By Yann Albou.
GitOps is now a well-known approach for the delivery of your software, but it doesn’t provide neither a frame to represent the different target environments nor a solution to propagate changes from one stage to the next. So what are the solutions to describe our Dev, QA or Production environments and especially how to propagate changes from one environment to another in efficient, automated and secure ways? For french speakers you can watch the talk I did on that subject at DevOps D-Day : GitOps & the deployment branching model – Yann Albou – DEVOPS D-DAY #6
GitOps intro
We’ve already covered the concepts of GitOps in a previous blog post, so if you’re not already familiar with GitOps it might be a good way to get started with GitOps before: GitOps and the Millefeuille dilemma Below is a quick summary of the GitOps principles:
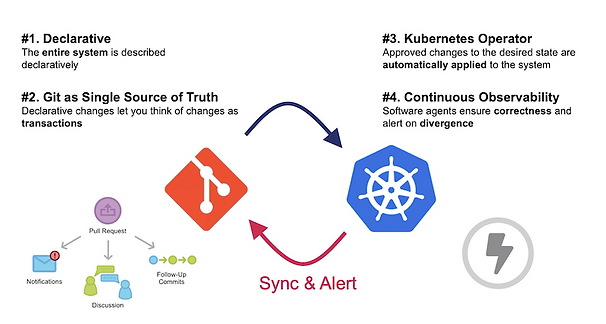
Based on those 4 principles there is no hard rule except:
- Everything should be defined in a Git repository (depending on whether you are a GitOps purist or not, there could be some exceptions such as credentials stored in an external vault)
- Don’t store configs as environment variables in your CI or CD tool
- You should promote artifacts, not source code
- Respect idempotency principles and immuability (which also encompasses external dependencies and services)
- No one-size-fits-all solution

Since its inception in 2017 by Weaveworks, most of the books on the GitOps topic describe the concepts behind extremelly well, but remain blurry on most practical aspects:
- How to manage dynamic resources (Autoscaling, Canary deployment, …)?
- How to perform tests with a real deployment in the CI?
- What are the best rollback practices (revert, commit rollback,…)?
- How to make observability at a higher level? Can Continuous Deployment happen naturally in GitOps (PR automation required)?
- How to manage secrets in Git?
GitOps remains a set of principles, and as we’ve seen, a lot of details remain up to the DevOps to figure out… In this blog post, we will focus on two aspects only: the representation of the target environment and the promotion of releases.
GitOps doesn’t provide neither a framework to represent the different environments nor a solution to propagate changes from one stage to the next.
Target env
With GitOps the representation of the target environment on which to deploy applications is usually: Dev, Int, QA, Prod.
But how can GitOps help us to manage the changes to these environments?
Branching Model for target environments
I consider as a best practice to use separated git repos for the application source code and for the application/system description (yaml, Helm, kustomize, etc..), for various good reasons:
- These are 2 different lifecycles in terms of update, versioning and release: changes in one do not necessarily imply changes in the other one
- Security aspects with RBAC apply differently
- CI/CD pipelines for the source code and for the application manifest are truly different, although their structure might be similar in essence (pre-flight, quality, security checks, validation, tests, post-flight).
- Branching models are differents: For a source code repo we will consider GitFlow (maybe not!), Git Simple Flow Github flow, GitLab Flow, … depending of the needs in terms of release branches, support branches, trunk based development, multiple versions and multi-tenancy in production. On the deployment repo side the needs are diffrents and related to configuration management in each target environment.
- When using multiple applications you may need a generic system/app configuration that cannot be stored in a single Git application repository (e.g. when releasing multiple micro-services together)
- Mixing Git logs corresponding to application commits with deployment changes is a bad idea that could lead to the history of deployment being hidden.
So the goal of this blog post is not to describe the git branching model for managing source code but to focus on the deployment branching model of your application or your product.
Assuming the deployment of a Springbok backend into a Kubernetes cluster, the configuration may look like the one below:
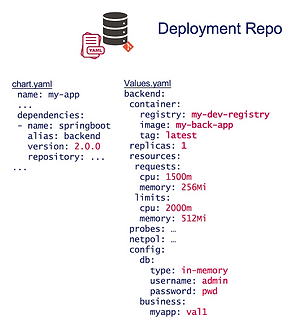
What are the possible options to represent these manifest deployments in different target environments?
- 1 environment per Git repository
- 1 environment per branch
- 1 environment per directory or file
Let’s describe each option, the pros and cons.
1 environment per Git repository
The one-repository-per-environment /cluster approach (recommended by Jenkins X, btw) is depicted below:
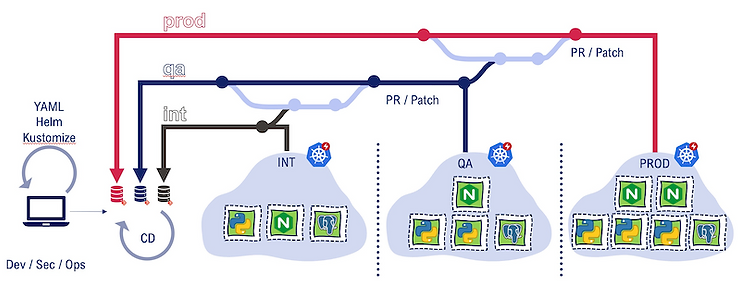
Pros:
- Strong Isolation: in terms of configuration, security and permissions this solution provides a strong isolation so that we can have different groups of users and administrators using basic git commands without relying on branches, merges and using external plugins.
Cons:
- Administration: each Git repository (i.e target environnement) needs to be setup and administered which means time and management (Configuration, Security settings, backup, …), although it could be automated.
- Pull request: you can only submit pull requests between repositories that have been forked from each other (same ancestor). Promotion won’t be too difficult as long as the differences between the previous environment don’t diverge too much. Otherwise conflicts will be recurring
- all the other cons of the next solution
I won’t describe this solution in more detail because it has too many disadvantages compared to the following solutions.
1 env per branch
Instead of relying on git repositories, a common way of representing the target kubernetes environment is to map each target environment to a specific branch inside a single Git repository:
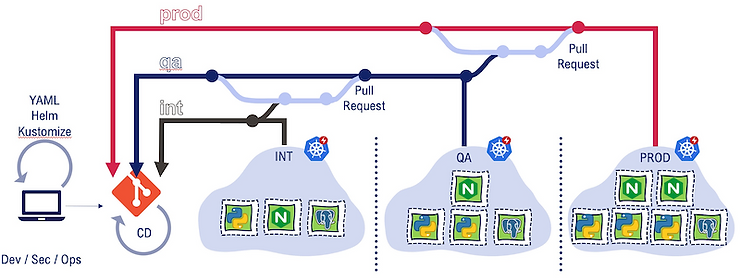
Pros:
- A simple filesystem structure that represents a single set of resources
- A cluster is modified by modifying its branch
- Divergent branches or divergent clusters/environments can be easily detected via git diff
- RBAC per branch is easy to setup so that you can have a dedicated team with higher priviledge on a specific branch. Typically it is possible to configure some options like "Allow to merge", "Allow to push" for a specific group, … These branch protection rules are tool-specific features and vary from one vendor to another (GitLab, Github, Bitbucket, …).
Below figure highlights the branch/environment differences:
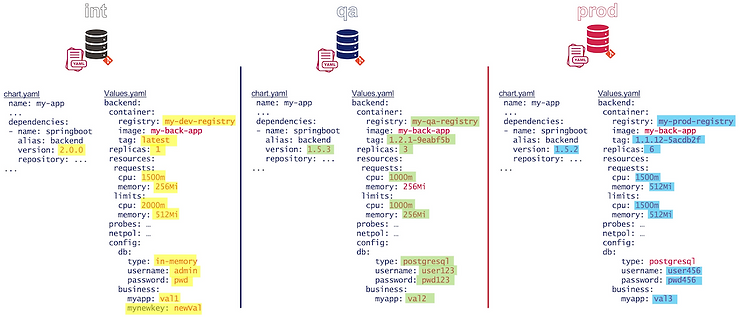
Cons:
- Pull Request process is complicated by having to choose the correct branch as the comparison base/merge target: The promotion order, Dev to QA to Prod, is not handled by Git.
- Some changes will need to be merged to all branches: It requires extra effort to keep all branches in sync (in case of hotfixes or configuration changes).
- Divergent branches will potentially cause merge conflicts: It opens the gates for people to do commits to specific branches and include environment-specific code.
- The consequence of the 2 previous points is that it is necessary to respect the flow of propagation of the changes (ie: Dev -> test -> prod) to avoid these problems of merge and conflict … Which makes difficult the usecase of direct patch in Prod because for example when the test env is frozen.
- Promotion of structural new element is harder with branching model: weither helm is used or any other templating framework, the need to add new elements in your templating (new parameter, delete config, …) is conventional. The question is how to promote this change in all environments? With a branching model approach, it is harder to find a mecanism or ask people to do it. Either there will be an oversight or a bad config
- Not a scaling solution: In this example, only 3 environments are described, but things get more complex as the environments increase.
1 env per directory or file
Another solution is to have one Git repository using only the main branch. And inside this main branch have one directory or one file per environment (For example, a full yaml file containing all environment specifics, such as a helm value.yaml file). Promoting through git is always something that can be complicated if the percentage of differences between environments is important. And this is common in real life situations. This solution is a way to avoid this promotion headache!
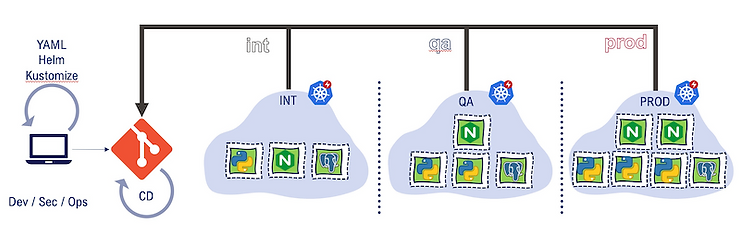
Pros
- Simpler branching structure: a single branch means no risk of merge conflicts
- A cluster is modified by modifying its directory (add/remove)
- Pull Request process is simple: branch off master, merge back to master
- Multi-cluster updates are simpler: side-by-side comparison of cluster state in the repo, copy-paste changes between files
- Ability to factorize between environment for common parameters or default parameters
- Promotion of structural new element is easier: promoting a new structural change (like a new parameter mandatory for your application) is easier to organize inside a unique branch. When a Dev or an Ops adds a parameter, she/he is responsible for the consistency across all environments.
- In this situation, all keys are not necessarily valued by the dev
- An automatic consistency process should be put in place through a pre-flight check process in the CD.
- Ability to switch from one env to another: flow not necessarily linear: DEV / INT / QA / PP / PRD. But the fix is not necessarily on all env (merge pb in other solutions)
- Simplified env duplication: creating or duplicating a new env from another is easier: no git or branch manipulation. In addition, tools like ArgoCD or Flux make it easy to manage this kind of situation.
Cons
- Divergent environments may be harder to detect (Cannot rely on default git tools for diff comparaison)
- RBAC is not out-of-the-box, need to rely on a specific solution to apply different permissions between dev directory and your prod directory (Codeowner is a well known plugin to meet this need that exists on GitLab, Github, Bitbucket, …)
- Common parameters are the same for all envs, so the risk of applying an unintentional feature or patch in production is therefore higher and could break your prod ! To avoid this situation, backward compatible modifications are advised.
- A "bureaucratic" drawback could be a way of working much further away from an ITIL mode, in which the isolation of operations by branches is more natural for RACI matrix or strict change control. But here we really get into DevOps principles!
Mixed approach
While having common parameters is both more consistent and easier in terms of operations, it also adds a certain risk on some situations and asking for backward compatibility is not as easy as it sounds (especially in terms of testing).
To solve this kind of issue, nothing prevent us of having a mixed approach between this "1 env per directory or file" and a specific Git flow pipeline with some principles from existing Git Flow pipelines (but not everything to adapt to this need).
This means that a main branch containing 1 directory or file per environment still exists (as in the previous solution) and that other branches (hotfix, release branch, …) could also exist to cover certain more complex situations.
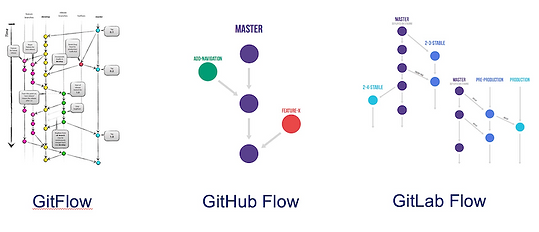
It could be the most relevant option to address the more complicated usecases like hotfix, Release branch, several versions of our software in production, product approach, …
For instance the Hotfix in production is a common usecase but not easy to achieve depending of the context. To test a fix before applying it in production, is there a pre-prod environment? Or can we create environments on the fly? And if so, how do the patch is applied there? Having a Git Flow pipeline where the main branch represents the production and a hot-fix branch (where the fix is validated) will definitely help on those aspects!
These approaches are therefore not mutually exclusive, on the contrary, they are complementary and even mandatory for certain situations.
What’s interesting is being able to simply start with a "1 env per directory or file" approach and add complexity as needed. And this choice can be made per Git repository, it is not necessary to have a global approach for the whole company.
It would be necessary to describe more in depth this part which requires much more explanations in the implementation and the operation (Next blog…).
Tooling ?
Several tools can help us to compose and apply a working GitOps model: like: Argo, Flux, Helm, Kustomize, …
ArgoCD and Flux are the tools in charge of mapping between the representation of the environment in Git and the actual deployments. They support all of the approaches described here and also add some really cool features like the ability to dynamically create an env in a generic way (i.e. adding a directory or branch will automatically discovered and deployment will begin…)
As an example, have a look at this repo which combines ArgoCD + Kustomize + Helm for the "1 env par directory of file":
sokube-io / product-demo / GitOps kustomize-helm-sample
Opiniated solutions:
Some opiniated tools/solutions exist to bootstrap and manage GitOps repository.
- Argo autopilot: argoproj-labs/argocd-autopilot
- "New users to GitOps and Argo CD are not often sure how they should structure their repos, add applications, promote apps across environments, and manage the Argo CD installation itself using GitOps."
- Kam (From RedHat): redhat-developer/kam
- "The GitOps Application Manager command-line interface (CLI), kam, simplifies GitOps adoption by bootstrapping Git repositories with opinionated layouts for continuous delivery. It also configures Argo CD to sync configurations across multiple Red Hat OpenShift and Kubernetes environments"
- Jenkins X: Jenkins X – Cloud Native CI/CD Built On Kubernetes
- "automate the continuous delivery of change through your environments via GitOps and create previews on Pull Requests to help you accelerate"
- More that just GitOps tools: Kubernetes platform, Tekton pipelines for CI/CD, PR and ChatOps system (jenkins-x/lighthouse)…
- Will not be production ready
These solutions are practical to easily start and to provide a working GitOps model, but they require a strict adherence to their underlying model, and a customization to a divergent model will prove either impossible or difficult.
In all cases, it is important to understand how these solutions work and to validate whether it fits well in your deployment model.
Other important considerations
Multi-app Repo and Product
Another topic related to the approaches described previously is what is the scope of the repository? Should we have one repository per component (a backend, a microservice, a frontend,…) or should we consolidate all components into one single repository?
Here are some possibilities when we talk about the aggregation of these repositories:
- Mono-repo: one repo with all your applications inside so that you have a global view with a global versionning. It needs a good organizations and makes RBAC more complicated.
- Repo per team: All applications, services managed by a team are inside one repo. It gives a higher level of autonomy to the dedicated team.
- Repo per Product/Service/Application: It is a fine-grained solution that gives more control over the previous one with an emphasis on the product approach.
We won’t cover these aspects here (probably in another blog post).
Multi-tenancy
Most commonly, there is one instance only of the application in production, which translates to a small number of target environments (Dev, Int, QA, Prod, etc)
But in some situations, the application needs to be deployed as many times as there are tenants. For instance a tenant could be a country (a customer, a team, …) and the same application (binary, container) needs to be deployed for each country but with a different configuration.
The same question applies here on how to represent tenants to manage deployments. And the same solutions could be proposed but with some specificities:
- Factorization is more important in this situation because there are probably common parameters to group together for the set of tenants or a subset.
- Security and isolation between tenants could be very important and this affects the management of repositories or branches.
- RBAC could be more complicated to manage in case of dedicated RBAC per tenant and per environment.
- Promoting change is no longer a linear process (Dev to Int to QA to Prod). With a multi-tenant approach, we can deploy a specific version of a tenant in Dev, test or prod and the rest of the tenants with other versions.
- Using a GitFlow pipeline is appropriated to manage more complicated situations
On-the-fly environments
The ability to create on-the-fly environments could be a game-changer in what is described here!
If an application is easy to deploy (few dependencies, low resource/data usage), the testing process is greatly simplified.
Furthermore, every feature can be easily tested in isolation, which enables a shift to next step: "Progressive Delivery".
Delivering a bundle of features to a target environement required the usage of one environment per file/directory/branch. With progressive delivery, features in production are introduced with feature flags on a single branch (aka as trunk-based development)
It is a more advanced subject that requires maturity on the development and delivery processes.
Conclusion
One can only appreciate the benefits of GitOps in terms of productivity, developer experience, stability, reliability, auditing and security. But GitOps remains a philosophy / method / set of principles, and as the devil is always in the details, teams have to figure out how to represent their environments in their repositories and how to promote releases.
GitOps is mostly a question of configuration management, Git branching model and Git RBAC. Some criteria will help the teams to pick the most appropriate approach for their use cases:
- Lifecycle of the application – Drives the design of the git branching model.
- Configuration Management – How is the deployment/management code of the application organized, and changed.
- Complexity level of your deployments
- Need for factorization
- Isolation / segregation / RBAC
- Built-in vs. Ad-hoc process
- Level of Git mastery within the team (should not be a criteria…)
As usual in the Deployment area, there isn’t a "one-size-fits-all solution" for all the use-cases. It really depends on the process, the organization, the level of security, the type of product, whether the solution is developed in-house or only integrated, … Even within a company, several approaches may coexist depending on the various needs.
As certain as tools can help, they shouldn’t be the first concern while implementing a GitOps strategy: we in Sokube believe that an appropriate automation, striving for simplicity and security are always better principles than heavily customized and hard-to-maintain solutions.
