au sein d’une même sémantique, puis les exporter vers n’importe quel back-end (Prometheus, Grafana, Jaeger, Tempo, etc.).
Une nouveauté importante est l’auto-instrumentation : quelques bibliothèques suffisent pour que vos applications Java, .NET, Go, Python ou Node capturent automatiquement latence, erreurs et contextes distribués, réduisant à la fois le temps d’intégration et la dette d’observabilité.
En normalisant la collecte et le transport des signaux, OpenTelemetry s’impose comme le standard de facto de l’observabilité cloud-native, catalysant une approche “mesurer d’abord, optimiser ensuite” indispensable aux architectures Kubernetes modernes.

Nouveau projet accepté en Sandbox par la CNCF, Perses se présente comme un “dashboard-as-code” natif Kubernetes :
Cette approche “as-code” réduit la dérive entre environnements, facilite les revues et fait de Perses un complément GitOps-friendly à l’écosystème observabilité, un concurrent standard et sérieux face à Grafana.
Voici maintenant les thématiques principales de la kubecon 2025:
Objectif : permettre à un Pod de réclamer dynamiquement une ressource rare ou critique (GPU, FPGA, licence logicielle, clef USB-HSM, etc.) et de ne démarrer que lorsqu’elle est réellement disponible, en ré-utilisant les mêmes schémas déclaratifs que les Volumes Persistants.
| Terme DRA | Rôle | Équivalent « volume » |
|---|---|---|
ResourceClaimTemplate |
Gabarit générant un ou plusieurs ResourceClaim par Pod |
PersistentVolumeClaimTemplate |
ResourceClaim |
Demande d’accès à une ressource précise | PersistentVolumeClaim |
DeviceClass |
Catégorie (critères + config) d’un type de périphérique | StorageClass |
ResourceSlice |
Inventaire dynamique des ressources exposé par un driver sur chaque nœud | inventaire CSI |
DeviceTaintRule |
Règle pour « tainter » un périphérique et en restreindre l’usage | Taint/Toleration pour les nœuds |
apiVersion: v1
kind: Pod
metadata:
name: gpu-inference
spec:
resourceClaims:
- name: gpu-needed
containers:
- name: infer
image: nvcr.io/myorg/llm:latest
resources:
limits:
nvidia.com/gpu: 1
---
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaimTemplate
metadata:
name: gpu-needed
spec:
deviceClass: nvidia-a100 # défini côté clusterapiVersion: apps/v1
kind: Deployment
metadata:
name: matlab-workers
spec:
replicas: 5
template:
spec:
resourceClaims:
- name: matlab-license
containers:
- name: worker
image: registry.company.com/matlab-job:2025
---
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaim
metadata:
name: matlab-license
spec:
deviceClass: ml-license
parameters:
seats: "1" # seat-based licensingLe driver met à jour dynamiquement les ResourceSlice pour refléter le nombre de licences encore libres ; le scheduler n’alloue celles-ci qu’aux Pods pouvant vraiment l’utiliser, évitant les échecs « licence unavailable ».
Pourquoi Dynamic Resource Allocation (DRA) quand le scheduler gère déjà CPU/Mémoire ?
Le scheduler natif prend ses décisions en fonction de deux ressources “intégrées” : le CPU (millicores) et la mémoire (MiB/GiB), qu’il voit comme de simples compteurs sur chaque nœud. Cela suffit pour des ressources uniformes, toujours présentes et dont la disponibilité se résume à un nombre libre ou occupé. Mais dès qu’on parle de GPU, FPGA, licences logicielles, HSM USB, ports série, etc., on sort de ce modèle.
En pratique, le scheduler classique ne fait que “compter” des CPU et de la RAM toujours attachés au nœud, alors que DRA ajoute un véritable plan de contrôle pour les ressources rares, hétérogènes ou mutualisées : un Pod déclare un ResourceClaim fondé sur une DeviceClass (GPU A100, licence MATLAB, FPGA…), le pilote publie en temps réel son inventaire via des ResourceSlices, et le Pod ne démarre que lorsque la ressource exacte est confirmée. Ce mécanisme apporte ce qui manque au modèle CPU/Mémoire : des paramètres riches (vendor, seats, modèle), des règles de taint/toleration au niveau du périphérique, une mise à jour dynamique de la disponibilité et surtout la garantie qu’un démarrage n’échouera plus faute de matériel ou de licence à l’exécution. Autrement dit, DRA complète le scheduler en lui offrant la granularité, la validation et la gouvernance nécessaires aux “ressources spéciales” que le simple comptage de millicores et de méga-octets ne pourra jamais représenter de manière fiable.
Du coup on peut se poser la question de l’utilisation de DRA vs Affinity/Anti-Affinity
En résumé, DRA étend l’ADN déclaratif de Kubernetes à tout ce qui dépasse le simple CPU-RAM : vous décrivez le besoin, le cluster orchestre l’allocation, retardant le démarrage si nécessaire plutôt que d’échouer à mi-parcours – un pas de plus vers un scheduler réellement « resource-aware ».
Ce repository Github de Kubernetes contient des exemples de configuration DRA et montre via un projet de test le fonctionnement de DRA:
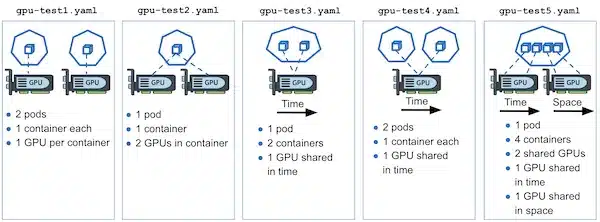
Cluster API (CAPI) n’est plus un projet de niche : sous l’égide du SIG cluster-api, il vient de sortir en version v 1.9.6 et s’impose comme la façon la plus propre de déclarer, créer, mettre à jour et démanteler des clusters Kubernetes à l’aide des mêmes manifestes YAML que pour vos déploiements applicatifs
Concrètement, on décrit un cluster cible (control-plane, workers, réseau) puis on laisse une armée de contrôleurs piloter la création sur n’importe quelle infrastructure et typèe de Control Plane — AWS, Azure, vSphere, Proxmox, Talos, RKE2, etc.
Cette approche « cluster-as-code » s’accorde naturellement avec GitOps : Une PR suivi d’un merge dans le repo et votre nouveau cluster apparaît (ou disparaît) sans scripts Ansible.
Un projet vivant et extrêmement actif dans lequel on compte désormais des dizaines de providers officiels et un rythme de publication soutenu, gage de pérennité et de réactivité face aux CVE ou aux différentes évolutions.
Témoignages concrets : Michelin et PostFinance
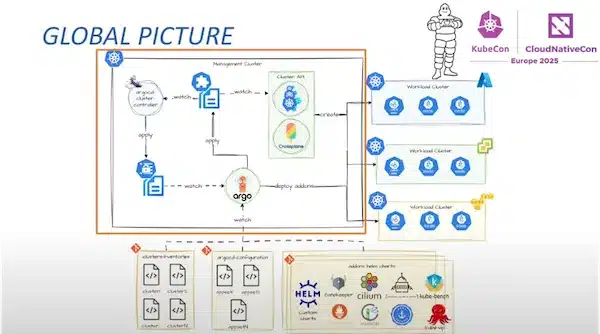

Exemple partiel de la description d’un cluster CAPI:
# L’objet Cluster (CAPI) référence l’infrastructure (ProxmoxCluster) et le control plane (RKE2ControlPlane).
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: dev-rke2-cluster
namespace: default
spec:
clusterNetwork:
pods:
cidrBlocks:
- 172.18.0.0/16
services:
cidrBlocks:
- 172.19.0.0/16
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: ProxmoxCluster
name: dev-rke2-cluster
controlPlaneRef:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: RKE2ControlPlane
name: dev-master
---
# Le RKE2ControlPlane décrit la configuration RKE2 (version, paramètres, etc.) et référence la ProxmoxMachineTemplate pour les nœuds control-plane.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: RKE2ControlPlane
metadata:
name: dev-master
namespace: default
spec:
clusterName: dev-rke2-cluster
replicas: 1
rolloutStrategy:
default:
rollingUpdate:
maxSurge: 1
type: RollingUpdate
version: v1.31.5+rke2r1
# enableContainerdSelinux: true # Active le support SELinux pour containerd
serverConfig:
# On veut cilium (=> on désactive canal).
# keepalived est également désactivé
disableComponents:
kubernetesComponents:
- cloudController
# - rke2-canal
# - rke2-keepalived
# - rke2-kube-proxy
cni:
# ou calico, canal, etc. si vous voulez un autre plugin
- cilium
# ....
machineTemplate:
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: ProxmoxMachineTemplate
name: rke2-master-template
nodeDrainTimeout: 2mCet exemple partiel qui décrit comment déployer un cluster kubernetes, combiné avec l’approche GitOps, permet de gérer un cluster en devenant indépendant de l’outil de provisionning et en bénéficiant d’un cycle de vie automatisé avec un workflow de type PR/merge identique à celui utilisé pour les applications.
En conclusion, bien que la Cluster API ne soit pas nouvelle, elle atteint aujourd’hui une réelle maturité avec des retours d’expérience concrets comme celui de Michelin qui gère 62 clusters en production. CAPI apporte enfin la couche « cycle de vie » qui manquait : une API Kubernetes pour gérer… des Kubernetes. Que vous exploitiez 3 clusters de test ou des dizaines en production, CAPI transforme la création et la maintenance de clusters en simples opérations Git, réduisant drastiquement la dette d’automatisation et la dépendance aux outils propriétaires. Cependant, il est important de noter que l’adoption de CAPI nécessite un temps d’apprentissage et une bonne compréhension de son fonctionnement pour en tirer pleinement parti.
Dans un monde multi-cluster, il ne s’agit plus seulement d’exploiter plusieurs instances Kubernetes : il faut qu’elles coopèrent pour offrir la fault-tolerance, rapprocher les données des utilisateurs, appliquer des politiques globales, équilibrer la capacité et, parfois, chasser les meilleures performances.
Le SIG Multicluster définit déjà une grammaire commune :
L’objectif rejoint celui d’un cluster mesh : exposer un service unique derrière plusieurs clusters et router les requêtes au plus proche ou au plus disponible, tout en maintenant des contrôles réseau/sécurité cohérents.
Cluster API (CAPI) reste complémentaire : il gère le cycle de vie (création, mise à jour, suppression) des clusters eux-mêmes, alors que SIG Multicluster orchestre leur interconnexion et la distribution du trafic ou des workloads.
En clair, CAPI construit la flotte, le SIG Multicluster lui donne un cerveau collectif — un vaste chantier en cours, mais déjà indispensable pour les organisations qui visent la haute disponibilité planétaire ou la résidence des données par juridiction.
La question qu’on se pose alors est : faut-il bâtir un gigantesque cluster Kubernetes, ou bien diviser la charge entre plusieurs clusters plus petits ?
c’est ce que la conférence A Huge Cluster or Multi-Clusters? Identifying the Bottleneck essaie de répondre.
Il existe dans kubernetes des limites pratiques connues du projet (ex. 110 pods par nœud, 5 000 nœuds max) et les goulots d’étranglement classiques : API server, ETCD, DNS, stockage, ou encore la gestion fine des nœuds…
Mais quelles sont les bonnes pratiques pour choisir entre un gros cluster ou plusieurs petits ?
Il n’y a pas de solution unique — tout dépend des priorités.
Si la priorité est l’efficacité à grande échelle et la gouvernance centrale, un gros cluster peut suffire (tant que vous maîtrisez les limites techniques).
Mais si vous visez l’autonomie des équipes, la sécurité renforcée ou l’hétérogénéité des usages, la stratégie multi-clusters est plus adaptée… à condition de disposer des bons outils pour l’orchestrer (CAPI, IDP, observabilité distribuée, etc.).
Mais pourquoi pas aller vers des solutions intermédiaire en faisant du Multi-tenancy via du « Kubernetes-in-Kubernetes » ?

L’approche multi-tenancy dans Kubernetes ne se limite pas à créer des namespaces. L’écosystème propose aujourd’hui un éventail d’outils pour virtualiser ou partitionner des environnements Kubernetes — allant du plus léger (shared-namespaces) au plus isolé (clusters dédiés). On parle souvent de Kubernetes-in-Kubernetes, car certains outils permettent de faire tourner des “pseudo-clusters” à l’intérieur d’un cluster principal. Voici les principales approches classées du plus simple au plus complexe :
Ce qu’il faut retenir :
La NetworkPolicy v1 (standard Kubernetes) reste encore largement utilisée. Elle permet, comme dans l’exemple ci-dessous, de restreindre les communications entre Pods via des labels et des ports TCP :
# Exemple : autoriser uniquement les pods "frontend" à parler aux "backend" sur le port 6379
kind: NetworkPolicy
metadata:
name: netpolv1
namespace: sokube
spec:
podSelector:
matchLabels:
role: backend
policyTypes:
- Ingress
- Egress
ingress:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379Mais ce modèle reste limité :
De nouvelles générations apparaissent : Admin & Baseline Policies
Des CRDs avancés, comme BaselineAdminNetworkPolicy, permettent d’exprimer des politiques globales ou par namespace, avec un vrai filtrage en “deny” explicite, utile pour sécuriser les environnements dès le départ :
# Exemple : refuser tout trafic inter-namespace (par défaut)
kind: BaselineAdminNetworkPolicy
metadata:
name: default-deny
spec:
subject:
namespaces: {}
ingress:
- name: "default-deny"
action: "Deny"
from:
- namespaces: {}
egress:
- name: "default-deny"
action: "Deny"
to:
- namespaces: {}Et demain : filtrage L7 et identités
Avec Istio et les Service Mesh, on monte encore d’un cran : les AuthorizationPolicy permettent de filtrer non plus sur des IP ou labels, mais sur :
# Exemple : autoriser uniquement GET sur /siliconchalet/events depuis un SA spécifique
kind: AuthorizationPolicy
metadata:
name: sokube
namespace: siliconchalet
spec:
action: ALLOW
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/sokube"]
to:
- operation:
methods: ["GET"]
paths: ["/siliconchalet/events"]La sécurité réseau dans Kubernetes évolue de la simple isolation de pods (NetworkPolicy v1) vers des règles globales ou admin via des CRDs (Baseline/ANP), jusqu’au filtrage intelligent basé sur les identités et la couche 7 avec les service mesh comme Istio.
Mais beaucoup de travail reste à faire: standardisation, portabilité entre CNI, et intégration avec des contrôles d’accès plus riches. Certains posent déjà la question : la NetworkPolicy pourrait-elle devenir la future Gateway API de la sécurité réseau ? Un cadre unifié, extensible, intégrant L3 → L7 et s’alignant avec l’évolution vers le Zero Trust.
Une démo est disponible dans ce repo Github : NetworkPolicy Demo
OpenTelemetry est en train de devenir le standard universel de l’observabilité dans l’écosystème cloud-native. Une de ses forces clés : la capacité d’auto-instrumentation, sans avoir à modifier le code de l’application.
Fonctionnement (exemple) : On déclare un objet Instrumentation Kubernetes comme ci-dessous :
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: demo-instrumentation
spec:
exporter:
endpoint: http://trace-collector:4318
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"Cela suffit à injecter automatiquement des traceurs dans les applications supportées.
Points clés :
En résumé : on déploie, on annote, on trace !
Une démo est disponible dans ce repo Github : OpenTelemetry Demo
Face à la multitude de données observables (traces, logs, métriques) et leur volume croissant, identifier une panne ou un goulet d’étranglement devient un véritable défi.
L’IA entre ici en scène non pas pour remplacer l’humain, mais pour pré-analyser et résumer les signaux clés.
Les défis actuels :
La bonne approche : des agents spécialisés plutôt qu’un chatbot générique.
MonstorService/Get avec 100% de la latence concentrée).TimeoutException, ici), corrélées aux traces.
Résultat observé (exemple réel) :
En résumé, l’observabilité moderne est un travail de data engineering, et donc il y a quand même des points essentiels à maîtriser :
Ce n’est pas “branchement d’un LLM = magie”, mais bien une automatisation ciblée, sur des briques normalisées.
Les LLMs sont partout, mais une fois la démo passée, beaucoup tombent de haut : lenteur, réponses incohérentes, coûts qui explosent… car construire une application basée sur un modèle de langage ne ressemble en rien au développement logiciel classique.
La solution : L’observabilité devient la clé.
“Les LLMs ajoutent de la magie, mais aussi beaucoup d’incertitude.
L’observabilité est ce qui transforme cette magie en produit fiable.”
Comme l’a résumé Christine Yen dans « Observability in the Age of LLMs« , le vrai défi n’est pas d’avoir un modèle, mais de le maintenir en production, en le comprenant vraiment — à travers ce qu’il fait, pas ce qu’on attendait.
Voir la conférence complète → Production-Ready LLMs on Kubernetes
Avec la montée en puissance des modèles open source, héberger un LLM sur Kubernetes devient une option viable pour de nombreuses entreprises. Cela répond à plusieurs enjeux :
Pour démarrer : Ollama + Open WebUI
Oui, mais… les LLMs sont gourmands !
Problèmes majeurs :
Résultat : les GPU saturent vite — même un A100 peut suffoquer si le contexte est trop long.
Des solutions émergent : vLLM à la rescousse
Pour faire entrer de grands modèles dans de petites configs, des projets comme vLLM introduisent des optimisations majeures :
Résultat : 2 à 4 fois plus de capacité GPU, sans nouveau matériel, avec les bons flags ou un build optimisé vLLM + FlashAttention.

A noter qu’il existe des initiatives comme AISpec.org qui cherchent à formaliser des CRDs pour décrire les workloads AI — à l’image de ce que Helm ou Kustomize font pour les apps traditionnelles.
Kubernetes s’impose peu à peu comme la plateforme idéale pour exécuter des architectures agentiques, où des agents IA autonomes collaborent, dialoguent avec des APIs et orchestrent des tâches complexes.
Pour cela Solo.io a annoncé plusieurs projets: Kgateway, MCP Gateway qui fait partie du projet Kgateway et Kagent
Kgateway : une Gateway API pour l’IA : Il s’appuie sur le standard Kubernetes Gateway API, adapté au trafic IA :
MCP (Model Context Protocol) Gateway :
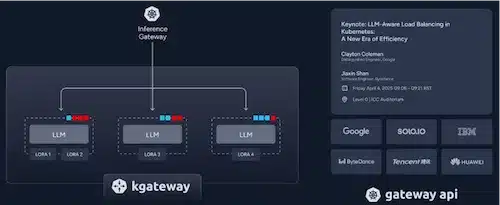
Enfin, Kagent est un framework open-source pour agents IA sur Kubernetes qui permet :
Voir la vidéo Why Kubernetes Will Become the Platform of Choice for Agentic Architectures
Kubernetes souhaite clairement devenir la plateforme de référence pour exécuter les LLMs, comme l’a résumé Clayton Coleman avec la formule :
“LLMs is the new Web App”
Mais ces modèles ne se gèrent pas comme une simple API REST : ils sont gourmands en ressources, nécessitent des GPU, des optimisations mémoire, et une approche différente du cycle de vie (observabilité, tests par évaluation, déploiement rapide). Que ce soit on-premise (pour la souveraineté et la confidentialité) ou dans le cloud, Kubernetes continue d’évoluer pour intégrer ces nouveaux usages, tout en restant compatible avec les pratiques DevSecOps : sécurité native, CI/CD, observabilité, et gouvernance. Les outils cités ci-dessus montrent que l’écosystème IA se structure à l’image de ce qu’a été le web pour Kubernetes… en beaucoup plus exigeant.
Le Platform Engineering s’impose en 2025 comme une pratique structurée et largement adoptée dans les entreprises pour offrir des environnements self-service centralisés, fiables et sécurisés.
Voir notre article sur le sujet : DevOps et Platform Engineering: efficacité et scalabilité de votre IT

Tendances marquantes sur le Platform Engineering :
Deux témoignages ont particulièrement retenu l’attention, illustrant comment le Platform Engineering peut transformer à la fois l’expérience développeur et la sécurité à l’échelle.
LEGO a présenté sa nouvelle plateforme Kubernetes, pensée pour offrir une expérience fluide et cohérente, que ce soit on-premise ou dans le cloud. Leur approche est résolument structurée :
Mais surtout, LEGO met l’accent sur la gestion du changement avec une approche “vendeur” :
Leur mantra :
“Sell your platform”
“Keep your users close”
Ce second retour, centré sur la sécurité, propose un message clair :
Plutôt que de “shift-left” la sécurité vers les développeurs, intégrez-la dans la plateforme pour la rendre invisible et cohérente.
Les clés d’une plateforme sécurisée :
Recommandations :
En résumé :
“Shift down to the platform, instead of shifting left to the developer”
Adopter une culture de sécurité par le design, en mode « Platform-as-a-Product »
Voir la conférence complète : Platform Engineering Loves Security: Shift Down To Your Platform, Not Left To Your Developers!
Dans l’écosystème Kubernetes, un défi majeur concerne le gaspillage des ressources (CPU, mémoire, stockage et nœuds inadaptés), ce qui représente un enjeu FinOps important.
Pour répondre à cette problématique, une approche innovante consiste à détourner l’usage traditionnel d’OPA et Gatekeeper. Habituellement dédiés à la sécurité, ces outils peuvent être utilisés pour implémenter des politiques FinOps en langage Rego, appliquées directement lors de l’admission des objets dans le cluster. D’autres outils existent comme kyverno.
Cette stratégie permet de mettre en place plusieurs types de règles essentielles :
L’intégration avec OpenCost offre une visibilité en temps réel sur les métriques, tandis que l’audit continu et le mode « dry-run » permettent de sensibiliser les développeurs avant d’appliquer des restrictions strictes.
Les bénéfices de cette approche sont multiples : une meilleure visibilité budgétaire, une réduction pérenne des dépenses, et une gouvernance unifiée combinant sécurité et maîtrise des coûts dans un même cadre GitOps.
Voir la conférence complète : Beyond Security: Leveraging OPA for FinOps in Kubernetes

La KubeCon + CloudNativeCon Europe 2025 a confirmé que Kubernetes n’est plus un sujet “pionnier”, mais entre dans une nouvelle phase : plus de maturité, plus de cas d’usage, et surtout un passage à l’échelle sans précédent.
L’IA n’est plus une option : workloads LLM, agents et pipelines MLOps deviennent courants, et Kubernetes s’affirme comme la plateforme privilégiée pour les héberger, grâce à sa portabilité et à l’offre croissante d’outils GPU-aware.
Des patterns IA exigeants : gestion du contexte, partage fin des GPU, optimisations mémoire ; ces défis imposent une observabilité de haute précision pour suivre coûts, latence, dérives de qualité et respect des SLO.
Le Platform Engineering se généralise : les retours d’expérience prouvent qu’une plateforme opiniated, centralisée, sécurisée et standardisée est aujourd’hui le moyen le plus sûr de dompter cette complexité tout en servant les équipes produit en self-service.
En résumé, l’écosystème avance vers toujours plus de cas d’usage — IA en tête — à grande échelle. Cette montée en puissance s’accompagne toutefois d’une complexité accrue.
Le message de la KubeCon 2025 est clair : La maturité et l’innovation continue, mais la rigueur devient indispensable pour transformer Kubernetes en levier stratégique plutôt qu’en dette technologique.
23 thoughts on "Kubecon London 2025: IA, Observabilité et Platform Engineering"