
By Sofiane Taleb.
How etcd persists data and how to configure it correctly.
Etcd is an essential part of many projects. It is the primarily backend data store of Kubernetes, the heart and standard system of choice for containers orchestration. Thanks to etcd, cloud-native applications are more available and remain functional even in the event of a server failure. Applications read and write data to etcd. This store then distributes configuration data to provide node configuration redundancy and resiliency.
When it comes to talk about persistance in etcd, understanding the Raft algorithm is a key point for a proper fine tuning. We’ll describe Etcd a bit, the Raft algorithm with 2 phases commit, write ahead logging and leader election. Then we’ll describe the persistence layer of this database and finally see how to fine tune Etcd to mitigate some bottlenecks and adapt to our own use case.
Etcd is a key-value store with a simple API. It can be highly available and offers data consistency. Adding nodes does not provide better performance (even potentially lowers it) but instead more resilience. The database will optimize for consistency over latency in normal situations, and consistency over availability in the case of a cluster partition. Its competitors can be DynamoDB, memcached, Redis, IgniteDB, Consul, but some of them are more (in-memory) cache oriented. This project has been democratized by Kubernetes, but is used by other large scale applications.
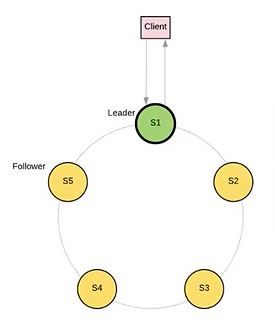
Figure 1 – Raft cluster
Raft protocol (https://raft.github.io/raft.pdf) allows a cluster to stay coherent and determine the state and role of each node. A node can have a role of leader or follower. There is a transitional role called “candidate” that a node will reach if it is a follower but is not connected to a leader. In a healthy Raft cluster, there is exactly one node with the role master. When a network partition divides the cluster, the master will be present on one side only, and a second master can be elected in the other partition. The cluster can have a period without master during the election phase.
In the context of etcd, the master node is necessarily handling operations that require consensus (so every write operation). The follower nodes can handle some operations (like serialized reads), but most importantly exist for the data replication that ensures the database high availability. This is a first reason why adding nodes to an etcd cluster is not (always) going to raise performance.
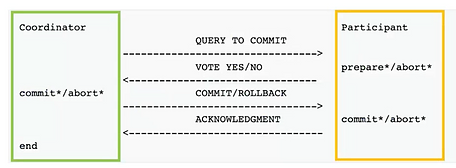
Figure 2 – Two phases commit
Raft relies on 2-phases-commits (fig 2) for operations that need consensus. It’s a transaction pattern with two phases. The first phase makes sure agents are ready to apply a transaction, and the second phase actually applies the transaction. Put simply, when a write request arrives on the cluster, the master (fig 2 – green) will first ask to followers if they (fig 2 – orange) are ready to write some data. If the master receives a quorum of positive answers (i.e a majority of the nodes accepts the transaction), then it will itself perform the write persistance, then indicate to the followers to do the same. Since the leader is the data source of truth in our cluster, those 2 phases ensure that the leader is legit (phase 1), and that data is correctly replicated (phase 2).
While Raft algorithm works with an even number of nodes, it generally makes more sens to have an odd number. That’s because for N nodes, N = 2k + 1 and the cluster can accept k failed nodes. In the mean time, the quorum is reached with N/2 + 1. For an even number of nodes, the quorum is reached with more nodes while accepting the same number of failures.
3 node cluster can handle 1 node fail (the majority is 2 nodes).
4 node cluster can handle 1 node fail (the majority is 3 nodes).
5 node cluster can handle 2 node fail (the majority is 3 nodes).
6 node cluster can handle 2 node fail (the majority is 4 nodes). 
Figure 3 – Steps involving the filesystem
During the two phases of an operation that requires persistance, etcd will call the linux fsync() function (fig 3 blue) in order to synchronously persist the data on disk. This is performed one time on each node of the cluster. There are risks of failures at every application layer (libraries, kernel, physical components, …). Since this operation is synchronous, its duration will directly impact the request latency measured by the client.
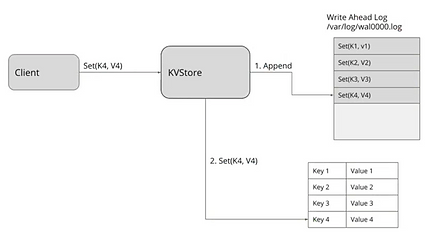
Figure 4 – Write Ahead Logging
To mitigate problems in case of disk write failure, a write-ahead-log (WAL) is used. It’s a file opened in mode “append-only”, in order to keep the cursor at the end of the file. When an etcd node needs to persist data, it will first append a new event at the end of the WAL (fig4 “1. Append”). Then it will call fsync() on this file in order to make sure the event is persisted on disk. Raft is used to synchronise the WAL between the nodes, not the actual data store. The datastore is another file, with an optimized structure for queries, and its modification is done like typical file persistance, relying on all cache mechanisms (so not using fsync()). It’s not a problem since the source of truth is considered the WAL, not the data store itself.
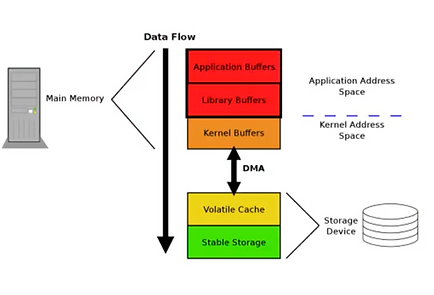
Figure 5 – Filesystem
At the filesystem level, the fsync() call has a lot of unrelated I/O. It will not synchronize only our file data, but other related objects about meta data, and even other unrelated files. That’s why a “fast-commit” journal with a more compact data format is available in ext4. You need to activate the feature at the filesystem creation (Fast commits for ext4, section “Using fast commits”), and this feature comes on top of the basic implementation (it’s complementary). However you need a recent kernel for this feature to be available since it’s been released in 2021. The use of this fast-commit journal showed improved performances up to 200% in case of fsync(), and up to 75% on NFS workloads.
Now that we’ve explained how etcd makes sure our data is highly available and coherent, we’ll identify some performances bottlenecks, and how to mitigate them by configuring etcd correctly.
First, it’s important to known that during the time a cluster has no master, it becomes unavailable for write queries. Depending on etcd configuration, this may result in several seconds of leader election. Since Kubernetes has tendency to send a lot of requests to etcd, that can result in a freezing k8s cluster (not unavailable, but unable to make changes).
Secondly, since persisting data has the fsync() synchronous step, persistance can also become a bottleneck since requests may stack up and eventually get dropped by etcd. This is particularly a problem in cloud environments. Because of cloud abstractions, you may not fully control the quality of service offered by your persistance layer. For example, since your etcd data is generally at the Gb order of scale, you may lower your costs by choosing a small SSD. But your cloud provider may lower its bandwidth (compared to the larger volumes alternatives), especially when it comes to network solutions like block storage. Etcd documentation provides hardware recommendations for cloud services.
In order to mitigate the bottlenecks, it’s up to you to understand your context, requirements, and make the correct choices. For your persistance layer, the only objective is to have the fastest write possible. So choose the best QoS (local SSD) and when possible tune the underlying filesystem to lower the overhead of fsync().
Figure 6 – Cluster of nodes
In the Raft algorithm, you can also configure two variables. The first is the interval at which the master sends “heartbeats” to the followers. Heartbeat is a network message that confirms to a follower that the master is existing & connected. The second variable is the “election timeout”, which is the delay before a follower becomes candidate. So, every heartbeatInterval , the master node will send heartbeat messages to the followers. And if a follower does not receive any heartbeat during an electionTimeout interval, it will consider the master gone and pass candidate.
The heartbeat interval defaults to 100ms and can be tuned with the flag –heartbeat-interval or ETCD_HEARTBEAT_INTERVALenvironment variable. It’s generally recommended to set this parameter around the round trip time (RTT) between two members (i.e x2 x3 latency). If this value is set higher than needed, it’ll raise the request latency since new log entries are propagated to followers with hearts. On the other hand, setting it too low will generate useless messages and raise the net & CPU use of your members, lowering their capacity to accept more requests.
Election timeout defaults to 1000ms and can be tuned with the flag –election-timeout or ETCD_ELECTION_TIMEOUT environment variable. It’s a good practice to set time x10 to x50 the timeout interval. The idea is to make sure that if a heartbeat is lost on the network, a follower won’t instantly become candidate.
When tuning those flags, one can use the benchmark CLI tool provided with etcd in order to measure the impact and assess the effectiveness. Etcd documentation for the benchmarking. It’s also important to monitor etcd server metrics. The number of leader changes and failed proposals can denote a potential mis configuration leading to useless leader elections.
Now that we have all this in mind, a quick note regarding the use of etcd with Kubernetes. You may have encountered distributors stating that a production cluster should have the minimum possible latency between etcd nodes. That’s for example the case in this page of the Rancher documentation, and its equivalent from Red Hat.
But why couldn’t we have a worldwide etcd cluster that ensures a maximum availability of my Kubernetes cluster ? It comes down to the 2 phases commit: because a request is answered after a quorum of nodes is reached, and after data is persisted on disk, a high latency will raise the time needed to return a response. We need to count the fact that most requests will be forwarded from a follower to the leader, which will wait for consensus, then persist, before sending back the response to the follower, that will eventually respond to the client. Problem is that the k8s API server has a high RQPS rate against etcd, so higher latency of response means requests can stack up, and lead to etcd becoming overloaded if not unavailable. Etcd network metrics are a good point to observe in this case.
We may face a situation where an application using Raft is deployed to your Kubernetes cluster. This article conducts some analysis with Vault, showing how anti affinity can reduce your probability to loose a Raft cluster, and that you don’t need hundreds members to ensure resilience. Raft consensus on Kubernetes : how strong is it?
We’ve seen how etcd persists data at the node level on disk and what bottlenecks slow down its operations. Explaining the Raft protocol, we’ve shown that network latency can have an impact on cluster performance, and how to fine tune it.
On one hand, it’s important to recall that while etcd is generally known for having a “master” and “followers”, ensuring its performance requires to consider them both equals when it comes to requirements. Mainly because you never known which role may endorse a node.
Figure 7 – Challenges overview
On the other hand, network latency is another dimension to take into account when tuning your configuration. In any case, monitoring the cluster is important to observe the impact of the configuration. Sysdig provides an extended article, and Etcd documentation has a dedicated page to integrate Prometheus and Grafana.
Overall, etcd stays a persistance layer, and since you may even use it outside of Kubernetes, the focus is to anticipate the type of use the application layer requires. When using etcd worldwide for (very) high availability and ensure long living data persistance, the latency is higher and the performances will drop. On the contrary, using etcd in a small region allows for higher performance (like with k8s), but may eventually become a point of failure in the worst case scenarios. So to conclude, consider it like any other database, with the compromises it imposes and take the time to clearly identify your requirements in order to deploy it and configure it correctly.