
By Gaëtan Metzger & Yann Albou
Amsterdam, March 2026. For the second time, the city hosted KubeCon + CloudNativeCon Europe, and this edition marked a turning point. 13,500 attendees, 100 countries, and nearly one in two participants attending for the very first time: the cloud native community keeps growing.
What stands out this year is the shift in tone. AI is no longer a side topic: it shapes the keynotes, the architectures, and the debates. Kubernetes is establishing itself as the orchestration platform for the agentic era. And alongside it, another topic pushed its way onto the stage: digital sovereignty, driven by geopolitical pressure and the rise of European regulation.
In this post, we share our takeaways from this edition: the key numbers, the major trends, and a selection of sessions that caught our attention.
This 2026 edition confirms the momentum of the cloud native community: 13,500 participants from 100 countries gathered in Amsterdam, with 46% attending their very first KubeCon, a strong signal that interest in the ecosystem keeps growing well beyond the regular crowd. Full numbers are available in the official CNCF stats for KubeCon Europe 2026.
The CNCF ecosystem now counts 230 projects and has passed the milestone of 19.9 million contributors (up from 15.6 million six months earlier), nearly 30% growth in a single semester.
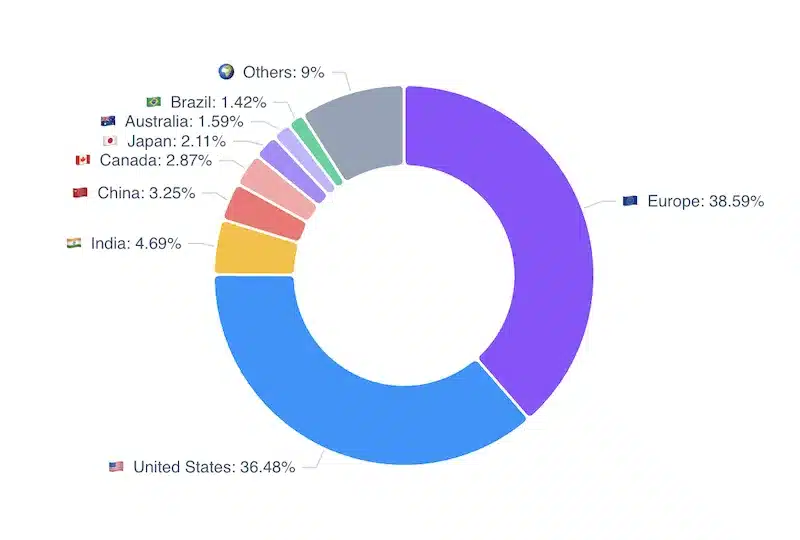
On the geography side, data from the last 12 months across all CNCF projects holds a pleasant surprise: Europe accounts for 38.8% of contributions, ahead of the United States (36.29%). Within Europe, Germany leads with 9.82%, followed by France (4.68%) and Switzerland (2.49%). This is a strong signal, especially welcome given the digital sovereignty theme that ran through this edition’s keynotes.
On the ecosystem side:
The CNCF also launched a reference architecture contest aimed at documenting architectures that end users actually run in production. Beyond diagrams, the goal is to capture the decisions, trade-offs, and lessons teams have drawn from their real deployments. A great example is the CERN scientific computing architecture, which shows how one of the world’s largest research centers uses Kubernetes to run large-scale scientific workloads.
Finally, the next editions of KubeCon will be held in Spain and then Germany.
First, the program analysis shows a particularly packed edition: 325 sessions over 3 days, representing 186 hours of cumulative content across up to 12 parallel tracks, spread across 17 distinct track types.

The breakdown by track confirms the major themes. Platform Engineering leads by a wide margin with 38 sessions, followed by AI & ML (27) and Security (24). Observability (19) and Operations & Performance (18) round out the top 5. Worth noting: the Maintainer Track alone totals 82 sessions, reflecting the maturity and activity of projects across the ecosystem.
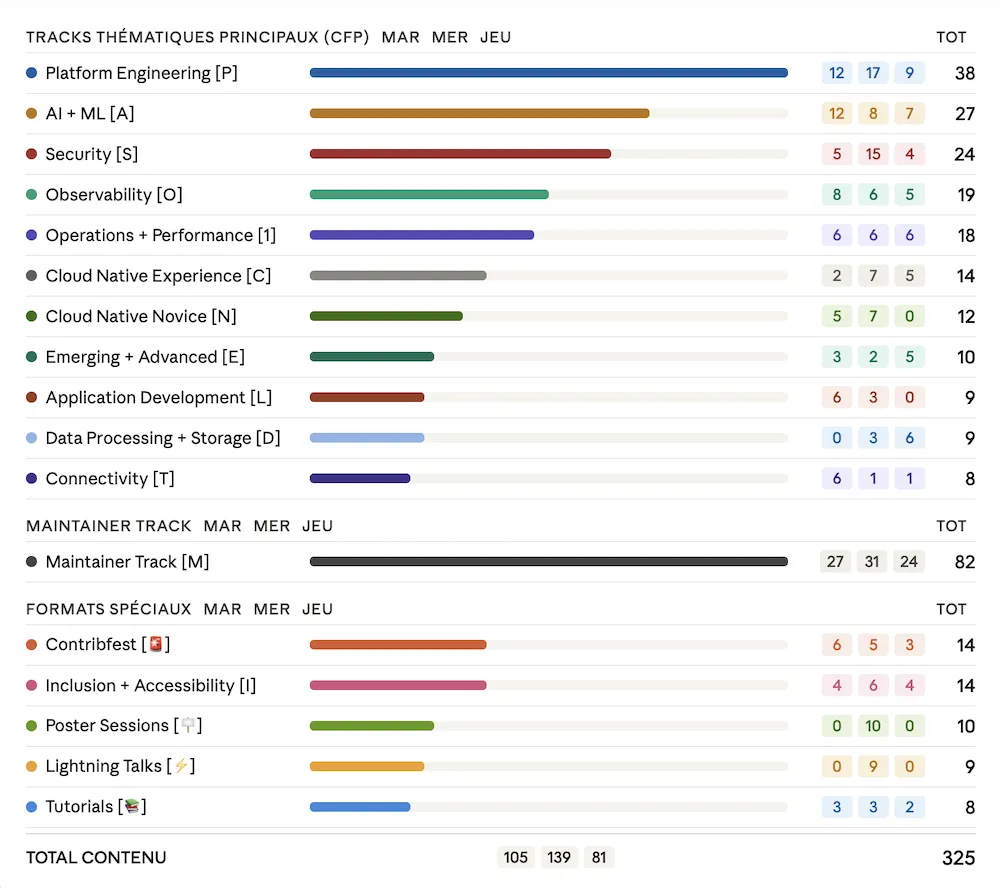
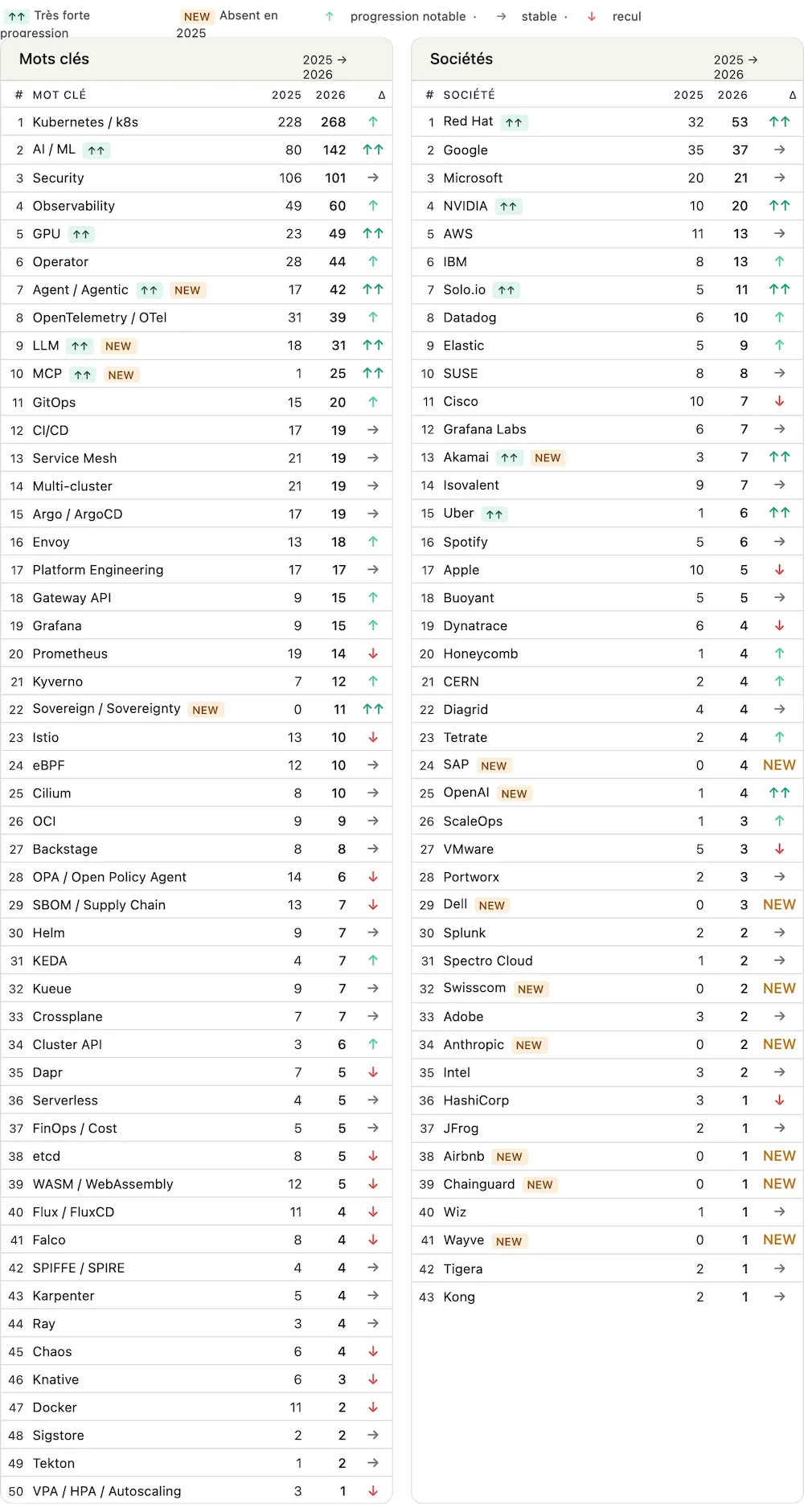
The most frequent keywords in session titles and descriptions are even more revealing. The new entrants marked NEW speak for themselves: Agent/Agents explodes in frequency, Sovereignty makes its first appearance, and on the company side, OpenAI and Anthropic are mentioned for the first time. NVIDIA also confirms its growing presence in the cloud native ecosystem. Cloud native is no longer just infrastructure: it has become the platform for agentic AI.
But beyond the excitement, a question arises: was this KubeCon a bit too focused on AI? Some topics felt pushed aside, as if the ecosystem was trying hard to reframe everything through the lens of artificial intelligence. This balance will be worth watching in future editions.
But the message from this edition is clear:
The Future of Cloud Native Is… Agentic. Let’s keep cloud native moving!
Platform Engineering was also clearly front and center. The key idea: everything becomes an API. Tools like Crossplane or Kro embody this vision, where infrastructure is exposed as consumable contracts for product teams, without them needing to know the implementation details underneath.
This may be the most striking new development of this edition: digital sovereignty took center stage in the keynotes, going well beyond the usual tech talk. European companies were given unusually prominent visibility, and the topic became a recurring thread, driven both by regulatory pressure and a geopolitical context pushing organizations to take back control of their infrastructure.
Two definitions stood out. Saxo Bank reframed the question clearly:
“Digital sovereignty is not where you run. It’s the freedom to change where you run, what you run on, and how it is connected — without rewriting a single app.”
SNCF echoed this view, preferring to talk about strategic autonomy rather than sovereignty. The shared idea: code remains global, but deployment can be sovereign. Infrastructure adapts to local legal and regulatory constraints without touching the applications themselves. Open source is a key enabler of this.
The question also directly affects AI: 79% of organizations consider AI sovereignty a top strategic priority. In response, the CNCF is pushing an open cloud native stack for AI: Kubernetes, KServe, vLLM, llm-d, with a clear message: the era of black-box AI is coming to an end.
Solo.io gave a concrete illustration of this shift by presenting several projects at the conference, including kagent and Agent Gateway. The Agent Registry was even submitted to the CNCF live during the conference. A new project was also announced: AgentEval, which lets you benchmark AI agents using OpenTelemetry traces before they reach production.
Finally, the CNCF Community Awards 2026 recognized SNCF as the best end user this year, a meaningful symbolic recognition for a European company, in an edition where sovereignty was at the heart of every discussion.
The Cyber Resilience Act (Regulation EU 2024/2847) is a European regulation that came into force in December 2024. It sets mandatory cybersecurity requirements for all hardware and software products sold in the EU. Manufacturers must build in security from the start (security by design), provide updates throughout the product lifecycle, and report critical vulnerabilities to ENISA within 24 hours. It applies to any company (European or not) selling digital products in Europe, with full enforcement starting December 11, 2027.
The CRA creates a common regulatory framework across the EU, making it easier to bring products to the European market at scale. Well-executed compliance also becomes a competitive advantage against non-EU competitors who face fewer security constraints.
The OpenSSF is active on several fronts: its Global Cyber Policy Working Group produces guides and analyses for the open source ecosystem, including a practical guide for OSS developers and a free online course (LFEL1001) to help prepare for CRA requirements.
On the CNCF side, the TAG Security & Compliance aligns cloud native practices (SBOM, minimal containers, secure CI/CD) with CRA requirements, and incorporated the topic into its Security Slam 2026.
Both organizations also contribute to the Open Regulatory Compliance Working Group (Eclipse Foundation), which centralizes resources and FAQs to help the open source ecosystem navigate the CRA.
The CRA illustrates the convergence between digital sovereignty and cloud native: European regulation is pushing organizations to take back control of their software supply chain, and the CNCF is actively positioning itself as a lever to make that happen, by aligning its projects, practices, and working groups with the requirements the entire industry now faces.
You can think of AI as a system built on three complementary pillars:
In short: training = learn, inference = respond, agents = act.
These three pillars have very different infrastructure needs. Training and inference are GPU-hungry and sensitive to latency. Agents, on the other hand, require fine-grained orchestration: dynamically starting and stopping processes, accessing external tools, managing dependencies between steps, and isolating and securing executions.
This is exactly where Kubernetes shines: it provides a unified platform to orchestrate all three types of workloads, from training jobs to inference services to agentic pipelines.
As mentioned above, AI rests on three complementary pillars: training (learn), inference (respond), and agents (act). What is fundamentally changing today is the rebalancing between these three phases: where inference used to represent a third of workloads, it now accounts for two thirds. Infrastructure needs to adapt accordingly.
To make sure Kubernetes platforms are ready to run these workloads, the CNCF launched the Kubernetes AI Conformance Program, which defines the minimum capabilities needed to reliably run AI/ML workloads, letting platforms get certified.
Large-scale inference also raises new infrastructure challenges. Traditional load-balancing algorithms are not suited to language models, which require fine-grained request distribution that accounts for context, session, and GPU load. New tools are emerging to address this, such as llm-d, a native Kubernetes framework that optimizes inference distribution across a cluster of vLLMs, and kgateway, which natively incorporates these constraints at the network layer.
Another strong theme: specialized intelligence. Given costs and latency constraints, teams are looking for more targeted, more efficient models that can run on heterogeneous hardware with strong security and privacy guarantees. The agent ecosystem is rapidly taking shape around frameworks like kagent, LangGraph, HolmesGPT, and Dapr.
This evolution fits into a deeper transformation of Kubernetes, which can be read in three phases:
This third phase translates concretely into the ability to handle complex topologies (multi-GPU, multi-cluster), integrate diverse AI frameworks (OpenRL for fine-tuning, Gemmaverse for Gemma models…), and ship at the speed of innovation without sacrificing operational control.
“The future of Kubernetes: from a platform for building platforms… to the nervous system for autonomous infrastructure.”
KubeCon Amsterdam 2026 marked the emergence of a new cross-cutting topic: AI traffic governance. Several sessions converged around the same question: how do you apply the same security, observability, and reliability standards to calls toward LLMs and AI agents that you apply to the rest of your Kubernetes traffic? It is in this context that the AI Gateway Working Group was officially announced in March 2026, with the mission to define declarative APIs and standards for AI workload networking in Kubernetes. The group builds on the foundations of the existing Gateway API and extends its scope to cover the specific needs of inference.
An AI Gateway is essentially an extension of the Kubernetes Gateway API designed for LLM traffic. The reference implementation is kgateway (formerly Gloo), an open source Envoy control plane. The added capabilities include:
Beyond standard HTTP traffic to LLMs, AI agent use cases introduce new protocols: MCP (Model Context Protocol) and A2A (Agent-to-Agent). AgentGateway is an open source proxy written in Rust, that integrates with kgateway and is designed to secure and observe agent-to-LLM, agent-to-tool, and agent-to-agent communications:
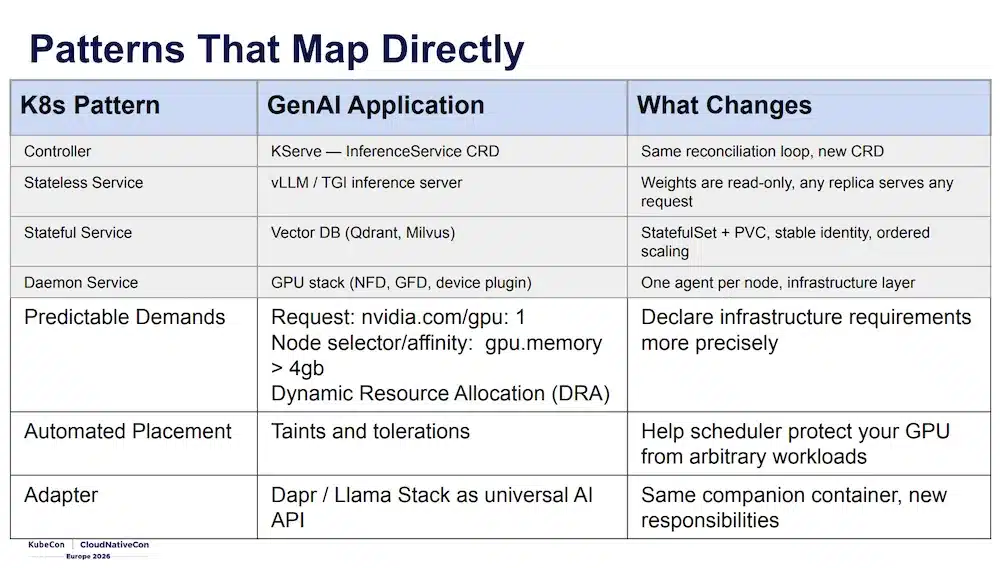
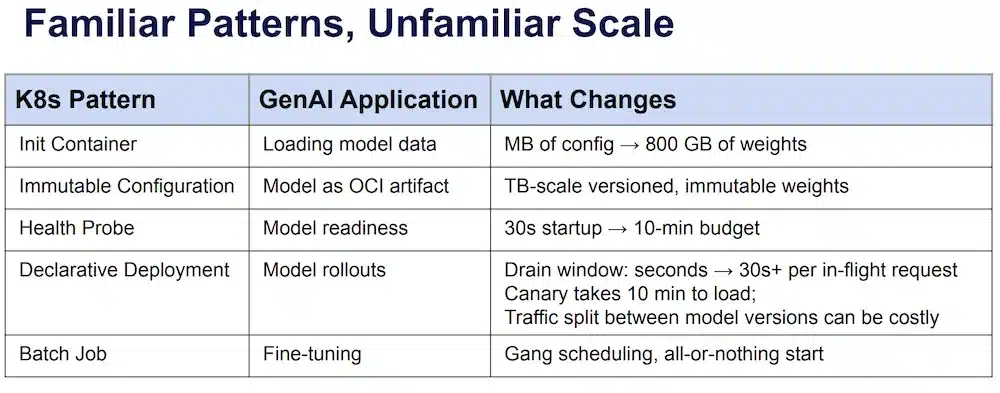
Bilgin Ibryam (Diagrid) and Roland Huss (Red Hat) are co-authors of the book Kubernetes Patterns (O’Reilly), and this session applies exactly those patterns to the GenAI world. The core idea: the Kubernetes patterns you already know all have an equivalent in an LLM stack:
| Kubernetes Pattern | GenAI Equivalent | What Changes |
|---|---|---|
| Controller | KServe, InferenceService CRD |
Same reconciliation loop, new CRD |
| Stateless Service | vLLM / TGI | Read-only weights, any replica serves any request |
| Stateful Service | Vector DB (Qdrant, Milvus) | StatefulSet + PVC, stable identity |
| Daemon Service | GPU stack (NFD, GFD, DCGM) | One agent per node, infrastructure layer |
| Batch Job | Fine-tuning | Gang scheduling, all-or-nothing startup |
The patterns are the same, but at an unusual scale: a few MB of config becomes 800 GB of weights, a 30-second readiness budget becomes 10 minutes, and the drain window for a rolling update goes from a few seconds to 30s+ per in-flight request.
Three new patterns emerge specifically for GenAI:
Model Data Staging: 86% of cold start time is model download. Four strategies, from simplest to most optimal:
| Strategy | Speed | Complexity | Use when |
|---|---|---|---|
| Init Container | Slow | Simple | Small models, simplicity is the priority |
| PersistentVolume (ReadOnlyMany) | Fast | Medium | Multiple replicas, standard production approach |
| Modelcar (sidecar) | Fast | Complex | KServe + speed, K8s < 1.35 |
| ImageVolume (beta K8s 1.35) | Fast | Simple | Future default choice |
“ImageVolume is the endgame.”
Token-Aware Routing: round-robin does not work for LLMs: all requests hit POST /v1/chat/completions but their GPU cost varies from 200ms to 5+ minutes. The Gateway API Inference Extension solves this: an InferencePool groups pods running the same model, and an Endpoint Picker (llm-d) selects the best replica based on queue depth, KV cache, or prompt prefix: same prefix → same replica → KV cache reused without recomputation.
RAG Composition: each building block maps to a Kubernetes primitive:
Several talks pointed to the same reality: as soon as you deal with distributed training, large-scale inference, or agents, scheduling requirements change. These workloads do not just consume CPU and memory. They often require multiple pods to start at the same time, GPUs to be available at the right moment, and finer-grained resource management across the cluster.
That is exactly the problem Volcano addresses. This Kubernetes scheduler is designed for demanding workloads like AI, batch processing, and HPC. It extends the default Kubernetes scheduler with mechanisms better suited to distributed jobs, GPU needs, and resource-heavy workloads.
Volcano acts as a bridge between Kubernetes and major AI frameworks like PyTorch or TensorFlow. It lets them run their distributed jobs in Kubernetes with smarter scheduling, especially for GPUs, interdependent pods, and scarce resources.
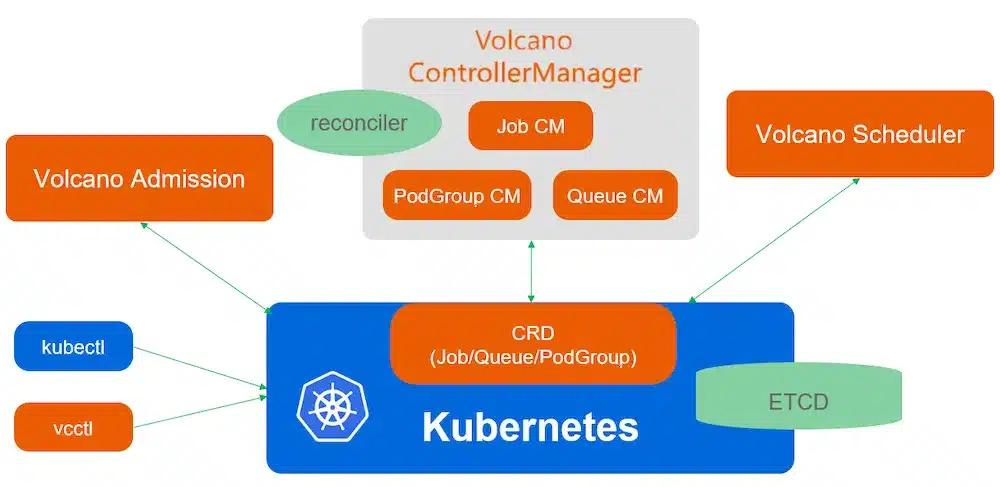
To extend the default Kubernetes scheduler, Volcano introduces several CRDs that let you describe batch and AI workloads in more detail. Its architecture:
Here is a simple example of a Volcano Job:
# vcjob-quickstart.yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: quickstart-job
spec:
minAvailable: 3
schedulerName: volcano
# If you omit the 'queue' field, the 'default' queue will be used.
# queue: default
policies:
# If a pod fails (e.g., due to an application error), restart the entire job.
- event: PodFailed
action: RestartJob
tasks:
- replicas: 3
name: completion-task
policies:
# When this specific task completes successfully, mark the entire job as Complete.
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- command:
- sh
- -c
- 'echo "Job is running and will complete!"; sleep 100; echo "Job done!"'
image: busybox:latest
name: busybox-container
resources:
requests:
cpu: 1
limits:
cpu: 1
restartPolicy: NeverOne of the strongest messages from this KubeCon is that platform engineering is becoming increasingly API-driven. The idea is simple: instead of directly managing infrastructure or relying on manual processes, teams interact with APIs that expose standardized, versioned, and automatable services. This approach better decouples teams, speeds up self-service, makes operations more reliable, and turns the platform into a real internal product with a clear contract between developers and infrastructure teams.
This session showed clearly that Kubernetes is not just for container orchestration: it can also become an API provider for exposing infrastructure services in a standardized way. Thanks to its CRDs and declarative model, Kubernetes lets you define business objects like a database, a bucket, a network, or an application platform, with a clear contract that product teams can consume.
With Crossplane, this logic goes even further: the platform can compose multiple cloud or internal resources behind a single Kubernetes API. Developers no longer directly request AWS, Azure, or GCP resources: they consume an abstract service exposed in the cluster, such as a Database or ApplicationEnvironment, while Crossplane handles translating that intent into real resources, provisioning them, and maintaining the desired state. Kubernetes becomes the common API layer between teams, with a self-service, governed, and portable approach.
This approach also fits very well within Team Topologies thinking. In platform engineering, the goal is not for every product team to become an expert in cloud providers or infrastructure, but for the platform team to provide ready-to-use capabilities to stream-aligned teams. The platform acts as an internal product, designed to reduce the cognitive load on development teams.
In this model, the API contract is the central element. It defines what the platform exposes, which parameters are available, what guarantees are offered, and what limits are imposed. Application teams consume a stable and understandable interface, without depending on the underlying implementation details. Infrastructure can evolve, change provider, or change its internal mechanism, as long as the contract remains stable for its consumers.
This model does raise three concrete challenges, illustrated by Allianz’s experience.
The first is service boundaries and ownership: who is responsible when something breaks? The answer lies in clear contracts: the provider guarantees API stability, the consumer validates its inputs, which means error messages themselves can show which team owns the problem.
The second, and perhaps the most critical in practice, is breaking changes: a change on the provider side can impact dozens of consuming teams, often discovered too late, in production. The solution combines contract testing with versioning, tests that detect breaks in CI, and a dual-versioning mechanism with webhooks, letting teams migrate at their own pace without production incidents.
The third is documentation drift: written once, never updated, with examples that stop working as the code evolves. The doc as code approach, with documentation generated from XRD annotations and examples validated in CI, ensures it always stays accurate and gets adopted.

A very concrete and no-nonsense talk about replacing VMware with KubeVirt in 2026. The starting point is crystal clear: legacy virtualization costs have exploded, Kubernetes is now present in virtually every company, and the C-level mandate boils down to two words: “One Platform”. As a result, 28% of production clusters today host persistent VMs, up from 8% in 2023. KubeVirt addresses this trend with a powerful idea:
“Virtualization is a feature, not a place.”
In practice, KubeVirt extends Kubernetes via CRDs and runs VMs inside Pods (virt-launcher). The architecture relies on three components (Virt-API, Virt-Controller, and Virt-Handler, a DaemonSet on each node) and exposes two primitives:
VirtualMachine: the definition, like a DeploymentVirtualMachineInstance: the running instance, like a PodThe immediate benefit: RBAC, monitoring, CSI storage, and GitOps unified with the rest of the cluster. VMs become manageable with ArgoCD/Flux, and the OS layer can be hardened with Talos OS or Kairos.
On the network side, the talk provides an honest comparison between Cilium and Kube-OVN:
Limitations to know before getting started:
In production, the verdict is nuanced: ✅ Linux servers and dev/test, ⚠️ SQL databases, ❌ Oracle RAC or apps depending on USB dongles. A realistic migration timeline is 18 months.
“It’s not about running VMs. It’s about running applications.”

Saxo Bank runs a hybrid infrastructure: cloud-native Kubernetes workloads, but also many applications on legacy VMs that will not be containerized, and that is a deliberate choice. “Containerizing everything does not make business sense.” The real problem is not the technology, it is the process: provisioning DNS, certificates, a load balancer, or Active Directory access used to involve different teams, tickets, and delays.
Saxo’s answer is the Service Blueprint: a set of Kubernetes operators that model legacy infrastructure as CRDs. The workflow becomes: write YAML, open a PR (auto-assigned to the right team), merge, and the operator provisions. Git becomes the strict source of truth.
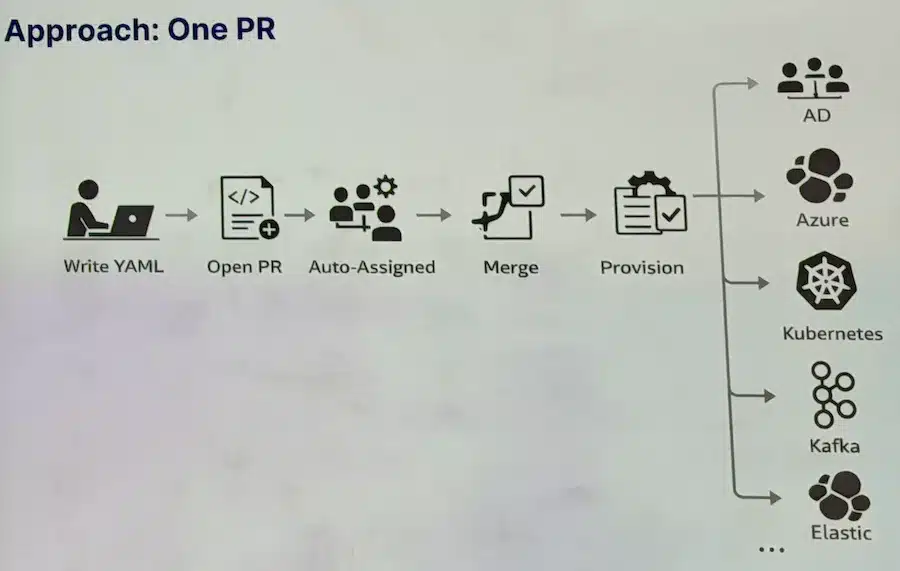
The operators handle idempotency, provisioning order, error recovery, and partial states across domains. Lifecycle gates let you control provisioning steps. The developer interface relies on Backstage to expose this service catalog.
This is a pragmatic approach to Platform Engineering: you do not start from scratch, you work with what you have. Kubernetes becomes the unified control plane, not a replacement, but a bridge between legacy and cloud-native workloads.
Backstage is an open source framework, originally created by Spotify, for building your own internal developer portal. It is not a fixed product with a single experience for everyone: it is a foundation on which each organization can build a portal adapted to its own way of working, its tools, and its processes.
This flexibility relies largely on its plugin system. A company can integrate existing plugins to connect its ecosystem, or build its own extensions to expose internal workflows, service catalogs, project templates, or internal APIs directly in Backstage.

This drive for modularity also shows in the technical evolution of the project, with work ongoing around the new backend system and the new frontend system. The goal is to make Backstage more cleanly extensible, easier to compose, and simpler to evolve, so each organization can assemble its portal without being locked into a monolithic architecture.
Adoption continues to grow strongly, with more than 4,000 adopters, more than 255 open source plugins, and around 32,900 GitHub stars at the time of the presentation.
The project is no longer carried by Spotify alone. Backstage now relies on a much broader contributor ecosystem, with several large companies actively participating in its evolution. Red Hat in particular plays an important role in its maturity and enterprise adoption, contributing to making it a credible foundation for large-scale developer platforms.
A real commercial ecosystem is also taking shape around the project. Spotify now offers Spotify Portal, a managed SaaS offering built on Backstage, while Red Hat pushes Red Hat Developer Hub, a supported enterprise distribution based on Backstage. This shows that Backstage is no longer just a promising open source framework: it is an increasingly mature foundation for developer portals used in production at scale.
Backstage is also evolving alongside the rise of AI. The project is no longer just a web interface for humans: it also aims to become an integration surface for assistants and agents. This includes work on the CLI, which makes programmatic interaction with the platform easier, as well as adoption of MCP (Model Context Protocol) to connect AI agents to Backstage more easily. The idea is clear: enable agents to discover the catalog, query documentation, trigger workflows, or consume platform APIs in a standardized way.
Raiffeisen Bank International (RBI) runs the Mercury platform: 13 OKD clusters, more than 1,000 namespaces, 70+ customer teams spread across 120 AWS accounts. Multi-tenancy relies on three isolation layers (namespace, cluster, AWS account) based on sensitivity level. Each cluster has its own ArgoCD instance, and Kargo orchestrates promotions across all these boundaries.
The heart of the talk is a distinction that is often overlooked: promoting an application and promoting infrastructure are not equivalent. An app can be rolled back in seconds; a deleted Crossplane infrastructure resource can cause data loss, which is difficult or impossible to undo. RBI solved this with a sharded Kargo topology (Kargo Agent Model): a central control plane stores Kargo resources, while local controllers (shards) execute them per cluster. This lets you define different promotion policies depending on the type of workload, with validation gates tuned to the risk level.
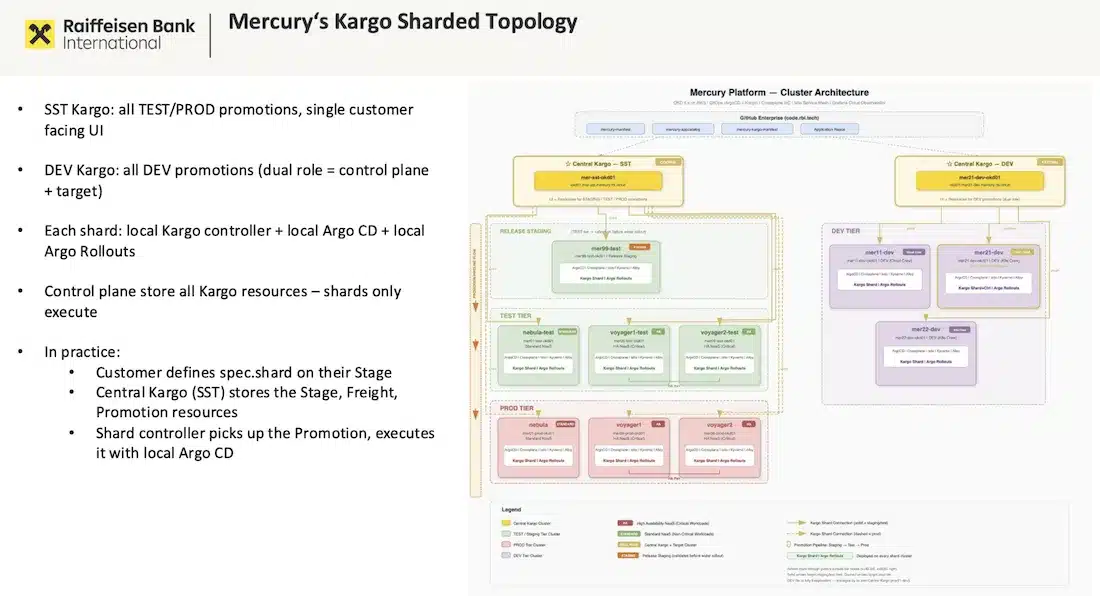
On Crossplane, the migration from v1 to v2, which extends namespaced Claims support to all composite resources to improve visibility and isolation, happens in 3 steps with no resource recreation and no downtime: enable migration mode, create a V2 claim that imports existing resources, then switch. A significant readability improvement in an environment where each namespace belongs to a distinct team.
This is where the AIOps dimension comes in. The team integrated an AI agent into the Kargo pipeline, called as a standard promotion step via two HTTP endpoints: /analyze/risk (analyzing the GitHub PR via MCP + claude-sonnet-4-6 to assess the risk of the change) and /analyze/diagnosis (analyzing the post-promotion state via MCP ArgoCD to detect drift or anomalies). The model has no direct access to production: it operates only on data exposed by the MCPs. The speakers’ conclusion is unambiguous: “AI does not replace the human in the loop, it makes visible what would have gone unnoticed.”
In a classic GitOps workflow, Git contains templates (Helm charts, Kustomize overlays), but what ArgoCD actually deploys, the rendered manifests from kustomize build or helm template, is never persisted. What actually runs in production therefore remains opaque: hard to audit, hard to compare between two versions, and impossible to produce as a compliance proof.
The Source Hydrator solves this by introducing the Rendered Manifest Pattern: ArgoCD renders the manifests and then automatically pushes them to a dedicated Git branch before deploying them. Concretely, you replace the source field of an Application with sourceHydrator. Each deployment then produces a Git commit containing raw YAML manifests, independent of any templating tool, which simplifies debugging (readable diff between two versions), makes tool rotation easier (no coupling to Helm or Kustomize at deploy time), and meets the audit requirements of regulated environments.
KubeCon 2026 was the stage for a long-awaited announcement: the archiving of ingress-nginx. After 8 years, 275 releases, and 19,500 GitHub stars, the repository is officially archived in the wake of the event. The Gateway API maintainers presented ingress2gateway (v1.0) to ease the transition: the tool automatically converts Ingress resources (including annotations) into Gateway API resources. The strategy remains sensible: migrate the controller first while keeping Ingress objects, then consider Gateway API as a second step. Trying to do both at once is an unnecessary risk. Bloomberg illustrated this concretely with a zero-downtime migration story moving from ingress-nginx to Istio on their multi-cluster platform, using Karmada for federation.
Gateway API version 1.5 marks a significant milestone: 5 features moved to the Standard channel in a single release, a record. Among them:
The Gateway API is no longer just the successor to Ingress: it is becoming the universal control plane for Kubernetes networking.
This is exactly what Istio Ambient Mesh demonstrates. Alfonso Ming and Jorge Turrado (Schwarz Digits, “The Good, The Ugly, and The Bad”) gave an honest review of Istio’s sidecarless mode, where L7 Waypoints are configured via the Gateway API.
The Good:
The Bad:
The Ugly:
App → ztunnel → HBONE → ztunnel → App flow completely changes the telemetry modelThe speakers’ advice: stay at L4 as much as possible. And in both cases, Ingress or service mesh, the Gateway API is now unavoidable.
This Saxo Bank talk came out of a real maintenance incident: despite configured PodDisruptionBudgets, metrics stopped flowing during a node drain. The culprit? A fundamental misunderstanding of what a PDB actually protects. A PDB only applies to voluntary disruptions going through the Eviction API (POST /eviction). A simple kubectl delete pod bypasses this mechanism entirely. And involuntary disruptions (hardware failure, kernel panic, memory or disk pressure, spot nodes being reclaimed, network partitions) ignore it too. Worse: involuntarily deleted pods continue to count toward the budget, which can block subsequent drains.
Another trap involves overly restrictive PDBs. A PDB with maxUnavailable: 0 or minAvailable: 100% blocks all voluntary evictions and can make a kubectl drain hang indefinitely. Controllers or developers automatically generating these kinds of PDBs can paralyze maintenance operations. Escape hatches exist (--disable-eviction to bypass the Eviction API, --force for unmanaged pods), but they point to a deeper design problem.

The conclusion is nuanced: PDBs are useful, but they are only one layer among many. Real resilience requires combining:
requeststopologySpreadConstraints and anti-affinity rulesPriorityClasses to avoid preemptionDo not blindly trust your PodDisruptionBudgets.
Clément Nussbaumer (PostFinance, ~35 Kubernetes clusters, air-gapped environment, strict regulatory constraints) starts from a familiar complaint: “the cluster feels slow”. Without SLOs, that feeling stays subjective and easy to dismiss. PostFinance defined 3 SLOs on the API server: availability (<0.1% 5xx/429), read latency, and write latency (<1s). Sloth automatically generates the recording rules, multi-window alerts, and error budget calculations. The immediate result: “the cluster feels slow” becomes “we burned 40% of our error budget during Tuesday’s upgrade”. The SLOs revealed three root causes in succession: bad etcd topology (each apiserver talked to all 3 members → moved to stacked topology), no etcd leader migration before maintenance, and most importantly long-lived HTTP/2 connections that were never redistributed, with a single control plane node doing all the work. The fix: --goaway-chance=0.001 (a kube-apiserver flag) to force clients to reconnect through the load balancer.
For observability, PostFinance open-sources two tools:
For testing, a Go e2e-framework runs as a CronJob every 15 minutes, covering deployments, CSI storage, networking, and RBAC, with results sent to Grafana via OpenTelemetry (clementnuss/e2e-tests).
The four key takeaways from the talk:

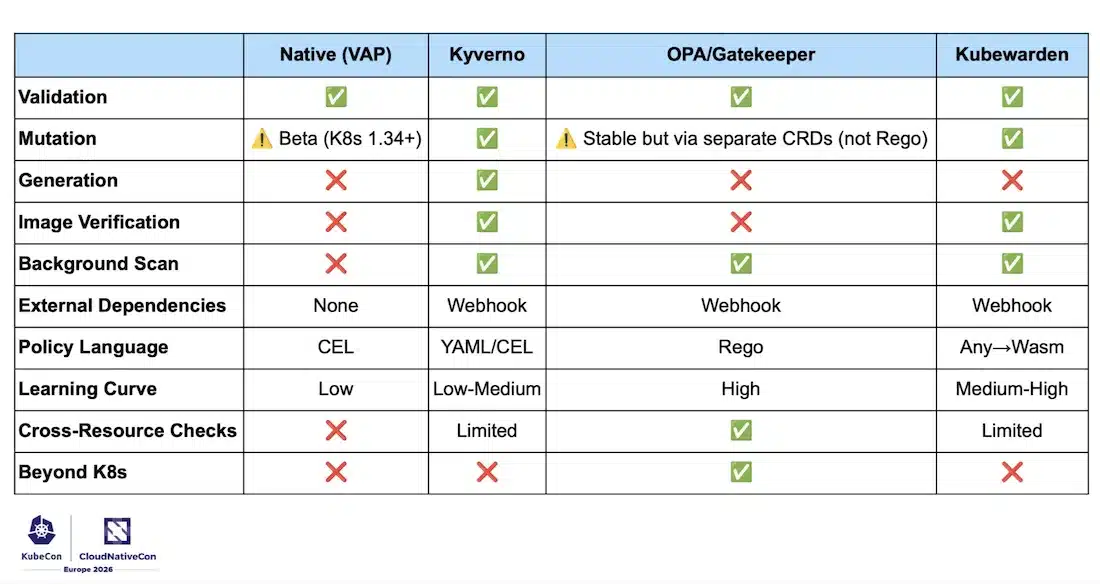
“Did you discover a pod running as root through an incident rather than through a policy?” Policy engines are not a compliance luxury: they are the operational safety net that teams often build too late. The session compares four approaches:
| Solution | Language | Strengths | Limitations |
|---|---|---|---|
| Native VAP (K8s 1.30 GA) | CEL | Inside the apiserver, zero external dependency, maximum reliability | Validation only, no mutation or generation |
| Kyverno | Native YAML | Full-featured, most accessible | — |
| OPA/Gatekeeper | Rego | Cross-platform (Terraform, CI/CD, AuthZ), cross-resource queries | Rego learning curve |
| Kubewarden | Wasm (Rust, Go, CEL, Rego…) | Any language, distribution via OCI registries | Younger ecosystem |
The real subject of the talk is what you learn operationally once you have made your choice. The three main pitfalls:
failurePolicy: Fail: blocks all deployments if the webhook is unavailable, which is secure but risky without high availabilityThe advice: start in Audit mode to measure the impact before activating enforcement, and document a break glass procedure before even your first production deployment.
Fabrizio Pandini and Stefan Büringer (Broadcom, maintainers of Cluster API) state the problem upfront: in CAPI, Machines are treated like Pods: they are immutable by design. A change triggers a delete/create cycle, with no in-place update. This model is simple, predictable, and eliminates configuration drift. But operational reality is more nuanced: infrastructure creation can be slow (and speed varies by provider), and some applications cannot properly handle a node drain.
CAPI’s response is not to abandon immutability, which remains at the heart of the project, but to find the sweet spot between the two approaches. On the immutable rollout side, CAPI v1.12 already introduces several optimizations: avoiding unnecessary rollouts, reducing pod churn, and most importantly skipping worker rollouts during multi-minor upgrades. In practice, going from v1.31 to v1.34 through chained upgrades used to mean 3 worker rollouts; with “Efficient Upgrades”, workers jump directly from v1.31 to v1.34, with 66% fewer rollouts.
For in-place updates, CAPI introduces Update Extensions: external components that handle mutating an existing Machine and report their progress back to CAPI. The user experience does not change: the operator still declares the desired state, and CAPI decides the strategy. The decision to go in-place is driven by the desired state constraints: with maxUnavailable: 0, CAPI must create an extra Machine before updating the others in place; with maxUnavailable: 1, all replicas can be updated directly without extra overhead. CAPI has no opinion on how the update is done: that is the extension’s responsibility, and it should only perform carefully validated, reproducible changes.

The maintainers’ final advice is unambiguous: Update Extensions should not be used as a workaround to avoid fixing fundamental problems. An application that cannot handle drain should be fixed: avoiding drain means fighting against Kubernetes. Slow infrastructure should be optimized. In-place updates are appropriate for changes that do not require draining or restarting pods; if the workload is going to be disrupted anyway, a classic immutable rollout is the right call.
This section lists the tools, frameworks, and projects we came across throughout the conference, in technical sessions, lightning talks, and at partner booths. It is not an exhaustive list, but a snapshot of what we saw and discussed in Amsterdam.
ResourceGraphDefinitionThis 2026 edition ran under the sign of AI, sometimes to excess. The CNCF and the Kubernetes community clearly positioned Kubernetes as the universal orchestration platform for complex, heterogeneous workloads, including AI. But the omnipresence of the topic has its limits: when a speaker announced they were not going to talk about AI, the room applauded. That detail says a lot.
AI is putting everyone under pressure, developers and ops alike. It accelerates, but it also demands solid foundations. The most convincing talks all made the point: as code, testing, review, agility, documentation… DevOps practices are not made obsolete by AI: they become even more critical. Without these foundations, the volume of generated code, opened PRs, and extra work risks producing the opposite of the intended effect: a productivity illusion, with technical debt quietly piling up.
Beyond AI, Kubernetes continues to evolve in depth. The Gateway API is establishing itself as the new networking standard, CAPI is moving toward in-place updates, and the GitOps ecosystem is maturing with increasingly sophisticated promotion pipelines, covering not just application deployment, but also infrastructure and full multi-environment lifecycle management.
Platform Engineering is everywhere, even in talks that are not explicitly dedicated to it. Backstage remains the reference for developer portals, and the API-driven trend extends beyond cloud-native to encompass legacy elements. Everything becomes orchestrable with clear contracts, not just new stacks, but also existing ones.
Yet another exciting KubeCon Europe edition, packed with announcements and concrete real-world feedback. Many things that Sokube will be looking at closely and testing in the weeks ahead.