By Vincent Zurczak.
This article starts a series of blog posts about working with several Kubernetes clusters. This series is an opportunity for the SoKube team to share and discuss various aspects, from design to operations, but also financial and organizational concerns.
Before going any further, maybe would it be appreciable to remind when such a case is met. We can classify these situations in two categories:
- Architecture and robustness motivations
- Business motivations
Let’s detail them.
Architecture and Robustness Motivations
This first category is related to building robust infrastructures, with fail-over and security as the primary focus. Three use cases can be highlighted.
One cluster per environment
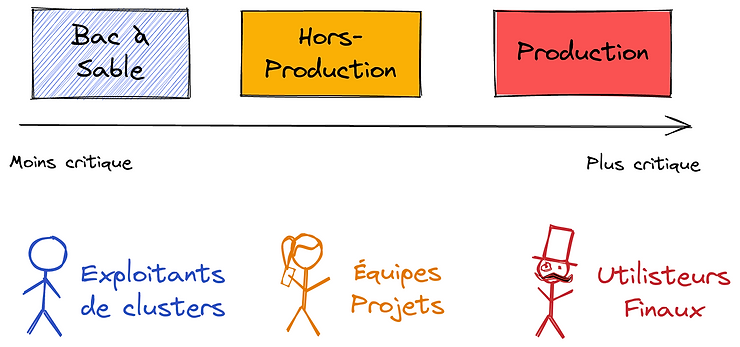
The most common case is having one K8s cluster per environment, or environment type. The minimalist approach consists in having 3 clusters:
- One dedicated to production, with critical operating conditions and where any incident can impact the business.
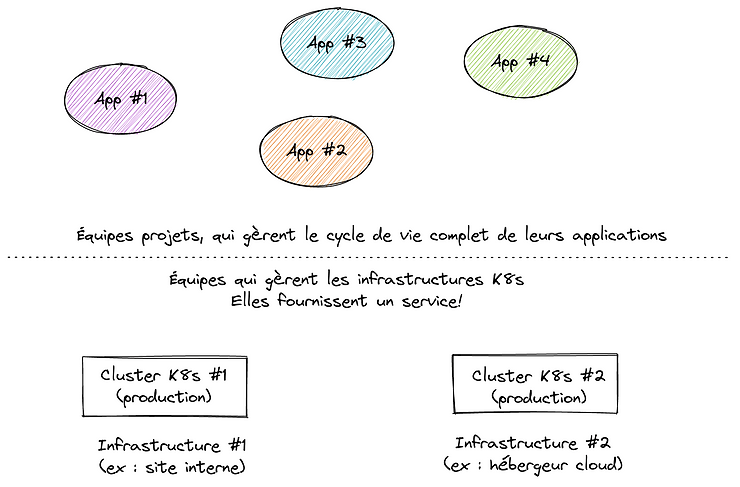
- Another one used for non-production environments. This is where project teams experiment, test and prepare project versions before production. Depending on the organization, one can choose between a single non-production cluster that hosts several environments (by using K8s namespaces, quotas and network policies) or several non-production clusters (one per environment), or any combination. The main idea here remains the segregation of production workloads.
- The last one is dedicated to operations testing / sandbox. This is the playground for clusters administrators to experiment changes and upgrades. Since there is no real users on it, they are free to break it and rebuild it, continuously in the best possible scenario. When the deployment process is standardized and industrialized, this cluster can even be ephemeral: it is deployed only when changes are planned on other clusters, and destroyed once these changes have been successfully tested.
Again, 3 clusters should be seen as a minimum, each one with different concerns.
The interest of having several clusters clearly lives in isolation (non-production should never been able to impact the production) and maintenance stages. Upgrades are first tested on the operations testing / sandbox cluster. Once done, they can be applied to the non-production one(s) first, and once the process is mastered and well-established, it can be applied to the production cluster. Upgrades are thus applied progressively, from the least critical cluster to the most critical one. This structure and the progressive approach reduce critical errors and allow new comers in the operations team to gain confidence. Eventually, it provides the right balance with resource usage (which can be shared amongst projects) and ease of governance (each cluster having its own scope and SLA).
K8s provider change
A second use case frequently met is about K8s providers change. As an example, migrating from OpenShift 3.x to Rancher (or OpenShift 4.x – as there is no built-in migration solution between the two major versions), or moving to a cloud solution like GKE, EKS, AKS… The most efficient strategy here is to have both infrastructures coexisting for a given amount of time. This period allows projects to organize and schedule their migration. The implication for cluster administrators is to manage multiple infrastructures at the same time. And it obviously requires more nodes and resources during this transition.
Multi-sites deployments
Another situation that fits in this category is about multi-sites deployments. We here consider these sites are separated by at least 1 kilometer. The idea is to tolerate the loss of a data-center or physical site (e.g. with active/active or active/passive strategies). It can also be motivated by business requirements for projects, where high-availability of applications is required. In this case, the operations team may think several clusters are the best solution to meet these expectations.
Multi-sites deployments can take several shapes:
- Federated K8s clusters are one option but are not considered mature yet.
- For companies with their own data centers, some have an excellent (private) network connection between their sites. They can thus deploy a single cluster over a stretched infrastructure (e.g. a VMware stretch cluster), that abstracts the physical resources from several sites as those of a single one. Fail-over is then managed by the virtualization solution.
- Some cloud providers also provide availability zones in a same region: these zones guarantee I/O performance and can host a single cluster, although not everything run in the same place. It is the cloud variant of stretched infrastructures.
- Another solution is to run independent clusters in different locations. Applications deployment strategies then rely on mirroring, distributed systems or disaster recovery mechanisms or a mix of all these things. This approach allows hybrid hosting (e.g. different cloud providers, or on-premise + cloud hosting, or even different on-premise deployments). Such an organization is efficient only when responsibilities are clearly defined, e.g. when project teams are in charge of deploying and operating their projects, while the infrastructure teams strictly and only manage the clusters. It reflects the paradigm change introduced by cloud computing more than 10 years ago, with horizontal roles and responsibilities. Clearly, this last option requires a higher level of maturity, not only technical, but also organizational. Despite the Dev(Sec)Ops trend, many organizations are still not ready for this and keep on considering infrastructure management and production run as a common package (which is why many DevOps job offers somehow are written for system administrators mastering automation tools and technologies).
Business Motivations
The second category that can motivate managing several K8s clusters is related to business requirements. Several situations can be met here, but it starts with the business willing to address a specific market, which implies running services for these customers.
- Obviously, the first situation is when the business contractually agreed to host services in a specific geographical area or with a specific hosting company. That can be part, as an example, of requirements expressed in a call for tenders. This situation is often met with Software editors and solutions providers. The motivation for customers can be trust and legal issues, such as data privacy considerations.
- A variation of this use case is when the business must host services in a specific geographical area for legal reasons. As an example, in Switzerland, the regulatory office for insurances and banks (FINMA) requires all sensitive data (personal and health data but also financial ones) and the code that access them to be located in Switzerland. In the same way, web sites hosting data of Russian citizens must be located on the Russian territory. In Australia, the same thing applies to Health data that must be stored on the national soil. Notice GDPR is a little bit less strict: it states European people must be able to keep the control over their data, be it with a service provider or its subcontractors. Exchanges with external territories are possible, provided they are considered transparent and validated by the EU authorities (through international agreements). But GDPR can be a motivation for European companies to constraint hosting possibilities in call for tenders (we fall back in the previous case). This must be distinguished from data protection, as GDPR does not protect against the American Cloud Act and its worldwide equivalents. In this last case, beyond data hosting, it is necessary to filter the tenders.
- Another situation is when the business targets a specific market with network issues. Several countries in the world apply censorship or some kind of control over the internet. This can impact the performances and the user experience as some services or protocols may not work appropriately when located outside the country. Unsuitable infrastructures can also cause similar issues. All of this can limit the access to markets. Going in or not is a business decision. But in these situations, hosting the services in the local area may be the only technical viable option.
- A last case, less exotic, is when different business area coexist within a same organization but must remain isolated from each others. As an example, big groups may have systems dedicated to national (or local) activities and a distinct one for international activities. Different legislation, different applications and different responsibilities can lead to distinct infrastructures.
Single clusters?
We have listed many situations that illustrate working with several K8s clusters.
Reality is in general a combination, whose mix depends on the organizations. As an example, one can easily imagine having a set of clusters (production / non-production / operations testing) on-premise and another set on a cloud provider, each one targeting a different market or sets of customers. And maybe at some time, there will be a migration to another K8s solution, which will imply managing a third set of K8s clusters temporarily. Working with several K8s clusters in fact appears as the norm and not as an exception.
This being said, one could wonder whether there are situations where a single K8s cluster fits.
There are actually very few of them. The most obvious one is when working on a proof of concept and local development (in this latter case though, a shared cluster will make more sense when the team grows). At SoKube, we have also met several times proof of concept clusters that had become production clusters. For costs reasons, it had been decided to hold a single cluster and separate environments by relying on K8s namespaces, quotas, networking policies and node labels. Although it appears acceptable for resources isolation, it introduces a huge risk on maintenance operations, as a failed operation will impact all the environments, including the production. Starting with a single K8s cluster remains possible, but should only be seen as an intermediate stage. Once we target production, several clusters will be necessary, eventually.
Keeping this in mind, teams should prepare themselves to standardize and normalize their K8s setup. A K8s cluster should not be a jewel you patiently polished and you do not want to touch anymore. Instead, companies should adopt a factory approach as soon as possible, to build (and rebuild) identical shiny jewels. This is a whole topic we may investigate in other blog posts of this series.
If you are curious about multi-clusters with K8s, here are valuable readings we also recommend:
And you might be interested by K8s virtual clusters: they are not mature yet, but they might open new doors in the future.
