
By Maxime Ancellin, Romain Boulanger & Yann Albou
An enriching edition, KubeCon + CloudNativeCon Europe 2025 in London showcased a cloud-native ecosystem that has reached maturity: Kubernetes manages GPUs even better, while OpenTelemetry, GitOps, and platform engineering have become de facto standards. This blog revisits these major trends, deciphers the key figures, and draws lessons from a conference that demonstrates an ecosystem that is both mature, innovative, and resolutely future-oriented.
The topics covered are the following:
KubeCon + CloudNativeCon Europe 2025 took place in London from April 17 to 19, bringing together more than 12,500 enthusiasts of the cloud-native ecosystem. This edition highlighted several major themes shaping the future of cloud computing:
Notably, although Kubernetes remains the reference technological foundation, discussions went far beyond purely technical aspects to address broader issues of architecture, governance, and adoption.
Replays of the conference are available on the official CNCF YouTube channel
Numbers keep rising, with over 12,500 participants, 459 sessions, and hundreds of hours of talks.

The CNCF product maintainers track is the most successful, with 84 sessions, representing 18.3% of the total.
It’s also interesting to look at the statistics of the program’s keywords for this edition, as well as the most mentioned companies:
| # | Keywords | # | Companies |
|---|---|---|---|
| 1 | Kubernetes/k8s (634) | 1 | Google (56) |
| 2 | Security (197) | 2 | Red Hat (41) |
| 3 | Observability (129) | 3 | Microsoft (22) |
| 4 | OpenTelemetry/OTel (75) | 4 | NVIDIA (19) |
| 5 | Platform Engineering (64) | 5 | AWS (16) |
| 6 | CI (44) | 6 | IBM (14) |
| 7 | Prometheus (41) | 7 | Datadog (13) |
| 8 | WASM (37) | 8 | Crossplane (12) |
| 9 | Mesh (35) | 9 | Cisco (11) |
| 10 | Gateway API (33) | 10 | Isovalent (10) |
| 11 | Envoy (27) | 11 | Dynatrace (8) |
| 12 | eBPF (26) | 12 | Huawei (8) |
| 13 | Helm (25) | 13 | Grafana Labs (8) |
| 14 | CD (25) | 14 | SUSE (8) |
| 15 | Istio (21) | 15 | VMware (8) |
| 16 | CAPI/Cluster API (21) | 16 | Solo.io (6) |
| 17 | Grafana (19) | 17 | Buoyant (5) |
| 18 | Argo (18) | 18 | Intel (5) |
| 19 | Flux (17) | 19 | JFrog (4) |
| 20 | AWS (16) | 20 | Oracle (4) |
| 21 | Multicluster (16) | 21 | Mirantis (3) |
| 22 | Backstage (15) | 22 | Confluent (1) |
| 23 | Docker (14) | 23 | F5 (1) |
| 24 | Chaos (14) | 24 | Loft (1) |
The program is well designed and clearly represents the trends and main players.
We have observed that certain standards from the Cloud Native Computing Foundation (CNCF) have become essential in the cloud-native world:
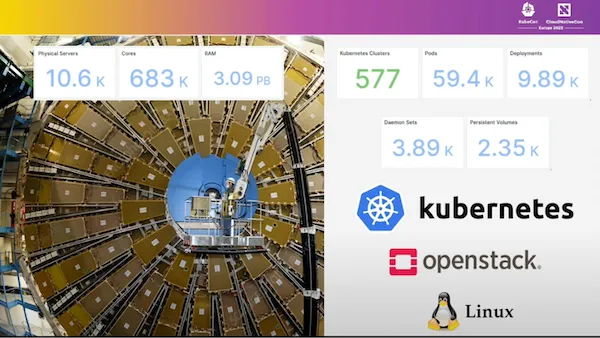
With this kind of volume (nearly 600 Kubernetes Clusters, 60,000 pods, 2,500 persistent volumes, …), there is no longer any doubt that Kubernetes can handle workloads at scale!
The CNCF has announced the next editions of KubeCon, including confirmation of European events for 2026 and 2027. A historic moment is also approaching with the very first KubeCon India to be held in August, marking the continued expansion and growing internationalization of the CNCF, which keeps strengthening its global presence.
Even though it was not mentioned by the CNCF, we hope that KubeCon LATAM (a very active community in the Cloud Native world) will complete the list (NA, EMEA, India, China). Thanks to Corsair for bringing this information to our attention.

The CNCF has announced the evolution of its Kubestronaut certification program, which rewards professionals who have obtained the main Kubernetes certifications. The title of Kubestronaut is awarded to those holding the CKA (Certified Kubernetes Administrator), CKAD (Certified Kubernetes Application Developer), CKS (Certified Kubernetes Security Specialist), KCNA (Kubernetes and Cloud Native Associate), and KCSA (Kubernetes and Cloud Native Security Associate) certifications.
A new level, the Golden Kubestronaut, has also been introduced to recognize experts who possess not only all the Kubestronaut certifications but also all other CNCF certifications as well as the LFCS (Linux Foundation Certified System Administrator) certification. This program aims to value deep expertise in the cloud-native ecosystem and encourage ongoing professional development in this field.
More information on the CNCF website: https://www.cncf.io/training/kubestronaut/

The Open Infrastructure Foundation (OpenInfra) has announced its merger with the Linux Foundation (LF), the parent organization of the CNCF. This strategic merger will enrich the LF and CNCF ecosystem with major new projects. Among the notable projects joining this ecosystem are OpenStack, the open source cloud computing platform, and Kata Containers, the secure containers project. This consolidation strengthens the Linux Foundation’s position as a central player in open source for cloud and infrastructure.
The NeoNephos initiative, supported by the European Union, represents a major step forward in the quest for European digital sovereignty. This ambitious project aims to create a European cloud infrastructure based on open source technologies, particularly those from the CNCF. The goal is to reduce dependence on non-European providers while ensuring a high level of security and data privacy. The European Union has demonstrated its commitment by investing heavily in this strategic project, which is part of its broader digital strategy. This initiative perfectly illustrates Europe’s desire to develop its own cloud solutions while remaining aligned with international industry standards.
The CNCF has announced that Headlamp will become the official graphical interface for Kubernetes. This project, still under active development within the community, offers a modern and intuitive web interface for managing Kubernetes clusters. Its modular design allows the addition of extensions and plugins to extend its features according to users’ specific needs. This decision marks an important step in standardizing visual management tools for Kubernetes.
A demo is available in this Github repo: Headlamp Demo
During his keynote “Rust in the Linux Kernel: A New Era for Cloud-Native Performance and Security“, Greg Kroah-Hartman pointed out that the Linux kernel now contains about 25,000 lines of Rust—a drop in the ocean compared to 34 million lines of C, but already enough to prove that Rust’s memory safety eliminates an entire class of bugs and allows the kernel to fail gracefully rather than corrupt RAM.
Beyond the technical gain, the major challenge is cultural: after thirty years of C monoculture, accepting a second language shakes up review methods, tooling chains, and even the values of maintainers, some seeing Rust as an opportunity to modernize the project, others fearing a fragmentation of efforts.
In other words, introducing Rust into the kernel is less about replacing code than about evolving mindsets and governance towards a model where security by design and multi-language collaboration become the norm.

Now the second most active project in the CNCF after Kubernetes, OpenTelemetry was born from the strategic merger of OpenTracing and OpenCensus, first incubated in the Sandbox before climbing the foundation’s ranks. A true unified toolbox, it provides consistent APIs and SDKs to generate metrics, logs, and traces within a single semantic, then export them to any backend (Prometheus, Grafana, Jaeger, Tempo, etc.).
A major innovation is auto-instrumentation: a few libraries are enough for your Java, .NET, Go, Python, or Node applications to automatically capture latency, errors, and distributed contexts, reducing both integration time and observability debt.
By standardizing the collection and transport of signals, OpenTelemetry is becoming the de facto standard for cloud-native observability, catalyzing a “measure first, optimize later” approach essential to modern Kubernetes architectures.

A new project accepted into the CNCF Sandbox, Perses presents itself as a Kubernetes-native “dashboard-as-code”:
This “as-code” approach reduces drift between environments, facilitates reviews, and makes Perses a GitOps-friendly complement to the observability ecosystem, a serious and standard competitor to Grafana.
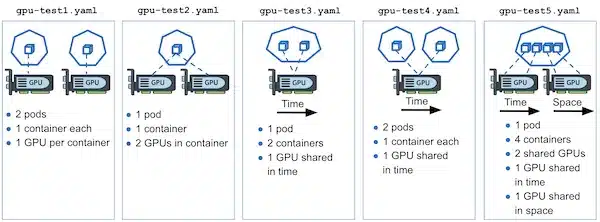
Objective: Allow a Pod to dynamically claim a rare or critical resource (GPU, FPGA, software license, USB-HSM key, etc.) and only start when it is actually available, reusing the same declarative patterns as Persistent Volumes.
| DRA Term | Role | “Volume” Equivalent |
|---|---|---|
ResourceClaimTemplate |
Template generating one or more ResourceClaim per Pod |
PersistentVolumeClaimTemplate |
ResourceClaim |
Request for access to a specific resource | PersistentVolumeClaim |
DeviceClass |
Category (criteria + config) of a device type | StorageClass |
ResourceSlice |
Dynamic inventory of resources exposed by a driver on each node | CSI inventory |
DeviceTaintRule |
Rule to “taint” a device and restrict its usage | Taint/Toleration for nodes |
apiVersion: v1
kind: Pod
metadata:
name: gpu-inference
spec:
resourceClaims:
- name: gpu-needed
containers:
- name: infer
image: nvcr.io/myorg/llm:latest
resources:
limits:
nvidia.com/gpu: 1
---
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaimTemplate
metadata:
name: gpu-needed
spec:
deviceClass: nvidia-a100 # defined at cluster levelapiVersion: apps/v1
kind: Deployment
metadata:
name: matlab-workers
spec:
replicas: 5
template:
spec:
resourceClaims:
- name: matlab-license
containers:
- name: worker
image: registry.company.com/matlab-job:2025
---
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaim
metadata:
name: matlab-license
spec:
deviceClass: ml-license
parameters:
seats: "1" # seat-based licensingThe driver dynamically updates the ResourceSlice to reflect the number of licenses still available; the scheduler only allocates them to Pods that can actually use them, avoiding “license unavailable” failures.
Why Dynamic Resource Allocation (DRA) when the scheduler already manages CPU/Memory?
The native scheduler makes its decisions based on two “built-in” resources: CPU (millicores) and memory (MiB/GiB), which it sees as simple counters on each node. This is sufficient for uniform resources, always present and whose availability is just a free/used count. But as soon as you talk about GPU, FPGA, software licenses, USB HSMs, serial ports, etc., you leave this model.
In practice, the classic scheduler only “counts” CPUs and RAM always attached to the node, whereas DRA adds a real control plane for rare, heterogeneous, or shared resources: a Pod declares a ResourceClaim based on a DeviceClass (GPU A100, MATLAB license, FPGA…), the driver publishes its inventory in real time via ResourceSlices, and the Pod only starts when the exact resource is confirmed. This mechanism brings what the CPU/Memory model lacks: rich parameters (vendor, seats, model), taint/toleration rules at the device level, dynamic availability updates, and above all the guarantee that a start will no longer fail due to missing hardware or license at runtime. In other words, DRA complements the scheduler by offering the granularity, validation, and governance needed for “special resources” that simple counting of millicores and megabytes can never reliably represent.
So, DRA vs Affinity/Anti-Affinity?
In summary, DRA extends Kubernetes’ declarative DNA to everything beyond simple CPU-RAM: you describe the need, the cluster orchestrates the allocation, delaying the start if necessary rather than failing mid-way—a step closer to a truly “resource-aware” scheduler.
This Kubernetes Github repository contains DRA configuration examples and shows via a test project how DRA works:
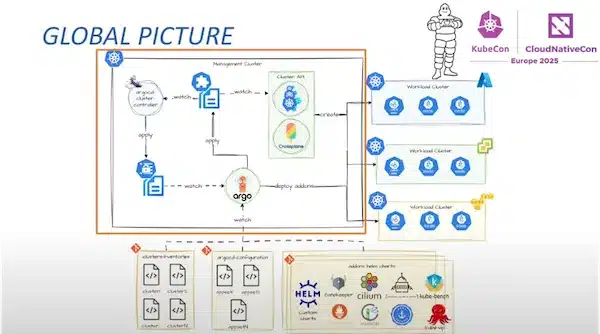
Cluster API (CAPI) is no longer a niche project: under the aegis of the SIG cluster-api, it has just been released in version v1.9.6 and is becoming the cleanest way to declare, create, update, and dismantle Kubernetes clusters using the same YAML manifests as for your application deployments.
Concretely, you describe a target cluster (control-plane, workers, network) and let a fleet of controllers handle creation on any infrastructure and type of Control Plane—AWS, Azure, vSphere, Proxmox, Talos, RKE2, etc.
This “cluster-as-code” approach naturally fits with GitOps: a PR followed by a merge in the repo and your new cluster appears (or disappears) without Ansible scripts.
A lively and extremely active project, now with dozens of official providers and a steady release pace, a sign of sustainability and responsiveness to CVEs or various evolutions.
Concrete feedback: Michelin and PostFinance

Partial example of a CAPI cluster description:
# The Cluster (CAPI) object references the infrastructure (ProxmoxCluster) and the control plane (RKE2ControlPlane).
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: dev-rke2-cluster
namespace: default
spec:
clusterNetwork:
pods:
cidrBlocks:
- 172.18.0.0/16
services:
cidrBlocks:
- 172.19.0.0/16
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: ProxmoxCluster
name: dev-rke2-cluster
controlPlaneRef:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: RKE2ControlPlane
name: dev-master
---
# The RKE2ControlPlane describes the RKE2 configuration (version, parameters, etc.) and references the ProxmoxMachineTemplate for control-plane nodes.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: RKE2ControlPlane
metadata:
name: dev-master
namespace: default
spec:
clusterName: dev-rke2-cluster
replicas: 1
rolloutStrategy:
default:
rollingUpdate:
maxSurge: 1
type: RollingUpdate
version: v1.31.5+rke2r1
# enableContainerdSelinux: true # Enable SELinux support for containerd
serverConfig:
# We want cilium (=> disable canal).
# keepalived is also disabled
disableComponents:
kubernetesComponents:
- cloudController
# - rke2-canal
# - rke2-keepalived
# - rke2-kube-proxy
cni:
# or calico, canal, etc. if you want another plugin
- cilium
# ....
machineTemplate:
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: ProxmoxMachineTemplate
name: rke2-master-template
nodeDrainTimeout: 2mThis partial example shows how to deploy a Kubernetes cluster, combined with the GitOps approach, allowing you to manage a cluster independently of the provisioning tool and benefit from an automated lifecycle with a PR/merge workflow identical to that used for applications.
In conclusion, although Cluster API is not new, it has now reached real maturity with concrete feedback like Michelin, which manages 62 clusters in production. CAPI finally brings the missing “lifecycle” layer: a Kubernetes API to manage… Kubernetes. Whether you run 3 test clusters or dozens in production, CAPI turns cluster creation and maintenance into simple Git operations, drastically reducing automation debt and dependence on proprietary tools. However, it is important to note that adopting CAPI requires learning time and a good understanding of how it works to fully benefit from it.
In a multi-cluster world, it’s no longer just about running several Kubernetes instances: they must cooperate to provide fault-tolerance, bring data closer to users, apply global policies, balance capacity, and sometimes chase the best performance.
The SIG Multicluster already defines a common grammar:
The goal is similar to a cluster mesh: expose a single service behind several clusters and route requests to the closest or most available, while maintaining consistent network/security controls.
Cluster API (CAPI) remains complementary: it manages the lifecycle (creation, update, deletion) of the clusters themselves, while SIG Multicluster orchestrates their interconnection and the distribution of traffic or workloads.
In short, CAPI builds the fleet, SIG Multicluster gives it a collective brain—a vast ongoing project, but already essential for organizations aiming for planetary high availability or data residency by jurisdiction.
So, should you build a gigantic Kubernetes cluster, or split the load between several smaller clusters?
That’s what the talk A Huge Cluster or Multi-Clusters? Identifying the Bottleneck tries to answer.
Kubernetes has known practical limits (e.g. 110 pods per node, 5,000 nodes max) and classic bottlenecks: API server, ETCD, DNS, storage, or fine-grained node management…
But what are the best practices for choosing between one big cluster or several small ones?
There is no single solution—it all depends on your priorities.
If your priority is large-scale efficiency and central governance, one big cluster may suffice (as long as you master the technical limits).
But if you aim for team autonomy, enhanced security, or heterogeneous use cases, the multi-cluster strategy is more suitable… provided you have the right tools to orchestrate it (CAPI, IDP, distributed observability, etc.).
Why not go for intermediate solutions with Multi-tenancy via “Kubernetes-in-Kubernetes”?

The multi-tenancy approach in Kubernetes is not limited to creating namespaces. The ecosystem now offers a range of tools to virtualize or partition Kubernetes environments—from the lightest (shared-namespaces) to the most isolated (dedicated clusters). We often talk about Kubernetes-in-Kubernetes, as some tools allow you to run “pseudo-clusters” inside a main cluster. Here are the main approaches, from simplest to most complex:
Key takeaways:
NetworkPolicy v1 (Kubernetes standard) is still widely used. It allows, as in the example below, to restrict communications between Pods via labels and TCP ports:
# Example: only allow "frontend" pods to talk to "backend" on port 6379
kind: NetworkPolicy
metadata:
name: netpolv1
namespace: sokube
spec:
podSelector:
matchLabels:
role: backend
policyTypes:
- Ingress
- Egress
ingress:
- podSelector:
matchLabels:
role: frontend
ports:
- protocol: TCP
port: 6379But this model remains limited:
New generations are emerging: Admin & Baseline Policies
Advanced CRDs, such as BaselineAdminNetworkPolicy, allow you to express global or per-namespace policies, with true explicit “deny” filtering, useful for securing environments from the start:
# Example: deny all inter-namespace traffic (by default)
kind: BaselineAdminNetworkPolicy
metadata:
name: default-deny
spec:
subject:
namespaces: {}
ingress:
- name: "default-deny"
action: "Deny"
from:
- namespaces: {}
egress:
- name: "default-deny"
action: "Deny"
to:
- namespaces: {}And tomorrow: L7 filtering and identities
With Istio and Service Mesh, we go even further: AuthorizationPolicy allows filtering not just on IPs or labels, but on:
# Example: only allow GET on /siliconchalet/events from a specific SA
kind: AuthorizationPolicy
metadata:
name: sokube
namespace: siliconchalet
spec:
action: ALLOW
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/sokube"]
to:
- operation:
methods: ["GET"]
paths: ["/siliconchalet/events"]Network security in Kubernetes is evolving from simple pod isolation (NetworkPolicy v1) to global or admin rules via CRDs (Baseline/ANP), up to intelligent filtering based on identities and layer 7 with service meshes like Istio.
But much work remains: standardization, portability between CNIs, and integration with richer access controls. Some are already asking: could NetworkPolicy become the future Gateway API for network security? A unified, extensible framework, integrating L3 → L7 and aligning with the move towards Zero Trust.
A demo is available in this Github repo: NetworkPolicy Demo
OpenTelemetry is becoming the universal standard for observability in the cloud-native ecosystem. One of its key strengths: auto-instrumentation capability, without having to modify application code.
How it works (example): You declare a Kubernetes Instrumentation object as below:
apiVersion: opentelemetry.io/v1alpha1
kind: Instrumentation
metadata:
name: demo-instrumentation
spec:
exporter:
endpoint: http://trace-collector:4318
propagators:
- tracecontext
- baggage
sampler:
type: parentbased_traceidratio
argument: "1"This is enough to automatically inject tracers into supported applications.
Key points:
In summary: deploy, annotate, trace!
A demo is available in this Github repo: OpenTelemetry Demo
With the multitude of observable data (traces, logs, metrics) and their growing volume, identifying a failure or bottleneck becomes a real challenge.
AI comes into play here not to replace humans, but to pre-analyze and summarize key signals.
Current challenges:
The right approach: specialized agents rather than a generic chatbot.
MonstorService/Get with 100% of latency concentrated).TimeoutException, here), correlated with traces.
Observed result (real example):
In summary, modern observability is a data engineering job, and there are still some essential points to master:
It’s not “plug in an LLM = magic”, but rather targeted automation, on standardized building blocks.
LLMs are everywhere, but once the demo is over, many are disappointed: slowness, inconsistent answers, exploding costs… because building an application based on a language model is nothing like classic software development.
The solution: Observability becomes the key.
“LLMs add magic, but also a lot of uncertainty.
Observability is what turns that magic into a reliable product.”
As Christine Yen summarized in “Observability in the Age of LLMs“, the real challenge is not having a model, but maintaining it in production, truly understanding it—through what it does, not what you expected.
See the full talk → Production-Ready LLMs on Kubernetes
With the rise of open source models, hosting an LLM on Kubernetes is becoming a viable option for many companies. This addresses several challenges:
To get started: Ollama + Open WebUI
But… LLMs are resource-hungry!
Major issues:
Result: GPUs saturate quickly—even an A100 can choke if the context is too long.
Emerging solutions: vLLM to the rescue
To fit large models into small configs, projects like vLLM introduce major optimizations:
Result: 2 to 4 times more GPU capacity, without new hardware, with the right flags or an optimized vLLM + FlashAttention build.

Kubernetes is gradually establishing itself as the ideal platform for running agentic architectures, where autonomous AI agents collaborate, interact with APIs, and orchestrate complex tasks.
To this end, Solo.io has announced several projects: Kgateway, MCP Gateway (part of the Kgateway project), and Kagent
Kgateway: a Gateway API for AI: It is based on the Kubernetes Gateway API standard, adapted for AI traffic:
MCP (Model Context Protocol) Gateway:
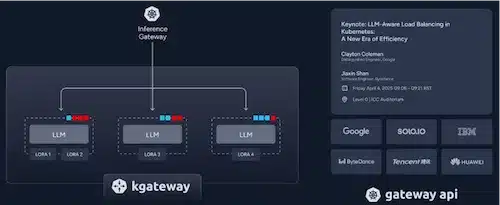
Finally, Kagent is an open-source framework for AI agents on Kubernetes that enables:
See the video Why Kubernetes Will Become the Platform of Choice for Agentic Architectures
Kubernetes clearly aims to become the reference platform for running LLMs, as Clayton Coleman summarized with the phrase:
“LLMs is the new Web App”
But these models are not managed like a simple REST API: they are resource-hungry, require GPUs, memory optimizations, and a different lifecycle approach (observability, evaluation-based testing, rapid deployment). Whether on-premise (for sovereignty and confidentiality) or in the cloud, Kubernetes continues to evolve to integrate these new uses, while remaining compatible with DevSecOps practices: native security, CI/CD, observability, and governance. The tools mentioned above show that the AI ecosystem is structuring itself much like the web did for Kubernetes… but much more demanding.
Platform Engineering is becoming, in 2025, a structured and widely adopted practice in companies to provide centralized, reliable, and secure self-service environments.
See our article on the subject: DevOps and Platform Engineering: efficiency and scalability for your IT

Key trends in Platform Engineering:
Two testimonials particularly stood out, illustrating how Platform Engineering can transform both the developer experience and security at scale.
LEGO presented its new Kubernetes platform, designed to offer a smooth and consistent experience, whether on-premise or in the cloud. Their approach is resolutely structured:
But above all, LEGO emphasizes change management with a “vendor” approach:
Their mantra:
“Sell your platform”
“Keep your users close”
Watch the full talk
This second feedback, focused on security, delivers a clear message:
Rather than “shift-left” security to developers, integrate it into the platform to make it invisible and consistent.
Keys to a secure platform:
Recommendations:
In summary:
“Shift down to the platform, instead of shifting left to the developer”
Adopt a security-by-design culture, in “Platform-as-a-Product” mode
See the full talk: Platform Engineering Loves Security: Shift Down To Your Platform, Not Left To Your Developers!
In the Kubernetes ecosystem, a major challenge is resource waste (CPU, memory, storage, and unsuitable nodes), which is a significant FinOps issue.
To address this, an innovative approach is to repurpose the traditional use of OPA and Gatekeeper. Usually dedicated to security, these tools can be used to implement FinOps policies in Rego language, applied directly at object admission in the cluster. Other tools exist, such as kyverno.
This strategy allows you to set up several essential types of rules:
Integration with OpenCost provides real-time visibility on metrics, while continuous audit and “dry-run” mode help raise developer awareness before applying strict restrictions.
The benefits of this approach are multiple: better budget visibility, sustainable cost reduction, and unified governance combining security and cost control in a single GitOps framework.
See the full talk: Beyond Security: Leveraging OPA for FinOps in Kubernetes

KubeCon + CloudNativeCon Europe 2025 confirmed that Kubernetes is no longer a “pioneer” topic, but is entering a new phase: more maturity, more use cases, and above all, unprecedented scaling.
AI is no longer optional: LLM workloads, agents, and MLOps pipelines are becoming common, and Kubernetes is establishing itself as the preferred platform to host them, thanks to its portability and the growing range of GPU-aware tools.
Demanding AI patterns: context management, fine-grained GPU sharing, memory optimizations; these challenges require high-precision observability to track costs, latency, quality drift, and SLO compliance.
Platform Engineering is becoming widespread: feedback proves that an opinionated, centralized, secure, and standardized platform is now the surest way to tame this complexity while serving product teams in self-service mode.
In summary, the ecosystem is moving towards ever more use cases—AI in the lead—at large scale. This rise in power, however, comes with increased complexity.
The message from KubeCon 2025 is clear: Maturity and continuous innovation, but rigor is becoming essential to turn Kubernetes into a strategic lever rather than a technological debt.
16 thoughts on "Kubecon London 2025: AI, Observability and Platform Engineering"