
07 April 2024
By Yann Albou.
What an event this year! The largest in the history of the Cloud Native Computing Foundation (CNCF)! with more than 12,000 people!
Even in 3 days of conference, it was difficult to go around, a lot of conferences, sponsors, discussions, sponsor evenings, …
Already more than 10 years of Kubernetes!
On this occasion, the CNCF suggests that you submit your Kubernetes 10th anniversary logo!: https://www.linuxfoundation.org/kubernetes-10-year-logo-contest
Unsurprisingly, the major theme of Kubecon was Artificial Intelligence in Cloud Native mode with Kubernetes, but not only that!
Here is a non-exhaustive summary of the conferences that interested me, grouped by theme:
The first keynote by Priyanka Sharma (Executive Director, Cloud Native Computing Foundation) opened with Artificial Intelligence.
Cloud Native will not escape this AI trend but clearly needs standards and tools.
Clearly, all of this is on the way and will play an important role in this acceleration of AI with the sharing of models, processes and know-how:
“Kubernetes must become the AI standard”, Priyanka Sharma.
Training is the first phase of an AI model. “Training” can involve a process of trial and error, or a process of showing the model examples of input and output.
The inference phase represents the execution of a model once it has already been trained. Thus, inference occurs after the learning stages. We can also talk about the field deployment phase of the AI model. And so, at this stage, the artificial intelligence model is already pre-calculated and has already been modeled using data sets. So, at this point, artificial intelligence systems can draw conclusions or predictions from the data or knowledge they have learned.
Kubernetes and the CNCF are now positioned across the board and use the orchestration platform both to manage the lifecycle of Machine Learning (AI/ML/LLM Ops) and to run models and applications.
A new CNCF working group, the Cloud Native AI published a white paper on overviews of recent AI/ML techniques.
Introduction to the Cloud Native Artificial Intelligence (CNAI) initiative:
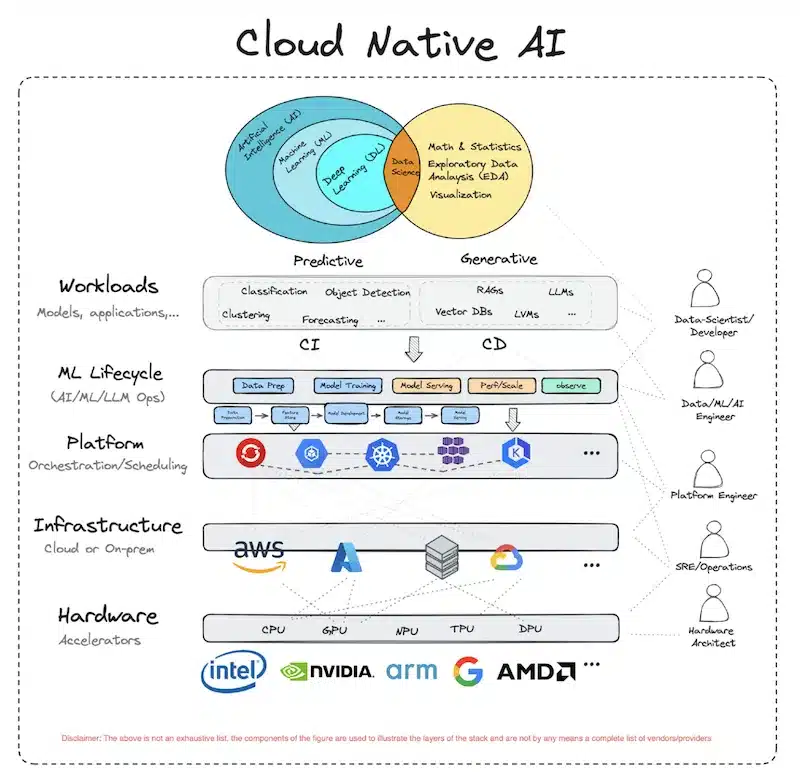
This trend leads to developments in Kubernetes in particular on:
Large language models (LLMs) are quickly gaining popularity and the idea of deploying and managing your own LLM can be very interesting, especially in terms of security, confidentiality, and customization. This talk walks us through the process towards a clear and practical understanding of self-hosting LLMs on Kubernetes.
Self-Hosting: Advantages and Considerations
Implementation:

Here is the list of Opensource LLMs
and a paper on “tracking openness of instruction-tuned LLMs
Watch the video of this session
Another way to use AI and LLMs is to use language models to improve operations on Kubernetes. They integrated LLMs with CRDs and Kubernetes controllers via an operator LLMnetes to simplify cluster management through a natural language interface resembling:
This project wants to go further with questions like “Can I upgrade my cluster to 1.29?” which will require analyzing the audit logs, cluster resources and reading the changelog.md of the k8s versions.
Warning: LLMs are not deterministic! ! !
As mentioned: Avoid querying a machine learning model for tasks that require precise data.
Watch video of this session
Build and delivery remain strong trends at KubeCon with developments to take into account MLOps but also many conferences on the security aspects of the Supply Chain.
The keynote by Solomon Hykes (CEO, Dagger.io) on the “Future of Application Delivery in a Containerized World” retraced the 10 years of evolution of Kubernetes with a strong message on the continuous improvement of the software factory, which must serve your needs and be a central place to take your business to the next level as a key differentiator:

Also considering the factory as a platform (here again, platform engineering plays an essential role – more on this below).
Several very interesting conferences around best practices to protect yourself as much as possible from “Supply Chain Attacks”. We wrote a blog on this topic “How to protect yourself from a “Supply Chain Attack”?”.
In particular the security framework SLSA was highlighted:
SALSA (in version 1.0) defines the guidelines for supply chain security with different levels and contains several “Tracks” in particular the “Build track” which focuses on provenance (from source to artifact):
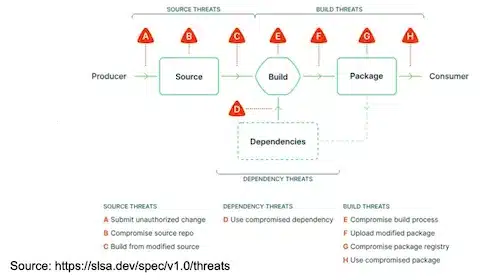
Scanning our artifacts for vulnerabilities is an excellent thing but not enough, we must also guard against problems of falsification of all elements.
So how can we increase the level of trust in our software supply chains? And what are these approaches based on:
Here are some tools used:
docker buildx build --sbom=true --provenance=true ...There are really a lot of tools to secure this CI/CD:
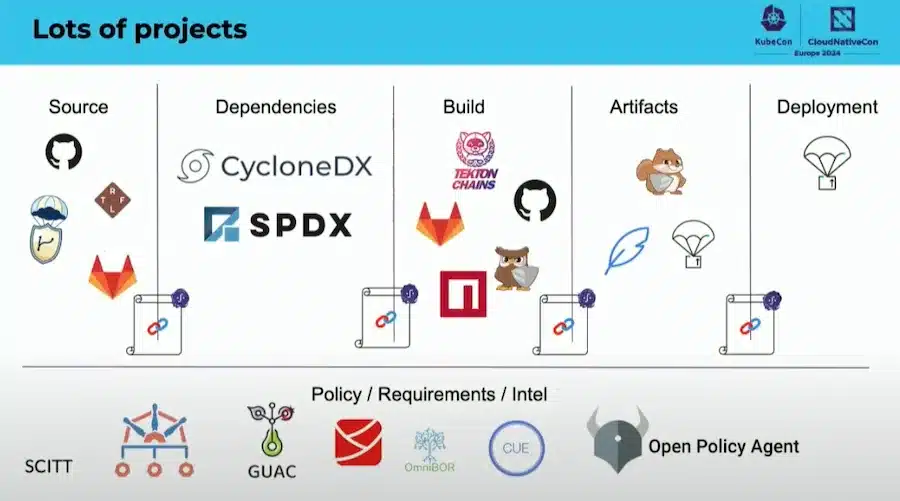
The CNCF is working on a document to map these tools
Also don’t forget that you need to secure your source code! By signing your commits, protecting your branches, having a suitable RBAC, authentication via MFA, use of SSH keys…
To demonstrate the whole CI/CD Tekton with the Tekton Pipeline was often used.
Also note the existence of the project FRSCA a “Factory for Repeatable Secure Creation of Artifacts: FRSCA” which provides tools and an implementation of the CNCF project Secure Software Factory Reference Architecture and which follows SLSA recommendations.
CI/CD practices around containers are strengthening and gaining maturity. Three conferences particularly caught my attention:
The Building Docker Images the Modern Way conference compared several approaches to building Docker images.
Starting the “old way” with a Docker Build (which produces images that are not reproducible, too large and with a lot of CVEs)
FROM golang
WORKDIR /work
COPY . /work
RUN go build -o hello ./cmd/server
ENTRYPOINT ["/work/hello"]To move towards a “Distroless Multistage Docker Build” approach so as to have only the bare minimum in the image without a package manager or shell…
Distroless images are built with
contents:
repositories:
- https://dl-cdn.alpinelinux.org/alpine/edge/main
packages:
- alpine-base
entrypoint:
command: /bin/sh -l
environment:
PATH: /usr/sbin:/sbin:/usr/bin:/binIn this session, they presented several tools for checking Helm chart compliance, including Checkov, Datree , KICS, Kubelinter, Kubeaudit, Kubescape and Terrascan.
These tools test and examine whether Helm charts comply with best practices, particularly when it comes to security.
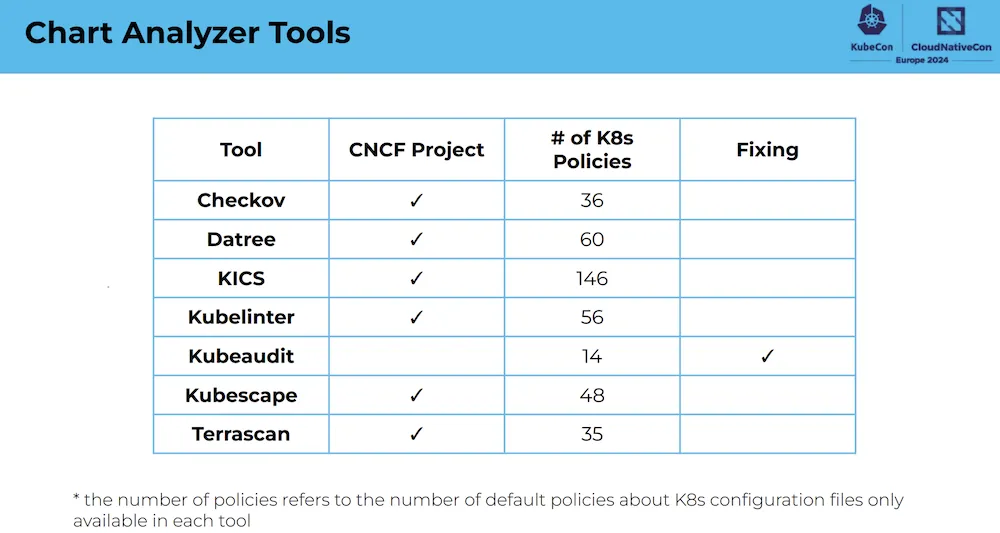
The following repository contains a list of public Chart Helm and was used to test the tools: https://github.com/fminna/mycharts
Several interesting points were raised:
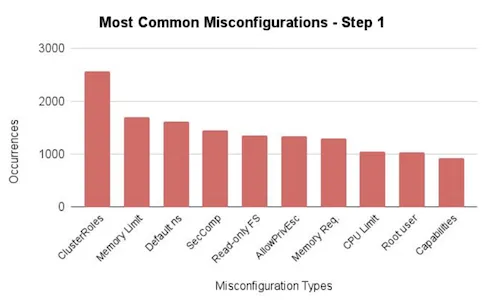
Regarding the tools, the feedback is:
Watch the video of this session
Following the announcement on Weavework announcing that the company was stopping its activity, we could seriously worry about the continuation of the GitOps product Flux.
This presentation was reassuring about the future of this product:
If we add to this the fact that Flux is a CNCF project and which moved to the “Graduated” maturity level on November 30, 2022, this allows us to guarantee a certain sustainability of the solution!
Watch the video of this session
This is not a new technology but it was strongly present during KubeCon and in particular during the first keynotes.
WebAssembly is a binary instruction standard format designed to replace JavaScript with superior performance. The standard consists of bytecode, its textual representation, and a sandboxed execution environment compatible with JavaScript. It can be run in and out of a web browser
Many programming languages today have a WebAssembly compiler, including: Rust, C, C++, C#, Go, Java, Lua, Python, Ruby, …
WebAssembly is very efficient, fast and secure which makes it compatible with the Cloud Native world.
This conference explores the use of WebAssembly in Kubernetes through a tool SpinKubepin
The strengths of WebAssembly:
Fermyon positions WASM as an evolution of containers for adapted use cases:
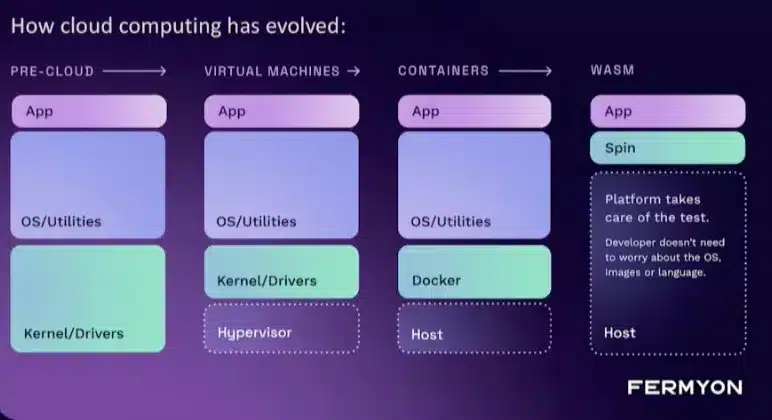
In particular, for the Serverless pattern: Containers are excellent for running long-running processes, but have a WASM type technology for Serverless that can cold start instantly, run to the end and stop.
How does it work:
Spinkube contains all the elements necessary to run WASM Spin applications in k8s based on the runwasi projects (for the shim part of containerd) and Kwasm for the operator part.
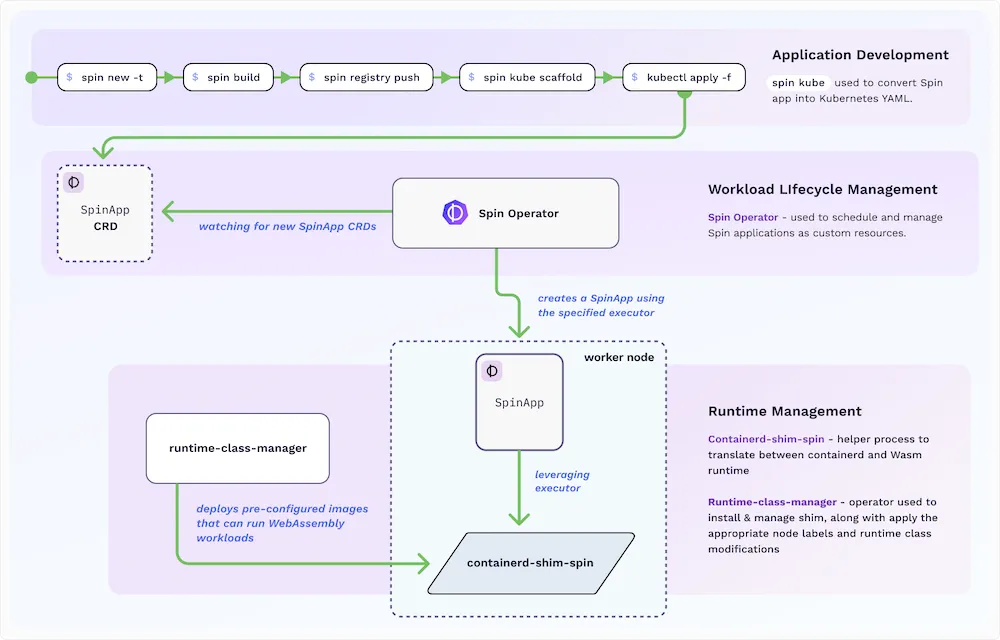
There was clearly a strong interest in WASM and SpinKube due to the performance and its integration into the Cloud Native world:

Watch the video of this session
We’re talking about Artificial Intelligence but have we forgotten last year’s theme on sustainability and eco-responsibility?
The keynote called for “responsible innovation”: keep innovating, but do it using open source and with cost and energy savings in mind.
Projects like WASM are moving in this direction, and LLM models are entering a cycle of optimization of their model, is this enough?
This session shows real business use cases on sustainability at Deutsche Bahn.
They first carried out an optimization between the average use of the machine CPU and the real CPU used by the application by forcing the use of the definition of requests and limits as well as the use of VPA (VerticalPodAutoscaler).
Then they used schedulers to reduce or stop workloads that are not used during non-working or less active hours…
In addition to saving a lot of energy it also saves money.
The measurement of energy costs is done with the Kepler project:
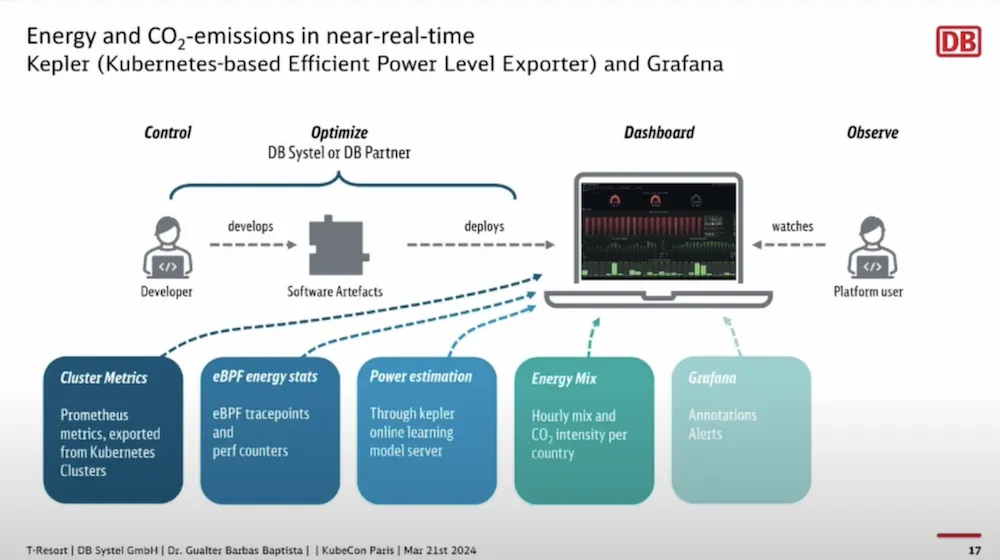
This makes it possible to measure impacts by project or even measure the impact of one change to another, and thus have a global and target carbon footprint.
These dashboards are now part of the life of projects and constitute information that can influence certain decisions…
Watch the video of this session
The TAG Environmental Sustainability supports projects and initiatives related to the delivery of cloud-native applications, including their creation, packaging, deployment, management and their exploitation.

The objectives of this group are:
The SCI score will help calculate the carbon intensity of software:
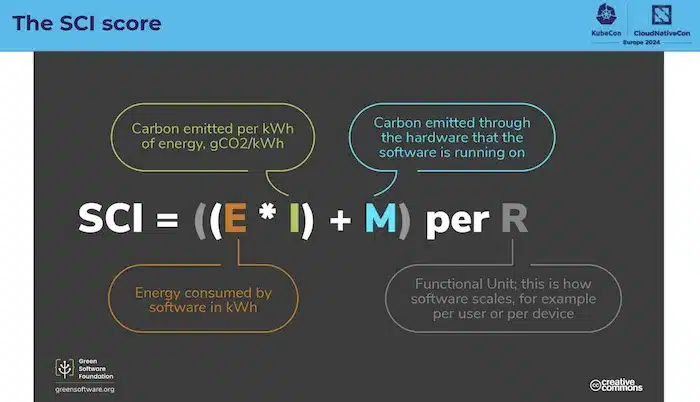
And the goal being to produce these metrics:
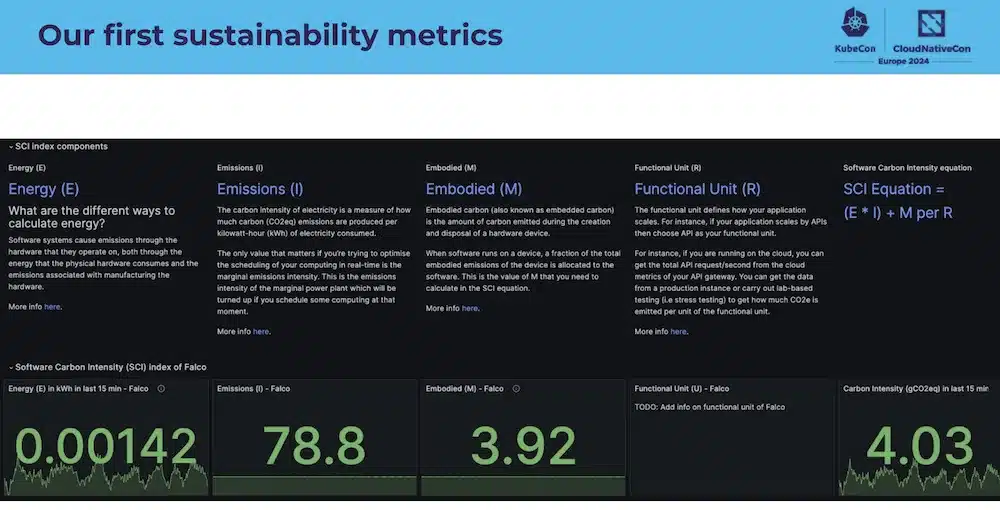
The Falco project has requested its first “Green” review and other CNCF projects will follow.
Watch the video of this session
Lots of tracks on observability with a particular focus on Opentelemetry but also on AI.
The OpenTelemetry project is everywhere and widely used

Just in the month before this KubeCon there were 25,000 contributions!!!
In short, its popularity is no longer in doubt.
News on the logging side:
OpenTelemetry defines “Semantic Conventions” which specify common names for different types of operations and data, which helps bring standards to the codebase, libraries and platforms.
Semantic Conventions are available for traces, metrics, logs and resources, all in a stable version for the HTTP part.
And work in progress on the Databases, Messaging, RPC, System parts and the new latest AI/LLM!!!
Extension of OpenTelemetry signals on the “Client-side” part and not only at the application and infrastructure level.
Definition of a new “Entity” concept to better represent the telemetry producer.
The OpenTelemetry project has applied to be a CNCF “Graduated” project and thus demonstrate its stability and maturity.
See the video of this session
The “Observability TAG” working group aims to enrich the ecosystem of projects related to observability in cloud-native technologies, by identifying gaps, sharing best practices, educating users and CNCF projects, while providing a neutral space for discussion and community involvement.
Observability Whitepaper is available.
It focuses on improving observability in cloud-native systems, providing an overview of observability signals, such as metrics, logs and traces, and discusses best practices, challenges and potential solutions. It aims to clarify the concept of observability, providing valuable insights for engineers and organizations seeking to improve the reliability, security and transparency of their cloud-native applications and infrastructures.
The TAG observability co-sponsored the Cloud Native AI workgroup (see the AI chapter above) and reviewed several projects around AI:
There is clearly an “Observability + Gen AI” trend in order to:
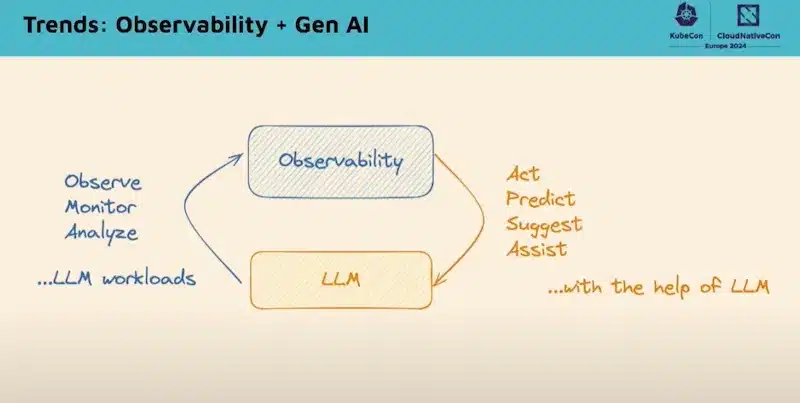
Watch the video of this session
IaC was not a trend at the conference, there was no session dedicated to, for example, Terraform or Ansible.
On the other hand, in most conferences these Infra-as-Code tools were used as a basic foundation!
In addition, there are still 2 notable points in this area:
The first concerns the multiple exchanges and informal discussions around Terraform following the change of license by HashiCorp (Business Source License: BSL v1) which led to a fork of the 1.5 release of Terraform to create the project [OpenTofu](https:/ /opentofu.org/)!
Terraform is strongly established in companies and projects and depending on the evolution of these 2 projects, this could lead to a lot of change… To be continued
The second point concerns the strong presence of Crossplane which is seriously gaining popularity and which is, without a doubt, a very interesting project.
Crossplane is an IaC tool that defines itself as a “Cloud Native control plane” to provision and manage all your resources based on Kubernetes!
It is a project very well established in the CNCF eco-system and above all production ready:

All resources are managed from Kubernetes through CRD and Crossplane manages communication to external resources like AWS, Azure or Google Cloud.
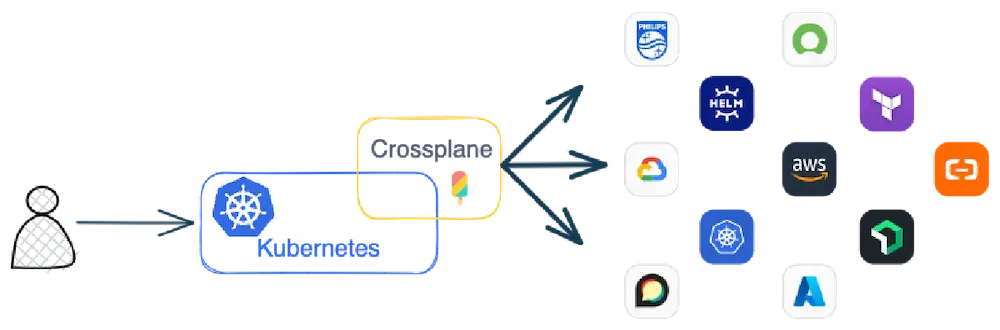
There is a community Marketplace with a list of providers, some of which are given by Upbound (the company behind Crossplane))
Crossplane also allows the creation of custom Kubernetes APIs. Platform teams can combine external resources and simplify or customize the APIs presented to platform consumers.
And so you can create your own API platform: for example compose a GKE in Platform Engineering mode.
Watch video of this session
This session was not a presentation but a discussion with a panel of people who shared their opinions and vision on the evolution of Infra-as-Code.
Several interesting points:
But in the end, migrating between IaC tools is still a significant effort.
Watch the video of this session
During KubeCon EU in 2022 the trend was Platform Engineering, this year platform engineering is no longer a trend but a reality.
Infrastructure tools and frameworks, such as Kubernetes, service meshes, gateways, CI/CD, etc., have evolved well and are widely considered “classic technologies” (at least for this specialized audience) . The big challenge now is putting the pieces of the puzzle together to deliver value to internal customers.
See our article on what is Platform Engineering and the links with DevOps
The sponsor showcase was full of mentions about platforms, platform engineering and developer experience, including:
Humanitec, Backstage, Port, [Cortex](https: //www.cortex.io/), Kratix, Massdriver, [Mia-Platform](https: //mia-platform.eu/), Qovery, …
We are even seeing workload specification languages appear like Score and Radius to bring a layer of abstraction between the developer’s request and the technical implementation by the Platform Engineer.
The essential Backstage for the IDP (Internal Developer Platform) is the project to which CNCF users have contributed the most!
After 4 years of existence there are more than 2.4k adopters and 1.4k contributors!!!
The project continues to work on its maturity on governance by proposing an improvement process: Backstage Enhancement Proposals which is largely inspired by the Kubernetes Enhancement Proposals (KEPs)
Here are the new areas of this project:
The evolution of Backstage continues with an axis of simplification which will, without a doubt, be very appreciated!
See the video of this session
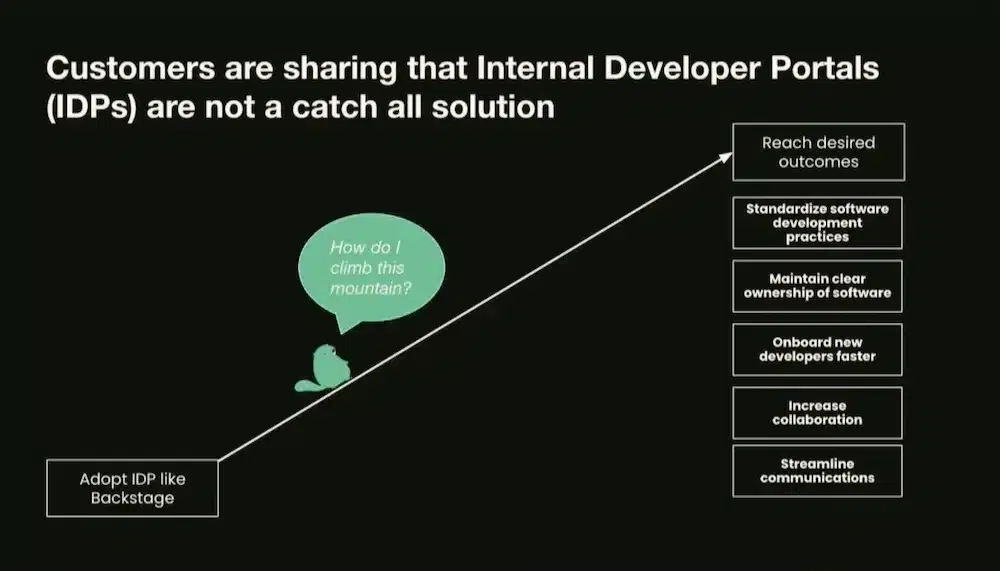
This session focused on the product approach to developing the platform by describing what a “Platform Product” is at Spotify.
And above all it is a change of mindset in “Platform as a Product Mindset” mode which changes the way of making an IDP and the management of internal products.
Having a portal is not enough, product orientation is about directing the desired outcomes and creating continuous, iterative value to achieve those outcomes:
 )
)
This approach also makes it possible to optimize operations, reduce costs and align with market trends.
The goal is to focus on results by analyzing value (what problem we are trying to solve) and viability (who the customers are and why they use the platform).
And get out of the “cool, let’s adopt a new fashionable technology”, “there’s only one need, let’s make a new solution” mode, etc.
It is necessary to understand the business need and develop “Customer Empathy” by talking regularly with your customer and not just a member of the team.
But also to understand the motivations of the different users and managers up to the CTO, this is the idea of “deployment empathy” and thus have the global vision to deliver a solution also adapted to decision-makers.

See the video of this session
Obviously, Kubernetes, the heart of KubeCon, was strongly present!
After more than 10 years in existence, it continues to evolve, enrich and adapt to the needs and new developments of the market.
This session explains the main patterns of K8S, understanding these models is crucial to understanding the Kubernetes mindset, and strengthening our ability to design so-called Cloud Native applications so that they best fit into this approach.
Patterns by category:
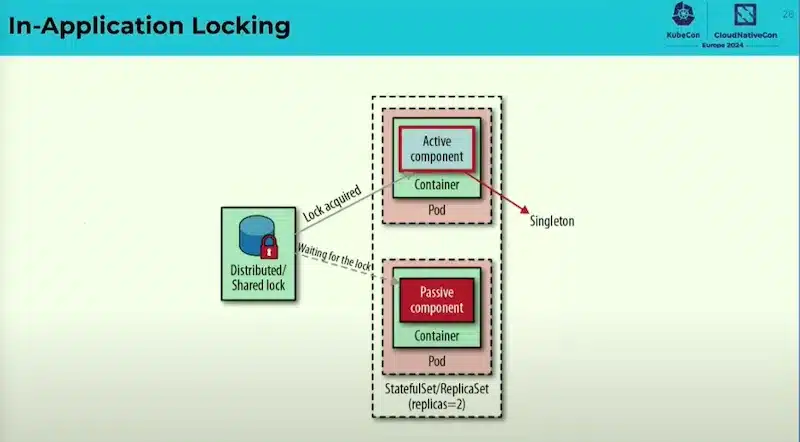
There are many other patterns, see the book “Kubernetes Patterns”
Watch video of this session
I find it extremely interesting to watch the Kubernetes Release process by the Kubernetes SIG Release Group.
Kubernetes is a complex product composed of multiple components with multiple teams from different companies distributed around the world all with a demanding release cycle. And it works !!!
Due to this complexity, it is always complicated in business to be part of the Release team and expectations are not always met!

Documentation is a crucial point and a prerequisite for improvements that are part of Kubernetes releases.
Having a “Docs Freeze” phase is important as are “Code Freeze” phases to bring about stabilization phases.
Kubernetes v1.30 “Uwubernets” is in progress:

The 2024 roadmap for SIG Release is to have a more robust, faster and more flexible Release Pipeline.
The k8s package build is done with OpenBuildService from Suse which allows you to work with all major Linux distributions. The packages are then published on pkgs.k8s.io
Release actions are done with GitHub Actions, using steps for creating Provenance, SBOMS, Check Dependencies and publishing release and release notes.
The entire release process is described in the kubernetes repository
The future is to create a truly secure Supply Chain: SBOMS, Provenance, Signature are already part of the process but few use them or rely on them.
There will be a new Kubernetes security flow with a Security Response Committee (SRC)
There is clearly a lot to learn from it to apply it on our own Release even on non-Opensource projects but in “InnerSource” mode
Watch the video of this session
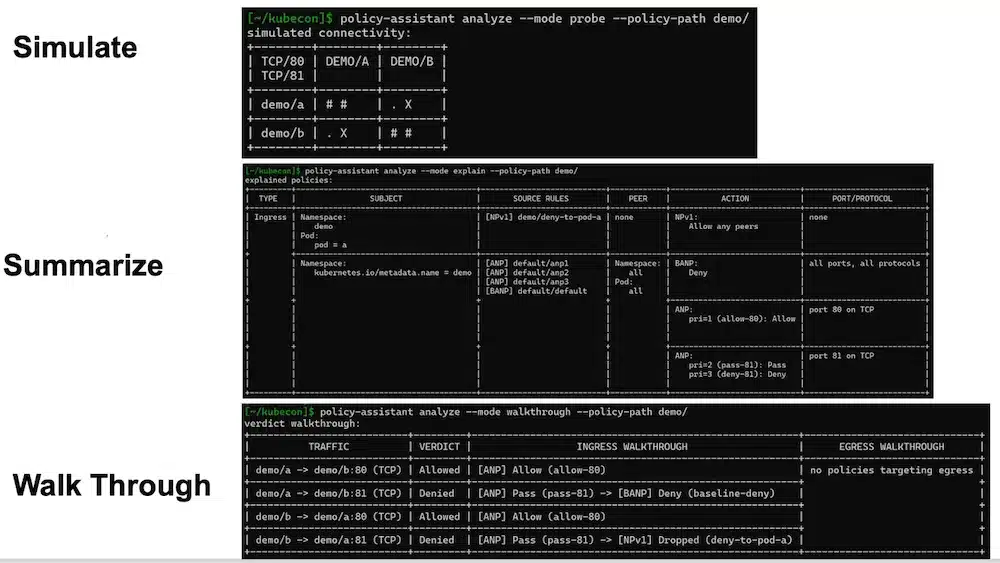
NetworkPolicies are an important Kubernetes feature managed by the SIG Network and help secure communications flows between pods.
They were designed for devs with an implicit API design (implicit refusal, explicit authorization list of rules).

Appearance of 2 new objects: AdminNetworkPolicy and BaselineAdminNetworkPolicy in v1alpha designed, this time, for Admins with an explicit mode.
The usecases:
The AdminNetworkPolicy API takes precedence over the NetworkPolicy API.
The BaselineAdminNetworkPolicy API corresponds to a default cluster security posture in the absence of NetworkPolicies
Several improvement proposals: Network Policy Enhancement Proposals (NPEP):
Future Plans: Network Policy V2?
See the video of this session
Mesh services become essential when creating micro-services in Kubernetes, the advantages are multiple:

Mesh services have largely adopted the Sidecar container approach in order to bring the network as close as possible to the application without being intrusive but also come with disadvantages (difficulty of size, security, challenging upgrade, etc.)
The use of eBPF for Service Mesh allows us to resolve some of these problems which does not exclude the need for ‘have a proxy:
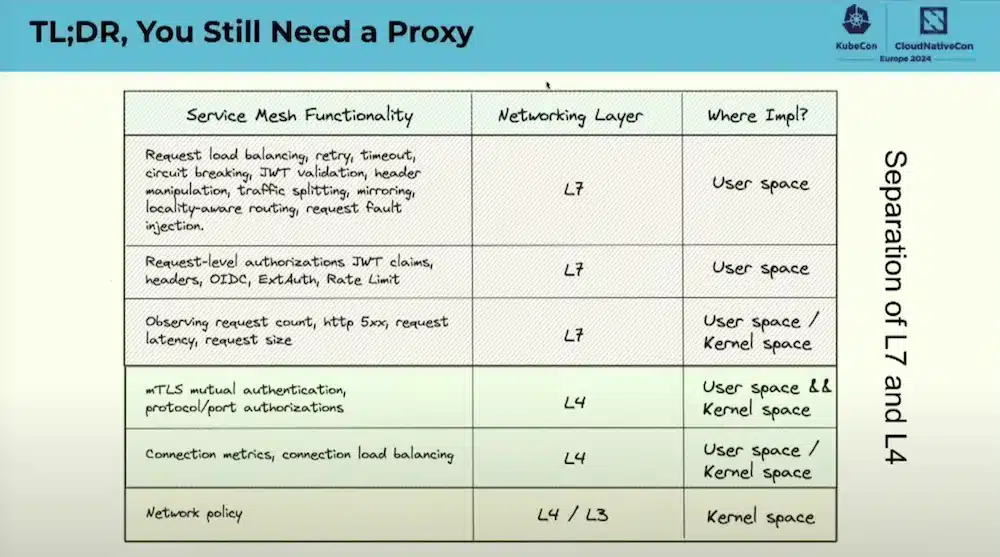
The comparison between Cilium and Istio in “Sidecarless” mode or in mixed mode (Separation of layers 4 and 7) clearly explains the different architectures and the operation of these 2 Mesh Services.
Watch the video of this session
The question of the database in Kubernetes is recurring. Is it production ready if we use operators?
This comparison has chosen some Database operators (PostgresQL, MySql, MariaDB) in relation to the setup, Observability, backup restore, upgrade, etc. functionalities.
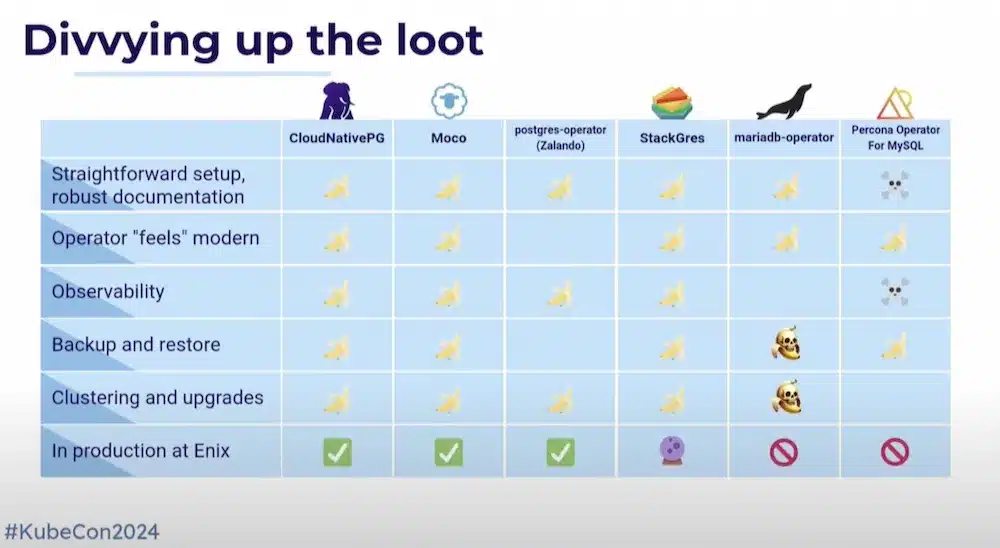
Interesting feedback based on their actual production experience, and noted using Banana (good), Skull (worse) or a mix of both (improvement over previous versions) icons.
Watch the video of this session
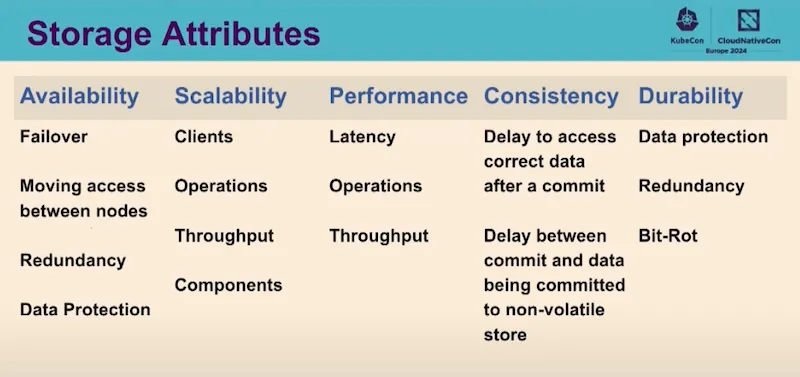
To go further from the previous session on database operators, this presentation explains the advances on Kubernetes storage: More Statefull workload to K8S: automation, scalability, performance, failover!!!
There is a white paper to clarify terminology, explain how these elements are currently used in production in public or private cloud environments, and compare different technology areas .
A focus on databases with also a white paper “Data on Kubernetes Whitepaper – Database Patterns” which explains the operating modes well:
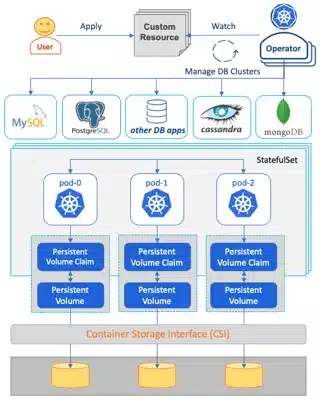
It is interesting to see that the Operatorhub contains 349 operators including 47 db operators with 9 PostgreSQL operators.
An essential point when managing data in Kubernetes is the Disater Recovery aspect
There are several approaches described in this document
The next focuses will be on data and AI/ML workload…
As well as a performance white paper.
Watch the video of this session
Security was everywhere, on all themes with zero-trust approaches.
In particular, secure supply chains have been widely mentioned in container building tools (alongside SBOMS and SLSA): see the Supply Chain chapter above.
Network security was also featured, with interesting mentions of Cilium (and eBPF in this context), Linkerd and Istio.
I remember this presentation where the public was able to choose the security tools to protect an application in Kubernetes:

In addition to the successive demonstrations of the tools, what was very interesting was to see the choice of tools by the audience:
Watch the video of this session
KubeCon 2024 marked a turning point in the evolution of Kubernetes and the Cloud Native ecosystem, with a particular focus on the integration of artificial intelligence, while highlighting the importance of security, Supply Chain, sustainability, infrastructure-as-code and WebAssembly.
These themes show maturity and a long-term vision, paving the way for future innovations.
The broad spectrum of topics covered, from secure supply chain to best practices in observability and operations, confirms the community’s commitment to continuous improvement. Kubernetes, at the heart of these discussions, proves once again that it remains at the forefront of technology, ready to meet the future challenges of Cloud Native.