
By Gaëtan Metzger & Yann Albou
Amsterdam, mars 2026. Pour la deuxième fois, la ville accueille KubeCon + CloudNativeCon Europe, et cette édition marque un tournant. 13 500 participants, 100 pays, et près d’un participant sur deux qui vient pour la toute première fois : la communauté cloud native ne cesse de grandir.
Ce qui frappe cette année, c’est le changement de registre. L’IA n’est plus un sujet à part : elle structure les keynotes, les architectures, les débats. Kubernetes s’impose comme la plateforme d’orchestration de l’ère agentique. Et en parallèle, un autre sujet s’est invité avec force : la souveraineté numérique, portée par le contexte géopolitique et la montée en puissance de la réglementation européenne.
Dans ce billet, on vous partage nos retours de cette édition : les chiffres clés, les grandes tendances, et une sélection de sessions qui ont retenu notre attention.
Cette édition 2026 confirme l’élan de la communauté cloud native : 13 500 participants issus de 100 pays se sont retrouvés à Amsterdam, dont 46 % pour leur toute première KubeCon, un signal fort que l’intérêt pour l’écosystème continue de grandir bien au-delà des habitués. Les chiffres complets sont disponibles dans les stats officielles CNCF pour KubeCon Europe 2026.
L’écosystème CNCF compte désormais 230 projets et a franchi le cap des 19,9 millions de contributeurs (contre 15,6 millions six mois plus tôt), soit une croissance de près de 30 % en un semestre.
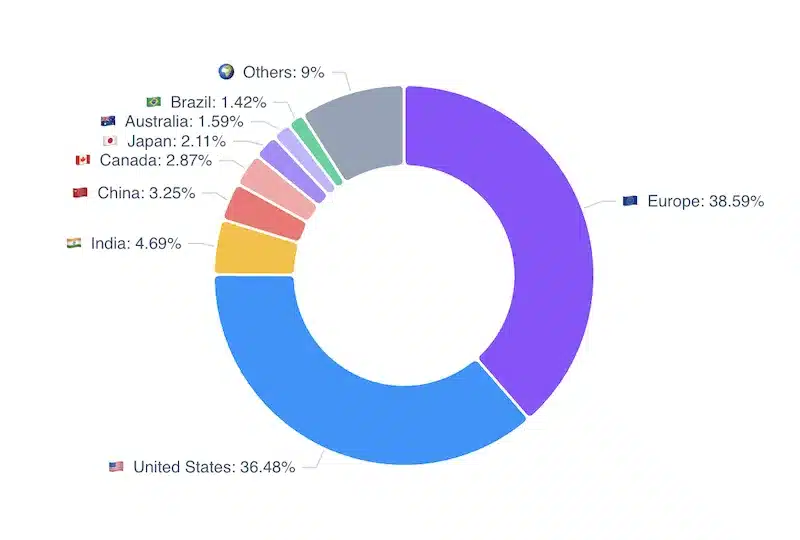
Côté géographie, les données des 12 derniers mois sur l’ensemble des projets CNCF réservent une belle surprise : l’Europe représente 38,8 % des contributions, devant les États-Unis (36,29 %). Au sein de l’Europe, l’Allemagne mène avec 9,82 %, suivie de la France (4,68 %) et de la Suisse (2,49 %). Un signal fort, particulièrement bienvenu dans le contexte de souveraineté numérique qui a dominé les keynotes de cette édition.
Côté nouveautés dans l’écosystème :
La CNCF lance également un concours de référence d’architectures dont l’objectif est de documenter des architectures réellement utilisées en production par des utilisateurs finaux. Au-delà des schémas, l’idée est de capturer les décisions, compromis et enseignements que les équipes ont tirés de leurs déploiements réels. Un bel exemple avec l’architecture de calcul scientifique du CERN, qui illustre comment l’un des plus grands centres de recherche au monde s’appuie sur Kubernetes pour orchestrer des workloads scientifiques à très grande échelle.
Enfin, les prochaines éditions de KubeCon se tiendront en Espagne puis en Allemagne.
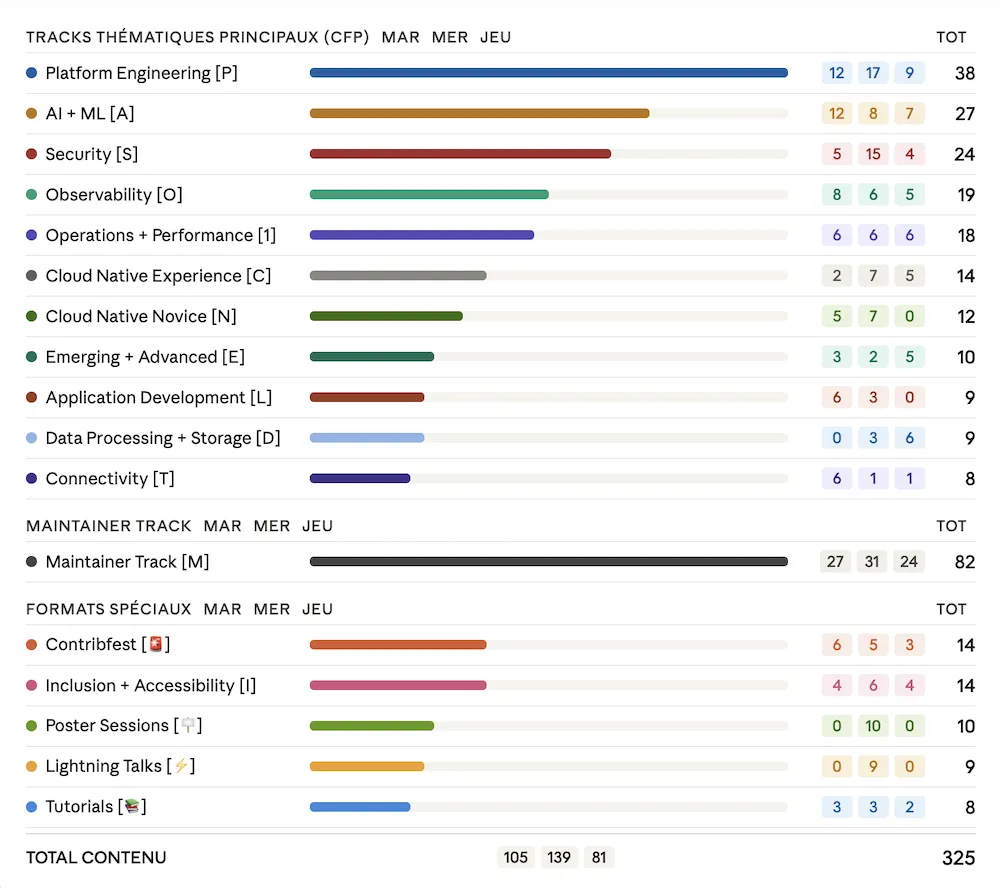
Tout d’abord l’analyse du programme montre une édition particulièrement dense : 325 sessions réparties sur 3 jours, représentant 186 heures de contenu cumulé sur jusqu’à 12 pistes en parallèle, déclinées en 17 types de tracks distincts.

La répartition par track confirme les grandes tendances de l’édition. Le Platform Engineering domine largement avec 38 sessions, suivi de l’IA & ML (27) et de la Sécurité (24). L’Observabilité (19) et les Operations & Performance (18) complètent le top 5. À noter également : le Maintainer Track totalise à lui seul 82 sessions, reflet de la maturité et de l’activité des projets de l’écosystème.
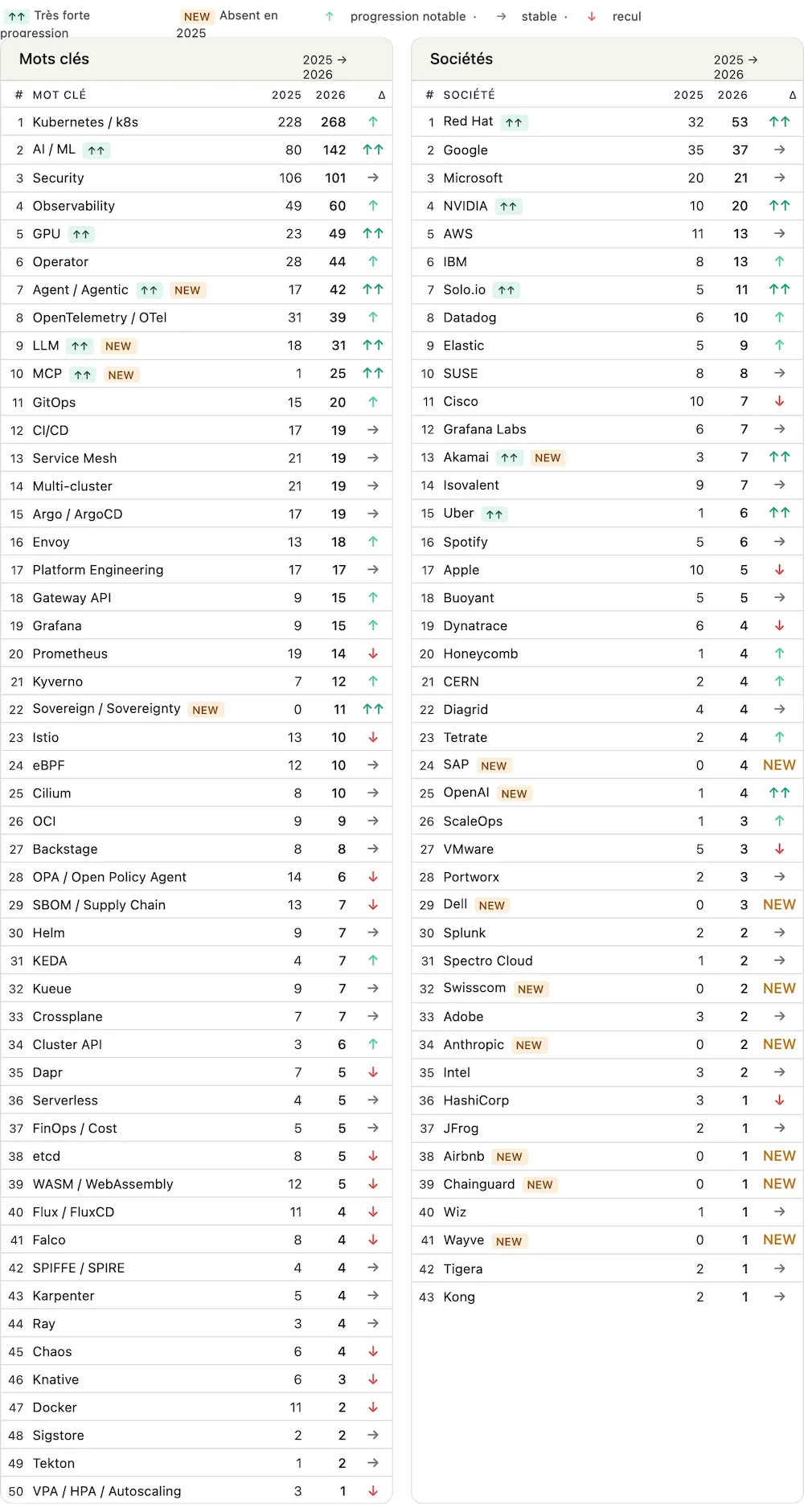
L’analyse des mots-clés les plus fréquents dans les titres et descriptions de sessions est encore plus révélatrice. Les nouveaux entrants marqués NEW parlent d’eux-mêmes : Agent/Agents explose, Souveraineté fait son apparition, et côté sociétés, OpenAI et Anthropic sont cités pour la première fois. NVIDIA confirme aussi sa montée en puissance dans l’écosystème cloud native. Le cloud native n’est plus seulement une infrastructure : c’est devenu la plateforme de l’IA agentique.
Mais au-delà de l’enthousiasme, une question se pose : cette KubeCon était-elle un peu trop teintée IA ? Certains sujets sont relégués au second plan, comme si l’écosystème cherchait à tout prix à se repositionner sous le prisme de l’intelligence artificielle. Un équilibre à surveiller pour les prochaines éditions.
Mais le message de cette édition est clair:
The Future of Cloud Native Is… Agentic. Let’s keep cloud native moving !
Le Platform Engineering était aussi clairement au devant de la scène. L’idée qui ressort : tout devient API. Des outils comme Crossplane ou Kro incarnent cette vision où l’infrastructure s’expose sous forme de contrats consommables par les équipes produit, sans qu’elles aient besoin d’en connaître les détails d’implémentation.
C’est peut-être la nouveauté la plus frappante de cette édition : la souveraineté numérique a occupé une place centrale dans les keynotes, bien au-delà des discours habituels sur la tech. Les entreprises européennes ont été mises en avant de manière inhabituellement visible, et le sujet s’est imposé comme un fil rouge transversal, porté à la fois par la pression réglementaire et par un contexte géopolitique qui pousse les organisations à reprendre le contrôle de leur infrastructure.
Deux définitions ont particulièrement marqué les esprits. Saxo Bank a reformulé la question avec clarté :
« Digital sovereignty is not where you run. It’s the freedom to change where you run, what you run on, and how it is connected — without rewriting a single app. »
La SNCF a abondé dans le même sens, préférant parler d’autonomie stratégique plutôt que de souveraineté. L’idée commune : le code reste global, mais le déploiement peut être souverain. L’infrastructure s’adapte aux contraintes légales et réglementaires locales, sans remettre en cause les applications elles-mêmes. L’open source est un levier essentiel pour y parvenir.
La question touche aussi directement l’IA : 79 % des organisations considèrent la souveraineté de l’IA comme un sujet stratégique prioritaire. En réponse, la CNCF pousse un stack cloud native ouvert pour l’IA : Kubernetes, KServe, vLLM, llm-d, avec un message clair : l’ère de l’IA boîte noire touche à sa fin.
Solo.io a illustré concrètement cette dynamique en présentant plusieurs projets lors de la conférence, dont kagent et Agent Gateway. L’Agent Registry a même été soumis à la CNCF en direct pendant la conférence. Un nouveau projet a aussi été annoncé : AgentEval, qui permet de benchmarker des agents IA à partir de traces OpenTelemetry, avant qu’ils n’atteignent la production.
Enfin, les CNCF Community Awards 2026 ont récompensé cette année la SNCF comme meilleur utilisateur final, une reconnaissance symbolique forte pour une entreprise européenne, dans une édition où la souveraineté était au cœur des débats.
Le Cyber Resilience Act (Regulation EU 2024/2847) est un règlement européen entré en vigueur en décembre 2024 qui impose des exigences obligatoires de cybersécurité à tous les produits matériels et logiciels mis sur le marché de l’UE. Il oblige les fabricants à intégrer la sécurité dès la conception (security by design), à fournir des mises à jour tout au long du cycle de vie du produit et à signaler les vulnérabilités critiques à l’ENISA sous 24h. Il s’applique à toute entreprise (européenne ou non) commercialisant des produits numériques en Europe, avec une pleine applicabilité au 11 décembre 2027.
Le CRA crée un cadre réglementaire commun à toute l’Union, simplifiant la mise sur marché à l’échelle européenne. Une conformité bien menée devient aussi un argument commercial fort face à des concurrents hors UE moins contraints sur la sécurité.
L’OpenSSF agit sur plusieurs fronts : son Global Cyber Policy Working Group produit guides et analyses pour l’écosystème open source, dont un guide pratique pour les développeurs OSS et une formation gratuite en ligne (LFEL1001) pour préparer les exigences du CRA.
Du côté de la CNCF, le TAG Security & Compliance aligne les pratiques cloud native (SBOM, conteneurs minimalistes, CI/CD sécurisé) avec les exigences du CRA, et a intégré le sujet dans son Security Slam 2026.
Les deux organisations contribuent également à l’Open Regulatory Compliance Working Group (Eclipse Foundation), qui centralise ressources et FAQ pour accompagner concrètement l’écosystème open source face au CRA.
Le CRA illustre bien la convergence entre souveraineté numérique et cloud native : la régulation européenne pousse les organisations à reprendre le contrôle de leur chaîne logicielle, et la CNCF se positionne activement comme un levier pour y parvenir, en alignant ses projets, ses pratiques et ses groupes de travail avec les exigences qui s’imposent à l’ensemble de l’industrie.
On peut voir l’IA comme un système qui repose sur trois piliers complémentaires :
En résumé : training = apprendre, inference = répondre, agents = agir.
Ces trois piliers ont des besoins d’infrastructure très différents. Le training et l’inférence sont gourmands en GPU et sensibles à la latence. Les agents, eux, nécessitent une orchestration fine : démarrage et arrêt dynamique de processus, accès à des outils externes, gestion des dépendances entre étapes, isolation et sécurité des exécutions.
C’est précisément là que Kubernetes s’impose : il offre une plateforme unifiée pour orchestrer ces trois types de workloads, du job de training au service d’inférence en passant par les pipelines agentiques.
Comme mentionné dans la précédente section, l’IA repose sur trois piliers complémentaires : le training (apprendre), l’inférence (répondre) et les agents (agir). Ce qui change profondément aujourd’hui, c’est le rééquilibrage entre ces trois phases : là où l’inférence représentait un tiers des workloads, elle en représente désormais les deux tiers. Les infrastructures doivent s’adapter en conséquence.
Pour s’assurer que les plateformes Kubernetes sont prêtes à accueillir ces workloads, la CNCF a lancé le Kubernetes AI Conformance Program, qui définit les capacités minimales requises pour exécuter des charges de travail IA/ML de manière fiable, ce qui permet aux plateformes de se faire certifier.
L’inférence à grande échelle soulève aussi de nouveaux défis d’infrastructure. Les algorithmes de load balancing traditionnels ne sont pas adaptés aux modèles de langage, qui nécessitent une distribution fine des requêtes tenant compte du contexte, de la session et de la charge des GPU. De nouvelles briques émergent pour y répondre, comme llm-d, un framework Kubernetes natif qui optimise la distribution de l’inférence sur un cluster de vLLMs, ou kgateway qui intègre nativement ces contraintes dans la couche réseau.
Un autre axe fort : l’intelligence spécialisée. Face aux coûts et aux contraintes de latence, les équipes cherchent des modèles plus ciblés, plus efficaces, capables de tourner sur du matériel hétérogène, avec des garanties de sécurité et de confidentialité. L’écosystème des agents se structure rapidement autour de frameworks comme kagent, LangGraph, HolmesGPT ou Dapr.
Cette évolution s’inscrit dans une transformation plus profonde de Kubernetes, que l’on peut lire en trois phases :
Cette troisième phase se traduit concrètement par la capacité à gérer des topologies complexes (multi-GPU, multi-cluster), à intégrer des frameworks IA variés (OpenRL pour le fine-tuning, Gemmaverse pour les modèles Gemma…) et à livrer à la vitesse de l’innovation sans sacrifier le contrôle opérationnel.
« The future of Kubernetes: from a platform for building platforms… to the nervous system for autonomous infrastructure. »
KubeCon Amsterdam 2026 a marqué l’émergence d’un nouveau sujet transverse : la gouvernance du trafic IA. Plusieurs sessions ont convergé autour de la même problématique : comment appliquer aux appels vers les LLMs et les agents IA les mêmes standards de sécurité, d’observabilité et de fiabilité qu’on applique au reste du trafic Kubernetes ? C’est dans ce contexte que le AI Gateway Working Group a été officiellement annoncé en mars 2026, avec pour mission de définir des APIs déclaratives et des standards pour le networking des workloads IA dans Kubernetes. Le groupe s’appuie sur les fondations de la Gateway API existante et en étend le périmètre pour couvrir les besoins spécifiques de l’inférence.
Un AI Gateway est concrètement une extension de la Gateway API Kubernetes pensée pour le trafic LLM. L’implémentation de référence est kgateway (anciennement Gloo), un control plane Envoy open source. Les capacités ajoutées :
Au-delà du trafic HTTP classique vers les LLMs, le cas d’usage des agents IA introduit de nouveaux protocoles : MCP (Model Context Protocol) et A2A (Agent-to-Agent). AgentGateway est un proxy open source écrit en Rust, qui s’intégrer avec kgateway et conçu pour sécuriser et observer les communications agent-to-LLM, agent-to-tool et agent-to-agent :
Bilgin Ibryam (Diagrid) et Roland Huss (Red Hat) sont co-auteurs du livre Kubernetes Patterns (O’Reilly), et cette session applique exactement ces patterns au monde GenAI. L’idée centrale : les patterns Kubernetes que vous connaissez déjà ont tous un équivalent dans une stack LLM :
| Pattern Kubernetes | Équivalent GenAI | Ce qui change |
|---|---|---|
| Controller | KServe, InferenceService CRD |
Même boucle de réconciliation, nouveau CRD |
| Stateless Service | vLLM / TGI | Poids read-only, toute réplique sert n’importe quelle requête |
| Stateful Service | Vector DB (Qdrant, Milvus) | StatefulSet + PVC, identité stable |
| Daemon Service | GPU stack (NFD, GFD, DCGM) | Un agent par nœud, couche infrastructure |
| Batch Job | Fine-tuning | Gang scheduling, démarrage all-or-nothing |
Les patterns sont les mêmes, mais à une échelle inhabituelle : quelques MB de config deviennent 800 GB de poids, un budget de readiness de 30s devient 10 minutes, et le drain window d’un rolling update passe de quelques secondes à 30s+ par requête en vol.
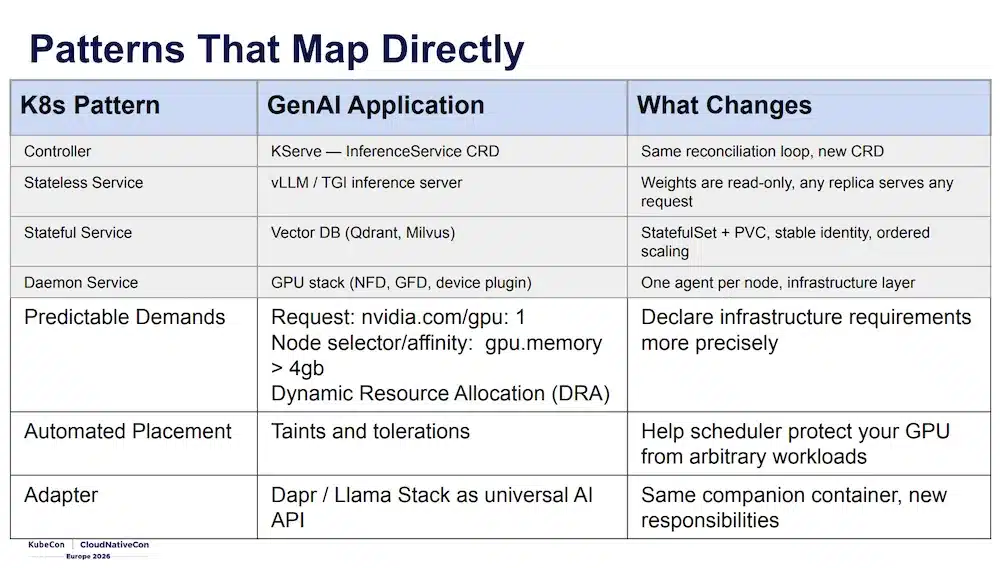
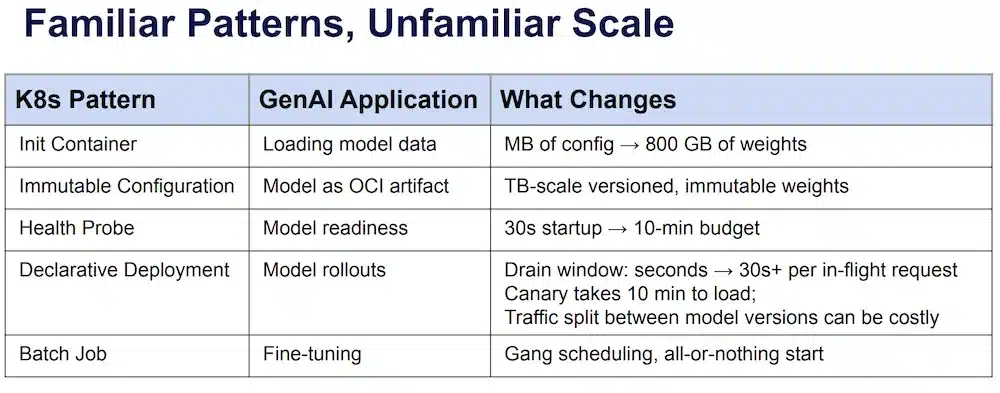
Trois nouveaux patterns émergent spécifiquement pour GenAI :
Model Data Staging : 86% du cold start time est du téléchargement de modèle. Quatre stratégies, du plus simple au plus optimal :
| Stratégie | Vitesse | Complexité | À utiliser quand |
|---|---|---|---|
| Init Container | Lente | Simple | Petits modèles, priorité à la simplicité |
| PersistentVolume (ReadOnlyMany) | Rapide | Moyenne | Plusieurs répliques, approche prod standard |
| Modelcar (sidecar) | Rapide | Complexe | KServe + vitesse, K8s < 1.35 |
| ImageVolume (beta K8s 1.35) | Rapide | Simple | Choix par défaut futur |
« ImageVolume is the endgame. »
Token-Aware Routing : le round-robin ne fonctionne pas pour les LLMs : toutes les requêtes arrivent sur POST /v1/chat/completions mais leur coût GPU varie de 200ms à 5+ minutes. La Gateway API Inference Extension répond à ce problème : un InferencePool regroupe les pods d’un même modèle, et un Endpoint Picker (llm-d) sélectionne la meilleure réplique selon la profondeur de queue, le KV cache, ou le préfixe de prompt : même préfixe → même réplique → KV cache réutilisé sans recalcul.
RAG Composition : chaque brique mappe à un primitif Kubernetes :
Plusieurs talks ont montré la même réalité : dès qu’on parle de training distribué, d’inférence à grande échelle ou d’agents, les besoins d’ordonnancement changent. Ces workloads ne consomment pas seulement du CPU et de la mémoire. Ils demandent souvent plusieurs pods démarrés en même temps, des GPUs disponibles au bon moment, et une gestion plus fine des ressources du cluster.
C’est précisément le sujet adressé par Volcano. Ce scheduler Kubernetes est conçu pour les workloads intensifs comme l’IA, le batch et le HPC. Il complète le scheduler Kubernetes par défaut avec des mécanismes mieux adaptés aux jobs distribués, aux besoins en GPU et aux traitements qui consomment beaucoup de ressources.
Volcano agit ainsi comme un pont entre Kubernetes et les grands frameworks IA comme PyTorch ou TensorFlow. Il leur permet d’exécuter leurs jobs distribués dans Kubernetes avec un scheduling plus intelligent, notamment pour les GPU, les pods interdépendants et les ressources rares.
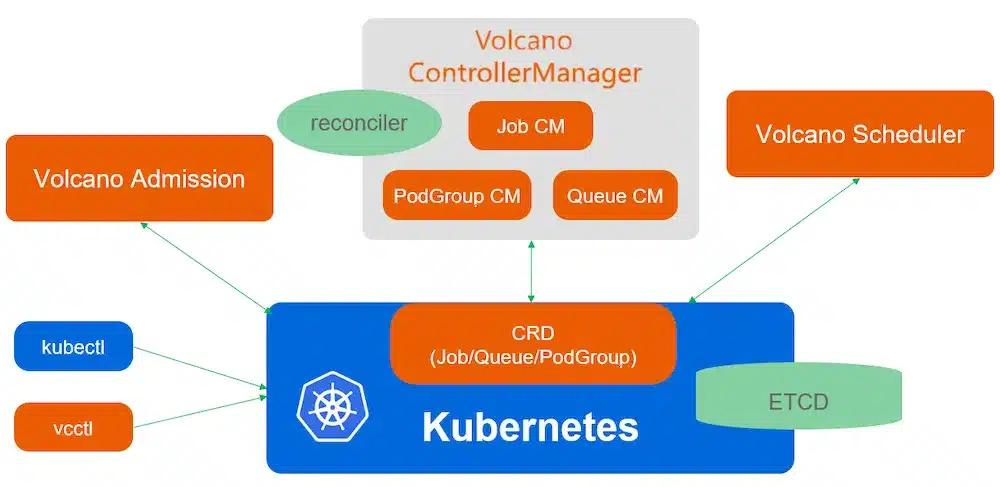
Pour compléter le scheduler Kubernetes par défaut, Volcano introduit plusieurs CRDs qui permettent de décrire plus finement les workloads batch et IA. Son architecture :
Voici un exemple simple de Volcano Job :
# vcjob-quickstart.yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: quickstart-job
spec:
minAvailable: 3
schedulerName: volcano
# If you omit the 'queue' field, the 'default' queue will be used.
# queue: default
policies:
# If a pod fails (e.g., due to an application error), restart the entire job.
- event: PodFailed
action: RestartJob
tasks:
- replicas: 3
name: completion-task
policies:
# When this specific task completes successfully, mark the entire job as Complete.
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- command:
- sh
- -c
- 'echo "Job is running and will complete!"; sleep 100; echo "Job done!"'
image: busybox:latest
name: busybox-container
resources:
requests:
cpu: 1
limits:
cpu: 1
restartPolicy: NeverL’un des messages les plus forts de cette KubeCon est que le platform engineering devient de plus en plus API-driven. L’idée est simple : au lieu de manipuler directement l’infrastructure ou de dépendre de processus manuels, les équipes interagissent avec des APIs qui exposent des services standardisés, versionnés et automatisables. Cette approche permet de mieux découpler les équipes, d’accélérer le self-service, de fiabiliser les opérations et de transformer la plateforme en véritable produit interne avec un contrat clair entre les développeurs et les équipes infrastructure.
Cette session montrait bien que Kubernetes ne sert pas seulement à orchestrer des conteneurs : il peut aussi devenir un API provider pour exposer des services d’infrastructure de manière standardisée. Grâce à ses CRD et à son modèle déclaratif, Kubernetes permet de définir des objets métiers comme une base de données, un bucket, un réseau ou une plateforme applicative, avec un contrat clair consommable par les équipes produit.
Avec Crossplane, cette logique va encore plus loin : la plateforme peut composer plusieurs ressources cloud ou internes derrière une API Kubernetes unique. Les développeurs ne demandent plus directement des ressources AWS, Azure ou GCP ; ils consomment un service abstrait exposé dans le cluster, par exemple un Database ou un ApplicationEnvironment, tandis que Crossplane se charge de traduire cette intention en ressources réelles, d’en assurer le provisioning et de maintenir l’état désiré. Kubernetes devient alors la couche d’API commune entre les équipes, avec une approche self-service, gouvernée et portable.
Cette approche s’inscrit aussi très bien dans la logique de Team Topologies. En platform engineering, l’objectif n’est pas que chaque équipe produit devienne experte du cloud provider ou de l’infrastructure, mais que la platform team fournisse des capacités prêtes à l’emploi aux stream-aligned teams. La plateforme agit alors comme un produit interne, pensé pour réduire la charge cognitive des équipes de développement.
Dans ce cadre, l’élément central est le contrat d’API. Ce contrat définit ce que la plateforme expose, quels paramètres sont disponibles, quelles garanties sont offertes et quelles limites sont imposées. Les équipes applicatives consomment une interface stable et compréhensible, sans dépendre des détails d’implémentation sous-jacents. L’infrastructure peut évoluer, changer de fournisseur ou de mécanisme interne, tant que le contrat reste stable pour ses consommateurs.
Ce modèle soulève cependant trois défis concrets, illustrés par l’expérience d’Allianz.
Le premier est celui des frontières de service et de l’ownership : qui est responsable quand quelque chose casse ? La réponse passe par des contrats clairs : le provider garantit la stabilité de l’API, le consumer valide ses inputs, ce qui permet aux messages d’erreur eux-mêmes de montrer à quelle équipe appartient le problème.
Le second, et peut-être le plus critique en pratique, est celui des breaking changes : un changement côté provider peut impacter des dizaines d’équipes consommatrices, souvent découvert trop tard, en production. La solution mise en place combine du contract testing avec du versioning, des tests qui détectent les ruptures en CI, et un mécanisme de double versioning avec webhooks, permettant aux équipes de migrer à leur propre rythme sans incident de production.
Le troisième est la dérive de la documentation : écrite une fois, jamais mise à jour, avec des exemples qui cessent de fonctionner au fil des évolutions. L’approche doc as code, avec une documentation générée depuis les annotations XRD et des exemples vérifiés en CI, permet de garantir qu’elle reste toujours à jour et adoptée.

Un talk très concret et sans fioriture sur le remplacement de VMware par KubeVirt en 2026. Le constat de départ est limpide : les coûts de la virtualisation legacy ont explosé, Kubernetes est désormais présent dans pratiquement toutes les entreprises, et le mandat au niveau C-level se résume en deux mots : « One Platform ». Résultat : 28 % des clusters de production hébergent aujourd’hui des VMs persistantes, contre 8 % en 2023. KubeVirt répond à cette tendance avec une idée forte :
« Virtualization is a feature, not a place. »
Concrètement, KubeVirt étend Kubernetes via des CRDs et fait tourner les VMs dans des Pods (virt-launcher). L’architecture repose sur trois composants (Virt-API, Virt-Controller et Virt-Handler, DaemonSet sur chaque nœud) et expose deux primitives :
VirtualMachine : la définition, comme un DeploymentVirtualMachineInstance : l’instance en cours d’exécution, comme un PodLe bénéfice immédiat : RBAC, monitoring, stockage CSI et GitOps unifiés avec le reste du cluster. Les VMs deviennent gérables avec ArgoCD/Flux, et la couche OS peut être durcie avec Talos OS ou Kairos.
Sur le réseau, le talk livre un comparatif honnête entre Cilium et Kube-OVN :
Les limites à connaître avant de se lancer :
En production, le verdict est nuancé : ✅ serveurs Linux et dev/test, ⚠️ bases SQL, ❌ Oracle RAC ou apps dépendant de dongles USB. La migration réaliste se compte en 18 mois.
« It’s not about running VMs. It’s about running applications. »

Saxo Bank opère une infrastructure hybride : des workloads cloud-native Kubernetes, mais aussi de nombreuses applications sur VMs legacy qui ne seront pas containerisées, et c’est un choix délibéré. « Tout containeriser n’a pas de sens pour le business. » Le vrai problème n’est pas la technologie, c’est le processus : provisionner du DNS, des certificats, un load balancer ou des accès Active Directory impliquait des équipes différentes, des tickets, des délais.
La réponse de Saxo est le Service Blueprint : un ensemble d’opérateurs Kubernetes qui modélisent l’infrastructure legacy sous forme de CRDs. Le workflow devient : écrire du YAML, ouvrir une PR (auto-assignée à la bonne équipe), merger, et l’opérateur provisionne. Git devient la source de vérité stricte.
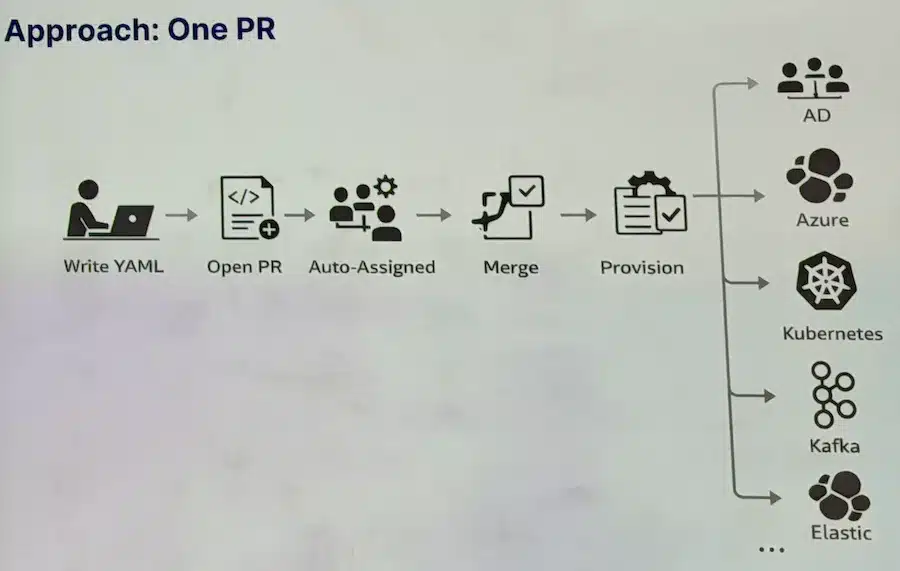
Les opérateurs gèrent l’idempotence, l’ordre de provisionnement, la récupération sur erreur et les états partiels entre domaines. Des lifecycle gates permettent de contrôler les étapes de provisionnement. L’interface développeur s’appuie sur Backstage pour exposer ce catalogue de services.
C’est une approche pragmatique du Platform Engineering : on ne repart pas de zéro, on compose avec l’existant. Kubernetes devient le plan de contrôle unifié, pas un remplacement, mais un pont entre le legacy et les workloads cloud-native.
Backstage est un framework open source, initialement créé par Spotify, qui permet de construire son propre internal developer portal. Ce n’est pas un produit figé avec une expérience unique pour tout le monde, mais un socle sur lequel chaque organisation peut bâtir un portail adapté à sa manière de travailler, à ses outils et à ses processus.
Cette flexibilité repose en grande partie sur son système de plugins. Une entreprise peut ainsi intégrer des plugins existants pour connecter son écosystème, mais aussi développer ses propres extensions pour exposer ses workflows internes, son catalogue de services, ses templates de projets ou encore ses APIs internes directement dans Backstage.

Cette volonté de modularité se reflète aussi dans l’évolution technique du projet, avec le travail mené autour du new backend system et du new frontend system. L’objectif est de rendre Backstage plus proprement extensible, plus facile à composer et plus simple à faire évoluer, afin que chaque organisation puisse assembler son portail sans être enfermée dans une architecture monolithique.
L’adoption continue d’ailleurs de croître fortement, avec plus de 4 000 adopteurs, plus de 255 plugins open source et environ 32 900 GitHub stars au moment de la présentation.
Le projet n’est d’ailleurs plus porté par Spotify seul. Backstage s’appuie désormais sur un écosystème de contributeurs bien plus large, avec plusieurs grandes entreprises qui participent activement à son évolution. Red Hat, notamment, joue un rôle important dans sa maturation et son adoption en entreprise, en contribuant à en faire une base crédible pour des plateformes développeur à grande échelle.
On voit aussi se structurer un véritable écosystème commercial autour du projet. Spotify propose désormais Spotify Portal, une offre SaaS managée autour de Backstage, tandis que Red Hat pousse Red Hat Developer Hub, une distribution enterprise et supportée basée sur Backstage. Cela montre bien que Backstage n’est plus seulement un framework open source prometteur, mais une fondation de plus en plus mature pour des portails développeur utilisés en production à grande échelle.
Backstage évolue aussi avec l’essor de l’IA. Le projet ne se limite plus à une interface web pour humains : il cherche aussi à devenir une surface d’intégration pour des assistants et des agents. Cela passe notamment par le travail fait autour de la CLI, qui facilite l’interaction programmatique avec la plateforme, mais aussi par l’adoption du MCP (Model Context Protocol) pour connecter plus facilement des agents IA à Backstage. L’idée est claire : permettre à des agents de découvrir le catalogue, interroger la documentation, déclencher des workflows ou consommer les APIs de la plateforme de manière standardisée.
La Raiffeisen Bank International (RBI) opère la plateforme Mercury : 13 clusters OKD, plus de 1000 namespaces, 70+ équipes clientes répartis sur 120 comptes AWS. La multi-tenancy repose sur trois couches d’isolation (namespace, cluster, compte AWS) selon le niveau de sensibilité. Chaque cluster dispose de sa propre instance ArgoCD, et Kargo orchestre les promotions en traversant toutes ces frontières.
Le cœur du talk porte sur une distinction souvent négligée : la promotion d’une application et la promotion d’infrastructure ne sont pas équivalentes. Une app peut être rollbackée en quelques secondes ; une ressource infra Crossplane supprimée peut entraîner la perte de données, ce qui est difficile, voire impossible à annuler. RBI a résolu ce problème avec une topologie Kargo shardée (Kargo Agent Model) : un plan de contrôle central stocke les ressources Kargo, tandis que des contrôleurs locaux (shards) les exécutent par cluster. Cela permet de définir des politiques de promotion différentes selon le type de workload, avec des portes de validation adaptées au niveau de risque.
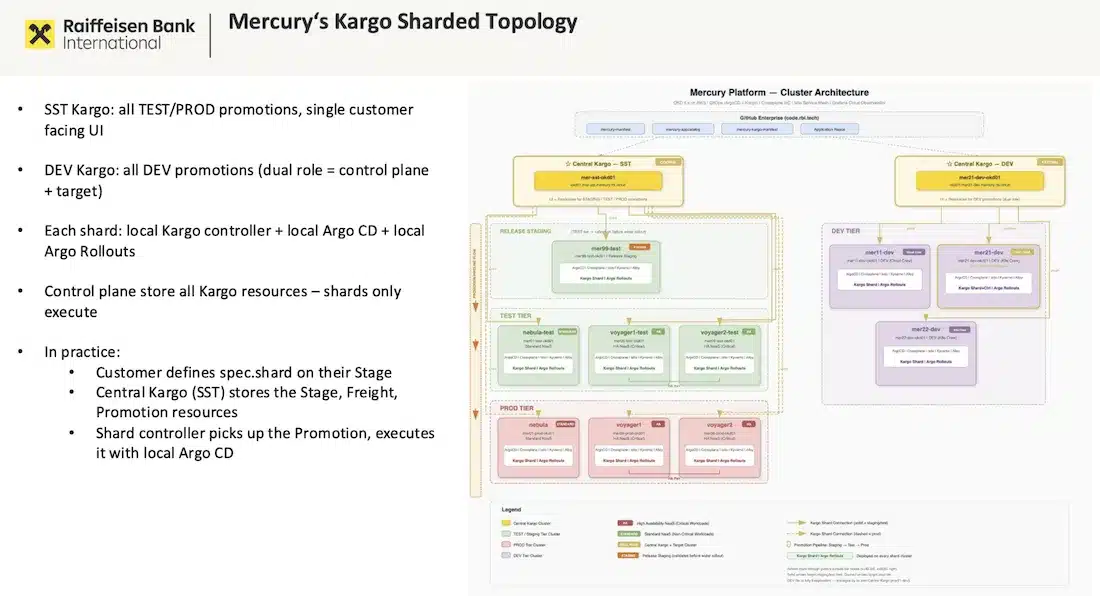
Côté Crossplane, la migration de v1 vers v2, qui étend le support des Claims namespacées à l’ensemble des ressources composites pour améliorer la visibilité et l’isolation, se fait en 3 étapes sans recréation de ressources ni downtime : activer le mode migration, créer une claim V2 qui importe les ressources existantes, puis basculer. Un gain de lisibilité important dans un environnement où chaque namespace appartient à une équipe distincte.
C’est là qu’intervient la dimension AIOps. L’équipe a intégré un agent IA dans le pipeline Kargo, appelé comme étape de promotion standard via deux endpoints HTTP : /analyze/risk (analyse du PR GitHub via MCP + claude-sonnet-4-6 pour évaluer le risque de la modification) et /analyze/diagnosis (analyse de l’état post-promotion via MCP ArgoCD pour détecter les dérives ou anomalies). Le modèle n’a pas accès à la production directement, il opère uniquement sur les données exposées par les MCPs. La conclusion des speakers est sans ambiguïté : « l’IA ne remplace pas l’humain dans la boucle, elle rend visible ce qui serait passé inaperçu. »
Dans un workflow GitOps classique, Git contient les templates (Helm charts, overlays Kustomize), mais ce qu’ArgoCD déploie réellement, les manifests rendus issus de kustomize build ou helm template, n’est jamais persisté. Ce que tourne effectivement en production reste donc opaque : difficile à auditer, difficile à comparer entre deux versions, et impossible à produire comme preuve de conformité.
Le Source Hydrator résout ce problème en introduisant le Rendered Manifest Pattern : ArgoCD rend les manifests puis les pousse automatiquement dans une branche Git dédiée avant de les déployer. Concrètement, on remplace le champ source d’une Application par sourceHydrator. Chaque déploiement produit alors un commit Git contenant les manifests YAML bruts, indépendants de tout outil de templating, ce qui simplifie le debug (diff lisible entre deux versions), facilite la rotation des outils (plus de couplage à Helm ou Kustomize au moment du déploiement), et répond aux exigences d’audit des environnements régulés.
La KubeCon 2026 a été le théâtre d’une annonce attendue depuis longtemps : l’archivage d’ingress-nginx. Après 8 ans, 275 releases et 19 500 étoiles GitHub, le dépôt est officiellement archivé dans la foulée de l’événement. Les mainteneurs de la Gateway API ont présenté ingress2gateway (v1.0) pour faciliter la transition : l’outil convertit automatiquement les ressources Ingress (annotations comprises) en ressources Gateway API. La stratégie reste celle du bon sens : migrer d’abord le controller en conservant les objets Ingress, puis envisager la Gateway API dans un second temps. Vouloir faire les deux d’un coup est un risque inutile. Bloomberg l’a illustré concrètement avec un retour de migration zero-downtime d’ingress-nginx vers Istio sur leur plateforme multi-cluster, en s’appuyant sur Karmada pour la fédération.
La version 1.5 de la Gateway API marque une étape significative : 5 fonctionnalités passent au Standard channel en une seule release, un record. Parmi elles :
La Gateway API n’est plus seulement le successeur de l’Ingress : elle devient le plan de contrôle universel du réseau Kubernetes.
C’est précisément ce que démontre Istio Ambient Mesh. Alfonso Ming et Jorge Turrado (Schwarz Digits, « The Good, The Ugly, and The Bad ») ont présenté un bilan honnête du mode sidecarless d’Istio, dont les Waypoints L7 se configurent via la Gateway API.
The Good :
The Bad :
The Ugly :
App → ztunnel → HBONE → ztunnel → App change radicalement le paradigme de télémétrieLe conseil des speakers : restez en L4 autant que possible. Et dans les deux cas, Ingress ou service mesh, la Gateway API est désormais incontournable.
Ce talk de Saxo Bank est né d’un incident de maintenance bien réel : malgré des PodDisruptionBudgets configurés, des métriques ont cessé de remonter lors d’un drain de nœud. Le coupable ? Une incompréhension fondamentale de ce que protège réellement un PDB. Un PDB ne s’applique qu’aux disruptions volontaires passant par l’Eviction API (POST /eviction). Un simple kubectl delete pod contourne entièrement ce mécanisme. Et les disruptions involontaires (panne matérielle, kernel panic, pression mémoire ou disque, nœuds spot récupérés, partition réseau) l’ignorent également. Pire : les pods supprimés involontairement continuent de peser dans le calcul du budget, ce qui peut bloquer les drains suivants.
Un autre piège concerne les PDB trop restrictifs. Un PDB avec maxUnavailable: 0 ou minAvailable: 100% bloque toutes les évictions volontaires et peut rendre un kubectl drain indéfiniment bloquant. Des contrôleurs ou des développeurs générant automatiquement ce type de PDB peuvent paralyser les opérations de maintenance. Des échappatoires existent (--disable-eviction pour contourner l’Eviction API, --force pour les pods non managés), mais elles témoignent d’un problème de conception plus profond.

La conclusion est nuancée : les PDB sont utiles, mais ne constituent qu’une couche parmi d’autres. La résilience réelle exige de combiner :
requests correctement dimensionnéestopologySpreadConstraints et règles d’anti-affinitéPriorityClasses pour éviter la préemptionNe faites pas confiance aveuglément à vos PodDisruptionBudgets.
Clément Nussbaumer (PostFinance, ~35 clusters Kubernetes, environnement air-gapped, contraintes réglementaires strictes) part d’un constat familier : « le cluster semble lent ». Sans SLO, ce ressenti reste subjectif et facile à ignorer. PostFinance a défini 3 SLOs sur l’API server : disponibilité (<0.1% de 5xx/429), latence lecture et latence écriture (<1s). Sloth génère automatiquement les recording rules, alertes multi-fenêtres et calculs d’error budget. Résultat immédiat : « le cluster semble lent » devient « on a brûlé 40% de notre error budget lors de l’upgrade de mardi ». Les SLOs ont révélé trois causes racines successives : mauvaise topologie etcd (chaque apiserver parlait aux 3 membres → passage en stacked topology), absence de migration du leader etcd avant maintenance, et surtout des connexions HTTP/2 long-lived jamais redistribuées, avec un seul nœud du control plane qui faisait tout le travail. Le fix : --goaway-chance=0.001 (flag du kube-apiserver) pour forcer les clients à se reconnecter via le load-balancer.
Pour l’observabilité, PostFinance open-source deux outils :
Pour les tests, un e2e-framework Go tourne en CronJob toutes les 15 minutes, couvrant déploiements, stockage CSI, réseau et RBAC, avec résultats vers Grafana via OpenTelemetry (clementnuss/e2e-tests).
Les quatre takeaways du talk :

« Avez-vous découvert un pod qui tourne en root via un incident plutôt que via une policy ? » Les policy engines ne sont pas un luxe compliance : ils sont le filet de sécurité opérationnel que les équipes construisent souvent trop tard. La session compare quatre approches :
| Solution | Langage | Points forts | Limites |
|---|---|---|---|
| Native VAP (K8s 1.30 GA) | CEL | Dans l’apiserver, zéro dépendance externe, fiabilité maximale | Validation uniquement, pas de mutation ni génération |
| Kyverno | YAML natif | Full-featured, le plus accessible | — |
| OPA/Gatekeeper | Rego | Cross-platform (Terraform, CI/CD, AuthZ), requêtes cross-ressources | Courbe d’apprentissage Rego |
| Kubewarden | Wasm (Rust, Go, CEL, Rego…) | N’importe quel langage, distribution via registres OCI | Écosystème plus jeune |
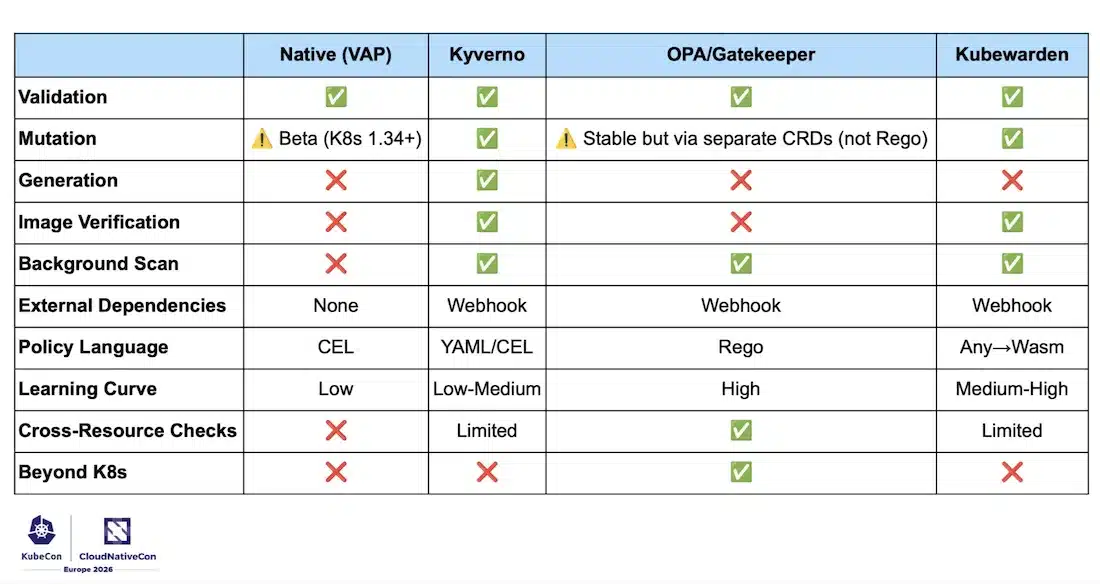
Le vrai sujet du talk, c’est ce qu’on apprend opérationnellement une fois qu’on a choisi. Les trois pièges principaux :
failurePolicy: Fail : bloque tous les déploiements si le webhook est indisponible, ce qui est sécurisé mais risqué sans haute disponibilitéLe conseil : commencer en mode Audit pour mesurer l’impact avant d’activer l’enforcement, et documenter une procédure break glass avant même le premier déploiement en production.
Fabrizio Pandini et Stefan Büringer (Broadcom, mainteneurs de Cluster API) posent le problème d’emblée : dans CAPI, les Machines sont traitées comme des Pods : elles sont immutables par conception. Une modification déclenche un cycle delete/create, sans mise à jour en place. Ce modèle est simple, prévisible et élimine la configuration drift. Mais la réalité opérationnelle est plus nuancée : la création d’infrastructure peut être lente (et la vitesse varie d’un provider à l’autre), et certaines applications ne savent pas gérer proprement un drain de nœud.
La réponse de CAPI n’est pas d’abandonner l’immutabilité, qui reste au cœur du projet, mais de trouver le sweet spot entre les deux approches. Côté rollouts immutables, CAPI v1.12 introduit déjà plusieurs optimisations : éviter les rollouts inutiles, réduire le churn de pods, et surtout skipper les rollouts de workers lors d’upgrades multi-mineurs. En pratique, passer de v1.31 à v1.34 en chained upgrades impliquait 3 rollouts workers ; avec les « Efficient Upgrades », les workers sautent directement de v1.31 à v1.34, soit 66% de rollouts en moins.
Pour les mises à jour en place, CAPI introduit les Update Extensions : des composants externes qui prennent en charge la mutation d’une Machine existante et rapportent leur progression à CAPI. L’expérience utilisateur ne change pas : l’opérateur continue de déclarer l’état désiré, CAPI décide de la stratégie. La décision de passer en in-place est pilotée par les contraintes du desired state : avec maxUnavailable: 0, CAPI doit créer une Machine supplémentaire avant de mettre à jour les autres en place ; avec maxUnavailable: 1, toutes les replicas peuvent être mises à jour directement sans surcharge. CAPI n’a pas d’opinion sur comment l’update est faite : c’est l’extension qui en est responsable, et elle ne doit opérer que des changements soigneusement validés et reproductibles.

Le conseil final des mainteneurs est sans ambiguïté : les Update Extensions ne doivent pas servir de contournement pour éviter de corriger des problèmes fondamentaux. Une application qui ne supporte pas le drain doit être corrigée : éviter le drain, c’est lutter contre Kubernetes. Une infrastructure lente doit être optimisée. Les in-place updates sont pertinents pour des changements qui ne nécessitent ni drain ni restart de pods ; si le workload est de toute façon perturbé, autant faire un rollout immutable classique.
Cette section recense les outils, frameworks et projets que nous avons croisés tout au long de la conférence, que ce soit dans les sessions techniques, les lightning talks ou sur les stands des partenaires. Ce n’est pas une liste exhaustive, mais un instantané de ce que nous avons pu voir et discuté à Amsterdam.
ResourceGraphDefinitionCette édition 2026 s’est déroulée sous le signe de l’IA, parfois à l’excès. La CNCF et la communauté Kubernetes ont clairement positionné Kubernetes comme la plateforme d’orchestration universelle pour des workloads hétérogènes et complexes, y compris les workloads IA. Mais l’omniprésence du sujet a ses limites : quand un speaker annonçait qu’il n’allait pas parler d’IA, la salle l’applaudissait. Ce détail dit beaucoup.
L’IA met tout le monde sous pression, développeurs et ops confondus. Elle accélère, mais elle exige aussi des fondations solides. Les talks les plus convaincants l’ont tous rappelé : as code, testing, review, agilité, documentation… Les pratiques DevOps ne sont pas dépassées par l’IA, elles deviennent encore plus critiques. Sans ces bases, la masse de code généré, de PRs ouvertes et de travail supplémentaire risque de produire l’effet inverse de celui escompté : une productivité en trompe-l’œil, avec une dette technique qui s’accumule en silence.
Au-delà de l’IA, Kubernetes continue d’évoluer en profondeur. La Gateway API s’impose comme le nouveau standard réseau, CAPI progresse vers les mises à jour in-place, et l’écosystème GitOps gagne en maturité avec des pipelines de promotion de plus en plus sophistiqués, couvrant non seulement le déploiement d’applications, mais aussi l’infrastructure et la gestion complète du cycle de vie multi-environnements.
Le Platform Engineering est omniprésent, même dans les talks qui ne lui sont pas dédiés. Backstage reste la référence pour les portails développeurs, et la tendance API-driven s’étend au-delà du cloud-native pour englober les éléments legacy. Tout devient orchestrable avec des contrats clairs, pas seulement les nouvelles stacks, mais aussi l’existant.
Encore une édition KubeCon Europe passionnante, dense en annonces et en retours d’expérience concrets. Beaucoup d’éléments que Sokube va regarder de près et tester dans les semaines à venir.