
By Sofiane Taleb.
Comment etcd persiste la donnée et comment le configurer correctement.
Etcd est une partie essentielle de nombreux projets. Il s’agit de la base de données principale de Kubernetes, le cœur et le système de choix pour l’orchestration des conteneurs. Grâce à etcd, les applications cloud-native sont plus disponibles et restent fonctionnelles même en cas de panne du serveur. Les applications lisent et écrivent des données sur etcd. Ce magasin distribue ensuite les données de configuration pour assurer la redondance et la résilience de la configuration des nœuds Kubernetes.
Quand il s’agit de parler de persistance dans etcd, comprendre l’algorithme Raft est un point clé pour une bonne configuration. Nous allons décrire un peu Etcd, l’algorithme Raft avec validation en 2 phases, la journalisation par écriture anticipée (write ahead logging) et l’élection du leader. Ensuite, nous décrirons la couche de persistance de cette base de données et enfin verrons comment affiner les paramètres de Etcd pour atténuer certains goulots d’étranglement et nous adapter à notre propre cas d’utilisation.
Etcd est une base de données clé-valeur avec une API simple. Elle peut être hautement disponible et offre une forte cohérence des données. L’ajout de nœuds n’offre pas de meilleures performances (et même les réduit potentiellement), mais une plus grande résilience à la panne. La base de données optimisera la cohérence par rapport à la latence dans des situations normales, et la cohérence par rapport à la disponibilité dans le cas d’une partition de cluster. Ses concurrents peuvent être DynamoDB, memcached, Redis, IgniteDB, Consul, mais certains d’entre eux sont plus orientés cache (en mémoire). Ce projet a été démocratisé par Kubernetes, mais est utilisé par d’autres applications à grande échelle.
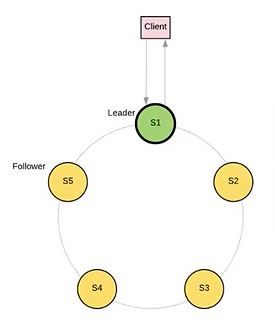
Figure 1 – Cluster Raft
Le protocole Raft (https://raft.github.io/raft.pdf) permet à un cluster de garder les données cohérentes et de déterminer l’état et le role de chaque noeud. Un noeud peut avoir le rôle de leader (aussi appelé master) ou de follower. Il existe un état de transition appelé « candidat » qu’un noeud atteindra s’il est un follower connecté à aucun leader. Dans un cluster en bonne santé, il y a un leader unique. Lors d’une partition réseaux, le leader ne sera présent que d’un côté, et un second leader peut être élu dans l’autre partition. Le cluster peut avoir une période sans leader pendant la phase d’élection.
Dans le contexte etcd, le noeud leader gère nécessairement les opérations qui nécessitent un consensus (donc toute opération en écriture). Les followers peuvent prendre en charge certaines opérations comme la lecture, mais ont pour rôle principal de répliquer les données et assurer la haute disponibilité de l’application. Ceci est une première raison pour laquelle ajouter des noeuds à un groupe Raft n’augmente pas nécessairement sa performance.
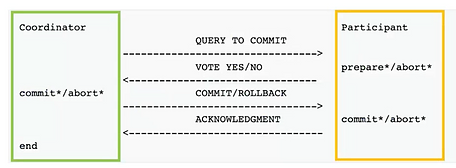
Figure 2 – Engagement en 2 phases
Raft repose sur l’engagement en 2 phases (fig 2) pour les opérations qui nécessitent un consensus. C’est un schéma de transaction avec 2 phases. La première phase s’assure que les agents sont prêts à appliquer une transaction, et la deuxième phase applique effectivement la transaction. Plus simplement, lorsqu’une requête en écriture arrive au cluster, le master (fig2 – vert), commence par demander aux followers si ils (fig2 – orange) sont prêt à écrire des données. Si le master reçoit une majorité de réponses positives, alors il va lui même effectuer l’opération avant d’indiquer aux followers d’en faire de même. Dans la mesure ou le leader est la source de vérité dans le cluster, ces deux phases permettent de s’assurer que le leader est légitime (phase 1) et que les données sont correctement répliquées (phase 2).
Même si l’algorithme Raft fonctionne avec un nombre de noeuds paires, cela a généralement plus de sens d’utiliser un nombre impaire. Cela est dû au fait que pour N noeuds, N = 2k + 1 et le cluster peut accepter k noeuds en panne. Dans le même temps, une majorité est atteinte avec N/2 + 1 noeuds. Pour un nombre de noeuds pair, la majorité est atteinte avec plus de noeuds tout en acceptant le même nombre de pannes.
3 noeuds permettent 1 noeud en panne (majorité à 2 noeuds).
4 noeuds permettent 1 noeud en panne (majorité à 3 noeuds).
5 noeuds permettent 2 noeud en panne (majorité à 3 noeuds).
6 noeuds permettent 2 noeud en panne (majorité à 4 noeuds). 
Figure 3 – Etapes impliquant le système de fichiers
Durant les deux phases d’une opération qui nécessite de l’écriture sur disque (fig 3), etcd effectue un appel Linux fsync() afin de persister la données sur disque de manière synchrone. Ceci est fait une fois sur chaque noeud du cluster. Il y a des risques de panne à chaque couche d’abstraction (librairies, noyau, composants physiques, …). Dans la mesure ou l’opération est synchrone, sa durée va directement impacter la latence des requêtes clients.
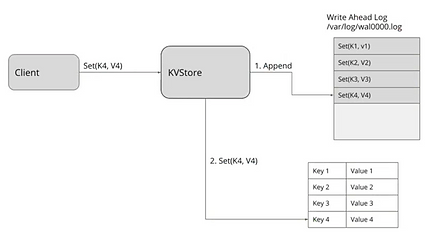
Figure 4 – Write Ahead Logging
Afin de limiter les problèmes dans le cas d’un échec d’écriture sur disque, un journal d’écriture en avance (WAL, write ahead log) est utilisé. C’est un fichier ouvert en dans le mode « append only », afin de garder le curseur d’écriture à la fin. Lorsqu’un noeud etcd persiste des données, il va d’aborder ajouter un évènement à la fin du WAL (fig 4 « 1. Append »). Ensuite il fera un appel fsync() sur ce fichier afin d’être certain que l’évènement a été enregistré sur disque. Raft est utilisé pour synchroniser le WAL entre les différents noeuds, et non pas la base de données en elle même. La base de données est un autre fichier dont la structure est plus optimisée pour les requêtes, et ses modifications sont effectuées grace à une persistance classique de fichier, utilisant les mécanismes de cache (donc sans utiliser fsync()). Ce n’est pas un soucis dans la mesure our le WAL est la source de vérité, pas la donnée structurée.
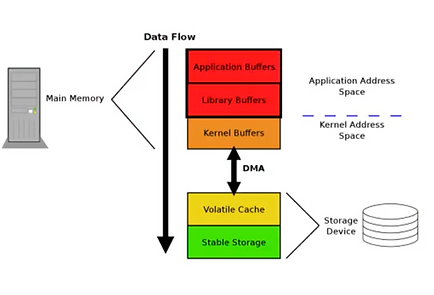
Figure 5 – Système de fichiers
Au niveau du système de fichiers, l’appel fsync() effectue plusieurs opérations annexes. L’appel synchronise d’autres fichiers sans rapport et des méta données. C’est pourquoi un journal « fast-commit » est disponible dans ext4, avec une structure de données plus compacte. Il doit être activé à la création du système de fichiers (Fast commits for ext4, section « Using fast commits »), et c’est une fonctionnalité complémentaire à l’implémentation originale. Elle n’est cependant disponible que dans les noyaux Linux récents dans la mesure ou elle a été publiée en 2021. L’utilisation du journal « fast-commit » a montré des gain en performance jusqu’à 200% dans le cas d’utilisation de fsync(), et jusqu’à 75% dans un context NFS.
Maintenant que l’on a expliqué comment etcd s’assure de la cohérence et disponibilité des données, nous allons identifier certains goulots d’étranglement de performance, et comment les contourner en configurant etcd correctement.
Premièrement, il est important de savoir que pendant l’élection d’un leader, le cluster devient indisponible pour les requêtes en écriture. Suivant la configuration de etcd, ceci peut mener à plusieurs secondes d’election. Dans la mesure ou Kubernetes a tendance à formuler beaucoup de requêtes à etcd, ceci peut mener à un cluster Kubernetes gelé (pas indisponible, mais incapable d’effectuer des changements d’état).
Deuxièmement, et parce-que la persistance des données repose sur l’appel synchrone fsync(), elle peut devenir un goulot d’étranglement car les requêtes pourraient s’accumuler et être rejetées par etcd. Ceci est particulièrement un problème dans les environnements cloud. De par les abstractions apportées, nous pourrions ne pas avoir un contrôle total de la qualité de service offerte par la couche de persistance. Par example, la volumétrie etcd étant généralement de l’ordre du Gb de données, il est envisageable de réduire les coûts financiers en choisissant un disque SSD de petite taille. Mais les fournisseurs cloud pourrait aussi réduire la bande passante associée (comparativement à un disque plus volumineux), particulièrement lorsqu’il s’agit de stockage réseau. La documentation etcd fourni des recommandations matérielles dans le cas des fournisseurs cloud.
Afin de limiter l’impact de ces goulots, c’est votre rôle de comprendre votre context, d’établir votre cahier des charges et en déduire les bons choix à faire. Pour la couche de persistance, le seul objectif est d’avoir l’écriture disque la plus rapide possible, donc préférez la meilleur qualité de service (SSD local), et quand cela est possible configurer le système de fichiers afin de réduire la surcharge induite par fsync().
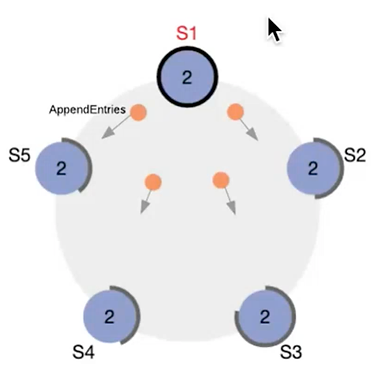
Figure 6 – Groupe de noeuds
Dans l’algorithme Raft, il est possible de configurer deux variables. La première est l’interval auquel le master envoie des « heartbeats » aux followers. Heartbeat est un message réseau qui confirme à un follower que le master existe et est toujours connecté.
La seconde variable est « election timeout », qui indique le délai avant qu’un follower passe candidat. Donc, chaque heartbeat interval, le master envoie des messages heartbeat aux followers. Si un follower ne reçoit pas de message heartbeat pendant un délai égale à « election timeout », il considèrera que le master n’est plus, et passera candidat.
Le heartbeat interval est par défaut à 100ms et peut être modifié avec le paramètre -heartbeat-interval ou la variable d’environnement ETCD_HEARTBEAT_INTERVAL. Il est généralement recommandé de définir ce paramètre autour de la durée d’un aller-retour entre deux membres du cluster (soit x2 à x3 la latence réseau). Si cette valeur est plus haute que nécessaire, cela augmentera la latence des requêtes utilisateur dans la mesure où les nouvelles entrées de log (WAL) sont propagées aux followers grace aux messages « heartbeat ». D’un autre côté, la définir trop basse va gérer des messages inutiles et augmenter la consommation de réseau et CPU des membres, réduisant ainsi leur capacité à accepter de nouvelles requêtes.
Election timeout est par défaut à 1000ms et peut être modifiée avec le paramètre –election-timeout ou la variable d’environment ETCD_ELECTION_TIMEOUT. C’est une bonne pratique de la définir entre x10 et x50 la valeur de heartbeat interval. L’idée est de s’assurer que si un message heartbeat est perdu sur le réseau, un follower ne va pas instantanément passer candidat.
Lors de l’ajustement de ces paramètre, l’outil de test de la CLI fournie avec etcd permet de mesurer l’impact des changements et acter leur efficacité. Il existe une documentation pour cet outil de benchmarking. Il est aussi important d’observer les mesures du serveur etcd. Le nombre de changement de leaders et d’échecs de propositions (« proposals ») peut indiquer un problème de configuration menant à des élections inutiles.
Maintenant que nous avons tout cela en tête, une note concernant l’utilisation de etcd dans le contexte de Kubernetes. Vous avez peut être lu des distributions Kubernetes indiquant qu’un cluster de production doit avoir une latence minimum entre les noeuds. C’est par example le cas sur cette page de Rancher, et son équivalent de Red Hat.
Mais pourquoi ne pourrions-nous pas avoir un cluster mondial assurant une disponibilité maximum de notre cluster Kubernetes ? Cela est dû à l’engagement 2 phases: parce-qu’une requête n’est répondue qu’après une majorité de noeuds ayant écrit la donnée sur disque soit atteinte. Ainsi, une plus grand latence réseau augmentera directement le temps de réponse aux requêtes. De plus, la majorité des requêtes arrivant sur un follower, elle devront être envoyées au noeud master, qui attendra le consensus, avant de persister et de retourner la réponse au follower auquel vous êtes connecté. Le problème est que l’API Server de Kubernetes formule beaucoup de requêtes par seconde, donc une haut latence peut aboutir à une pile de requêtes, surchargeant les noeuds etcd. Les metrics etcd sont un bon point d’observation pour détecter cette situation.
Il est possible d’avoir une application utilisant Raft déployée sur un cluster Kubernetes. Cet article mène une analyse avec Vault. Elle montre comment les politiques « node anti affinity » peuvent réduire la probabilité de perdre un noeud Raft, et qu’il n’est pas nécessaire d’avoir des centaines de noeuds pour assurer une bonne résilience à la panne. Raft consensus on Kubernetes : how strong is it?
Nous avons vu comment etcd persiste les données sur le disque et quels sont les goulots d’étranglement qui peuvent ralentir les opérations. En expliquant le protocole Raft, nous avons montré comment la latence réseaux peut impacter l’utilisateur final, et comment configurer Raft correctement.
D’un côté, il est important de rappeler que bien que etcd soit généralement connu pour avoir un master et des followers, s’assurer de son bon fonctionnement nécessite de les considérer sur un même pied d’égalité en terme de resources. Principalement car l’on ne connait pas le rôle que pourrait avoir un noeud.
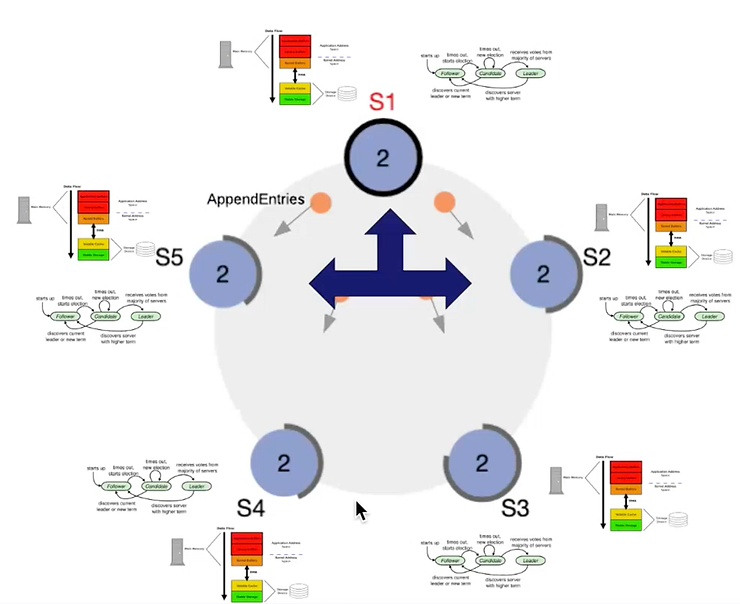
Figure 7 – Vue d’ensemble
D’un autre côté, la latence réseau est une autre dimension à prendre en compte lorsque nous ajustons la configuration du cluster. Dans tous les cas, observer le cluster est important pour comprendre l’impact de cette configuration sur les performances. Sysdig a écrit un article plus avancé à ce sujet, et la documentation etcd dispose d’une page dédiée pour intégrer Prometheus et Grafana.
A la fin, etcd reste une couche de persistance, et dans la mesure ou il peut être utilisé en dehors de Kubernetes, l’important est d’anticiper les besoins de l’application. Lors d’une utilisation mondiale de etcd pour une très haute disponibilité, la latence est plus haute et les performances vont être réduites. Au contraire, utiliser etcd dans une seule région permet de gagner en performance (par exemple avec Kubernetes), mais peut devenir un point d’échec dans un scénario extrême. Pour conclure, etcd est à considérer comme toute autre base de données avec les compromis que cela impose, donc prenez le temps d’identifier clairement vos exigences afin de la déployer et la configurer correctement.