
By Yann Albou.

SoKube – silver member at CNCF – went to KubeCon Europe Valencia to get the 2022 temperature, trends and news of the CNCF & Kubernetes ecosystem. After 2 years of virtual conferences, this was just awesome to attend again such an event in person. Speakers were also grateful to have real interactions with attendees.
This blog post has been co-written by Sébastien Féré & Yann Albou
Udated 16/06/2022 – add videos links
The event and the ecosystem is still growing and figures aren’t telling the opposite… Almost 1200 CFP (talk submissions) for 148 accepted talks, so it represents only 12% of selected talks among:
With such a distribution, we better understand why our SoKube talks weren’t selected, which at the same time gives us insights on how to better share our customer and internal experiences from the trenches!
While we’re spending good times in Valencia, we guess every attendee from Europe and beyond has however the Ukraine war in mind… Support for Ukraine was very present in opening keynote session. As mentioned by Priyanka Sharma, the CNCF supports the people of Ukraine through Razom and Operation Dvoretskyi. The CNCF invites you to join them in supporting the people of Ukraine and carry on the spirit of #TeamCloudNative. Visit https://www.cncf.io/ukraine for more info!
About the 2022 topic trends, still some 101 tracks as more than 50% of attendees are new comers to the KubeCon (new comer here doesn’t mean beginner though ). Otherwise, pretty specialized and advanced topics:
Among the 148 talks, we unfortunately missed some of them because of over-crowded rooms or being late… we took the opportunity to have profitable discussions with vendors at their booths. As a consulting company, SoKube indeed partners with vendors in many areas of the CNCF landscape, from Kubernetes distributions to Security, Data, … We spent in average 30min (up to 1 hour) at the booths we visited, which gives us enough time to deep dive into product demonstrations, roadmap, discovery of new products, … This special mix of talks and discussions, some in a casual ambiance at night, is meant to give us the best of such a KubeCon event!
As Kubernetes has become ubiquitous, most – not to say all – Fortune 500 companies now manage several to dozens of Kubernetes clusters, which for sure comes with new challenges… at scale!
Some companies still continue to use a single / big cluster, experiencing then some limitations for Day-2 operations (upgrades, environment segregation, …), especially when hosting Kubernetes clusters on-premise. This inheritance from the early years of Kubernetes is balanced with talks from KubeCon Europe 2022 – a lot of talks aimed at demonstrating and giving feedback with performance, multi-regions, multi-tenancy and multi-cloud use-cases.

The talk from Mercedes-Benz is very interesting : How to Migrate 700 Kubernetes Clusters to Cluster API with Zero Downtime – Tobias Giese & Sean Schneeweiss, Mercedes-Benz Tech Innovation
They operate and manage a huge fleet of Kubernetes clusters all over the world with more than 900 – 200 clusters have been created between the CFP and the talk! – clusters through 5 Platform Teams in 4 Datacenters! When the speakers asked in the room "How many people manage more than 100 clusters?", there were more people that we could expect.
Mercedes-Benz moved from a legacy provisionning infrastructure (Jenkins as the trigger + Terraform for provisioning clusters on OpenStack + Ansible for workload deployments on Kubernetes) to the Cluster API with Flux & GitOps – more explanations on what is Cluster API in the next section.
They have several Management clusters that take care up to 200 Kubernetes downstream clusters with a target of zero downtime, using this migration workflow: Datacenter Infrastructure, Worker nodes, Control plane.
This talk demonstrates a migration at scale of Kubernetes with lessons learned:
Before increasing the number of nodes you may want to optimize the resource usage of your cluster. Vertical Pod Autoscaler (VPA) is a poorly known feature that could help in this situation and which is very well described in the Vincent Sevel’s talk – How Lombard Odier Deployed VPA to Increase Resource Usage Efficiency – Vincent Sevel, Lombard Odier – this is a true feedback situation where Request and Limits constraints for CPU or memory are described and where the VPA approach is explained to improve and optimize the usage of these resources. VPA is a CRD resource that adjusts Request and Limits resources based on metrics. So instead of hard-coding the request in your YAML Deployment (or any other Kubernetes resources), VPA will find the right value based on the Percentiles 90 (P90) using the right metric from either internal or from Prometheus metrics.
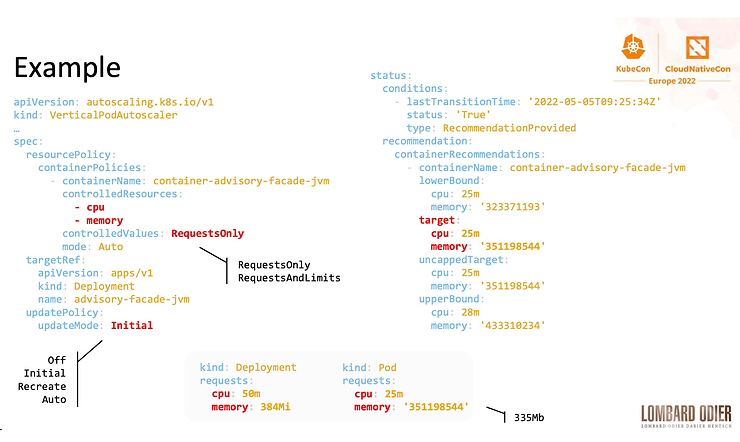
Lessons learned: the low CPU recommendation made by VPA, have 1 VPA object per Deployment, the JVM specificities and others…
In her talk Autoscaling Kubernetes Deployments: A (Mostly) Practical Guide – Natalie Serrino, New Relic (Pixie team), Natalie Serrino describes the 3 options to scaling a Kubernetes cluster – Cluster Autoscaler, Vertical and Horizontal Pod Autoscaler – spending much of the time on her preferred one.

The Horizontal Pod Autoscaler has indeed very useful options for real-world scenarios (do not react to fast on stimuli, increase or decrease smoothly, …) and can be used with user-defined metrics
Right now, you can’t use HPA in conjunction to VPA on the same metrics (ex: CPU), but the contributors are working on such a scenario!
As often when use-cases become common in the CNCF landscape, standardization appears. Cluster management follows this rule as well with the Cluster API.

The Cluster API is a new standard from the Kubernetes SIG that allows to create and manage fleet of Kubernetes clusters using a standard API either on premise or in a cloud infrastructure (managed or not). see kubernetes-sigs/cluster-api & Introduction – The Cluster API Book
Some nice talks about this API during the Kubecon:
The goal is to focus on the 80% of cluster management and make the rest possible. Here is the Management cluster that leverages the CRD API of Kubernetes:
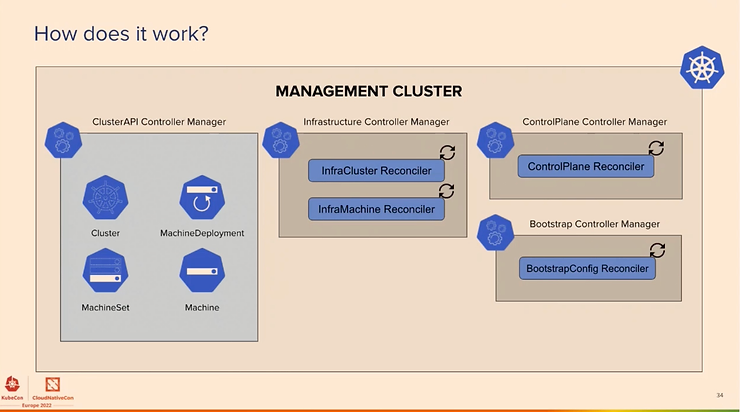
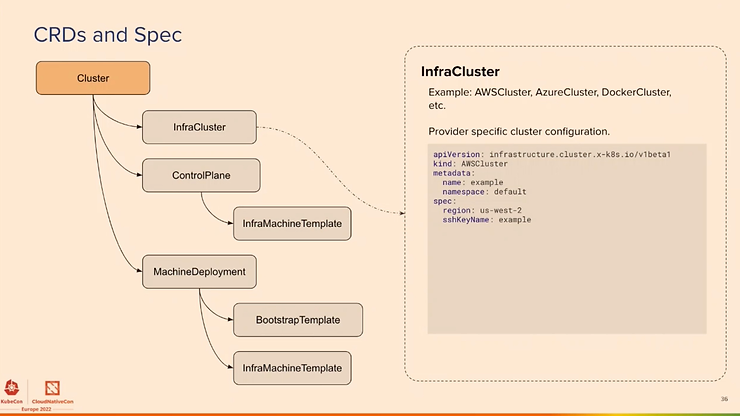
The new features concern ClusterClass and Managed Topologies, Ignition and Flatcar support, clusterctl for Windows and ARM support, more providers (IBM Cloud, Bring your Own Host, Oracle Cloud, Nutanix, …). The providers implementation is listed here.
In the next features to come : Higher level OS and node bootstrapping integration, improve bare metal and edge, Autoscaling from and to 0, certificates rotation…
It is production ready since version 1.0 on october 2021, and lot of companies already use it in production: Twilio, Giant Swarm, Spectro Cloud, Talos Systems, New Relic, RedHat (the Machine API comes from RedHat), Deutsche Telecom, US Army, Microsoft Azure, Amazon AWS EKS, D2iQ, Samsung SDS, SK Telecom, Mercedes Benz, VMWare,
We really encourage you to have a look on cluster API that will continue to growth…
Definitely a strong focus for this edition, perhaps telling security is a hot concern both at the Infrastructure and Software Supply Chain levels.
From discussions with vendors, also acknowledged from our feedbacks on the field, it seems that end-users have a low maturity when it comes to Security – we guess such a gap comes from the old ages of the IT infrastructures (defense at the perimeter).
CI/CD has rarely been a focus for security but because of the shift left and zero trust approaches it becomes a bigger concern. Supply chain attacks are increasing at fast pace! Some security products start to focus on this concern to propose an holistic security approach.
A funny but very interested talk about how to secure your supply chain:
Make the Secure Kubernetes Supply Chain Work for You – Adolfo García Veytia, Chainguard
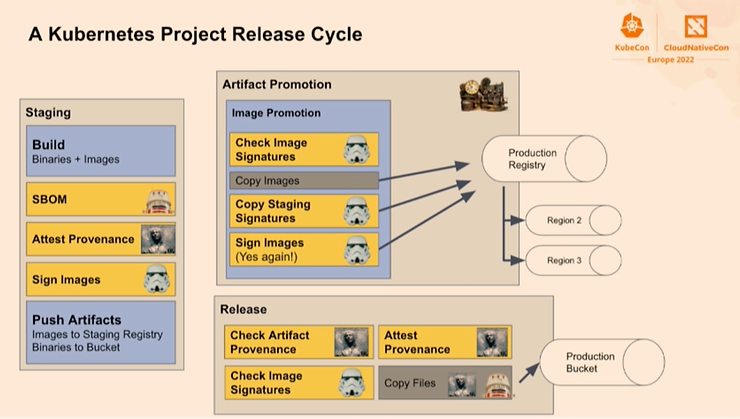
He talks about release management describing a Kubernetes Project release cycle (relying on kubernetes/sig-release) using concepts like SBOM, Attest Provenance, Signing, Build Promotion, dedicated registry (with regions), Provenance verification, … a talk to look at!
Cilium, powered by Isovalent, seems to become "The CNI implementation" as it is now used by default as the networking and security layer in Google GKE and Amazon EKS.
Cilium: Welcome, Vision and Updates – Thomas Graf & Liz Rice, Isovalent; Laurent Bernaille, Datadog
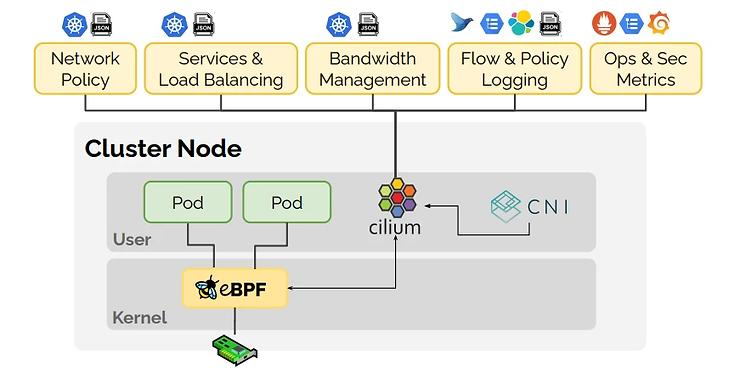
When Isovalent announces new products at KubeCon, we should keep an eye on this!

Also, discover Liz Rice’s excellent talk on Cilium Service Mesh that explains what is a Service Mesh and the Cilium architecture with a sidecarless approach moving Service Mesh to the kernel through eBPF (removing the need, in certain situations to use a L7 network path) and so improving performances.
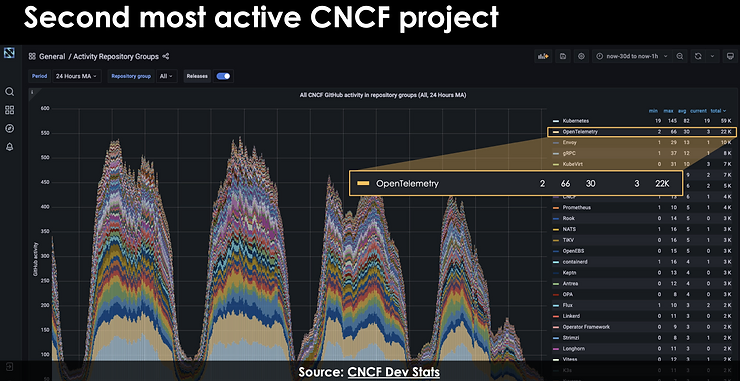
As any other area of the CNCF landscape, maturity comes with standardization – so here is the OpenTelemetry specification and status! OpenTelemetry is currently the second most active CNCF project, behind Kubernetes…
OpenTelemetry: The Vision, Reality, and How to Get Started – Dotan Horovits, Logz.io
OpenTelemetry (aka OTel) is an observability framework – software and tools that assist in generating and capturing telemetry data from cloud-native software – across Traces, Metrics, Logs.
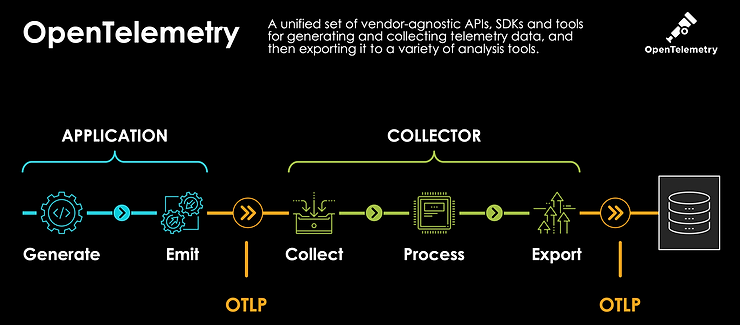
Surprisingly the most advanced topic is currently Tracing. The Metrics topic is expected to be Stable / GA in a few weeks as the Release Candidate has been issued just before KubeCon.

They were a few dedicated talks on GitOps, but a lot of talks included indirectly the GitOps approach – not only for application deployments but also for infrastructure deployments!
Just like Kubernetes became the standard for Container Orchestration a couple of years ago, GitOps has become the de facto standard to deploy workloads to Kubernetes clusters with the two flagship products ArgoCD and Flux.
We won’t describe in detail but lot of nice things to come with Argo and Flux. Here is some nice talks:
The last one with Skyscanner was really interesting and shows how a mistake in a GitOps with Helm and ArgoCD can lead to a very bad situation with mass deletion of all services (478) in all namespaces across all AZs and regions ! just with this "little" modification:

This was a "GitOops" nightmare! Mitigation has been applied, prioritization by functional region and scheduling first non-critical load …
A good case study about chaos engineering: Case Study: Bringing Chaos Engineering to the Cloud Native Developers – Uma Mukkara, ChaosNative & Ramiro Berrelleza, Okteto
This talk explains clearly what is chaos engineering and why use it. Chaos Engineering is part of the DevOps culture not only for your test or prod environment but also for the dev team with different levels of maturity (Chaos Engineering Maturity levels).
The case study mixes an interesting usecase between Litmus (a Chaos Engineering platform) and Okteto (a tool that enables team to quickly spin up Kubernetes-based development environments) to run Chaos experimens all the time in a development process.
When it comes to understand a Cloud bill for a financial person, this might be quite repellent… Dozens of lines in a spreadsheet without any ability to charge a Business line or another one.
This topic isn’t new, however it gets a new visibility through Kubernetes and the CNCF. Years ago, the cost producer and the cost manager were the same in an organization. Today, all engineers produce cost – which is a radical change!
FinOps is an evolving Cloud Financial Management discipline and cultural practise, that – just like DevOps did – helps breaking silos, increase business value. It also enables spending decisions, mainly by achieving cost transparency and control, which comes through:
Finance definitely needs to work hand-in-hand with engineers in order to manage properly and efficiently costs on cloud-native platforms – you’ll ear about it soon for sure!
This was another amazing KubeCon! We strongly encourage you, if you are not familiar with these topics, to take a look at these different themes, products and trends.
Unfortunately this blog post can’t cover comprehensively all the sessions and all the very interesting discussions with people, speakers, sponsors, vendors about feed back experiences, news, features, products, …
If you are interested to get more information or deeper explanations on specific topics just contact us.
And if you were at the conference then feel free to share your favorite sessions or feedback in the comments.
Check out the videos that are now available publicly on the CNCF YouTube channel and save your agenda for the next Kubecon: