
By Yann Albou et Sébastien Féré.
In this article, co-written with Sébastien Féré, we describe what GitOps is, its impacts in the company and an example of implementation.
For french speakers, we did a talk at DevOpsDays Geneva 2020, presenting GitOps as a way to manage enterprise K8s and virtual machines:
GitOps, from its inception in August 2017 by Alexis Richardson, CEO @ WeaveWorks, is described as 4 pillars:
Since the inception of DevOps in 2010, push and pull deployments options have always been on the table. However for good or bad reasons – the idea of control being the most prominent – push-based deployment remains the favorite way to go in most companies.
source: based on the diagram from gitops.tech
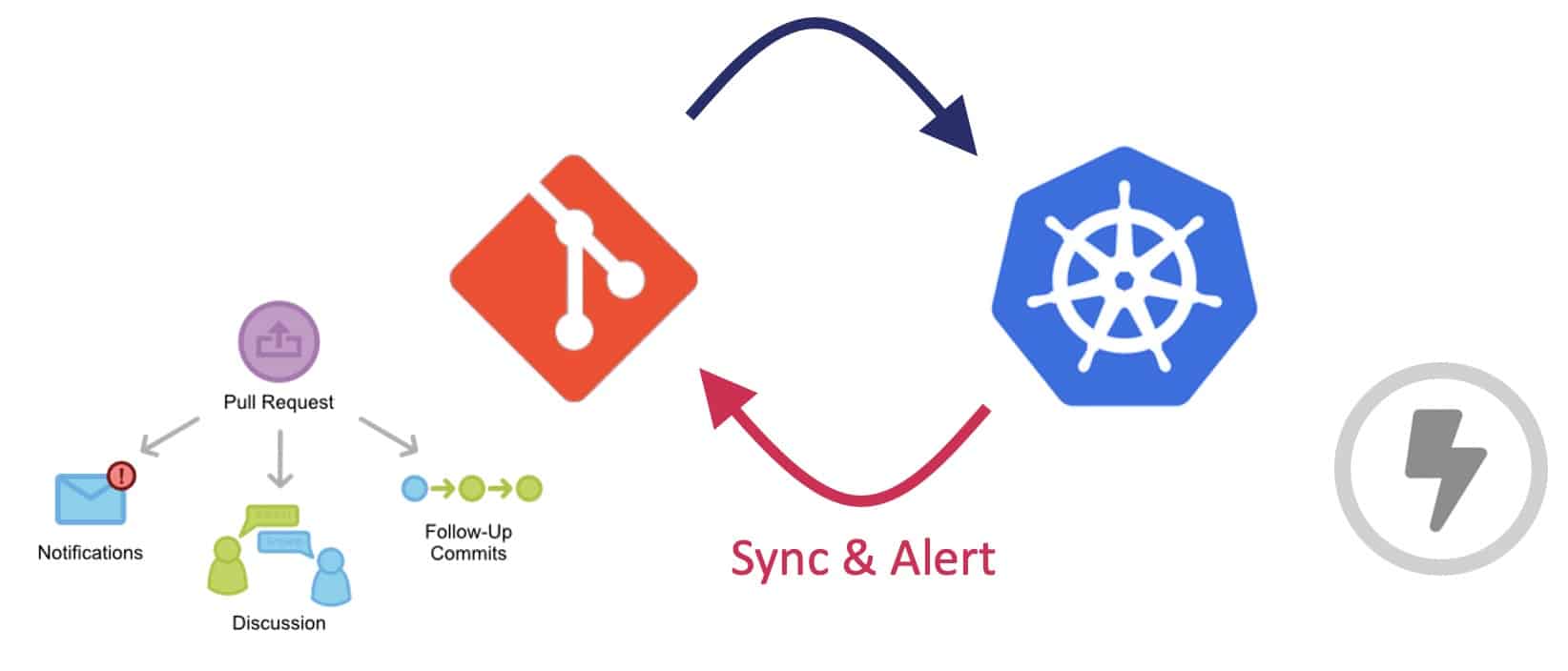
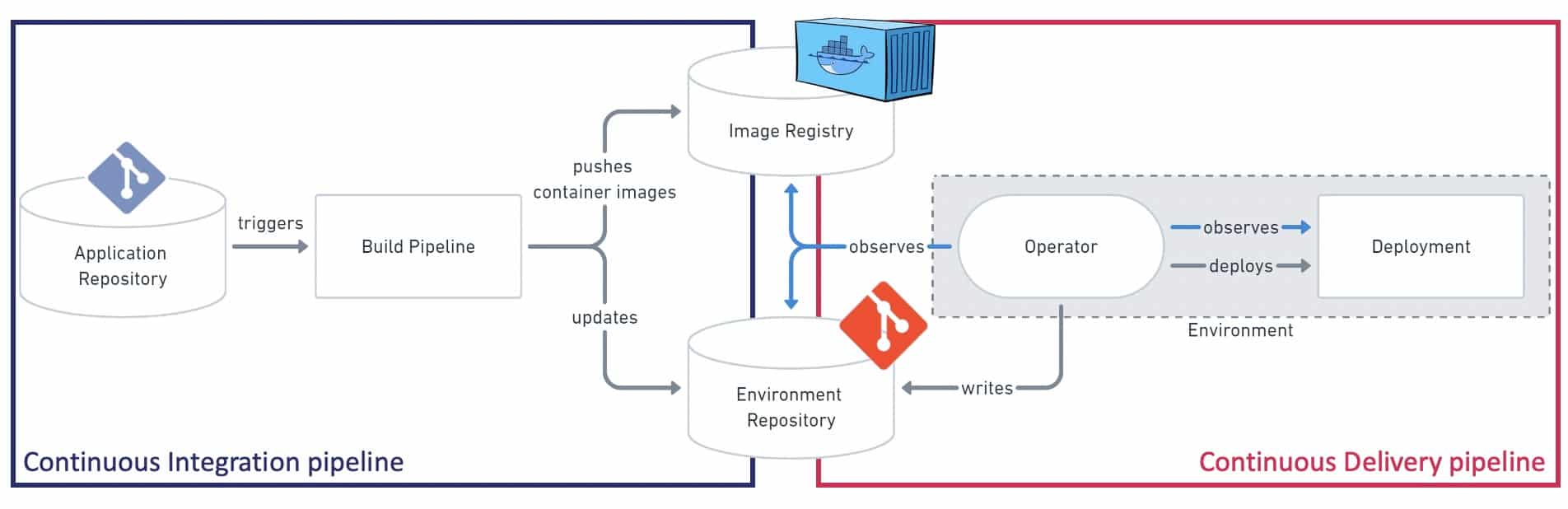
With the pull-based approach, the Operator from inside the Kubernetes cluster is in charge of listening new events from the Git repository (containing the deployment manifest) and from the Docker image registry. When a new commit or a new image is produced, the operator compares the current state with the desired state of the deployment and performs possible modifications to match the desired state.
If you omit automated writes that can be easily performed by the CI pipelines, the Operator only requires read access to the Image Registry and the GitOps repository.
Being inside the cluster definitely improves the security because you are inside the "trusted zone" – no need for any credential with high-level permissions to access the cluster. This also improve the addressability – no need to specify the URL to target the right cluster, which might avoid deployment mistakes: which company never targeted the wrong environment during a deployment?!
source: based on the diagram from gitops.tech
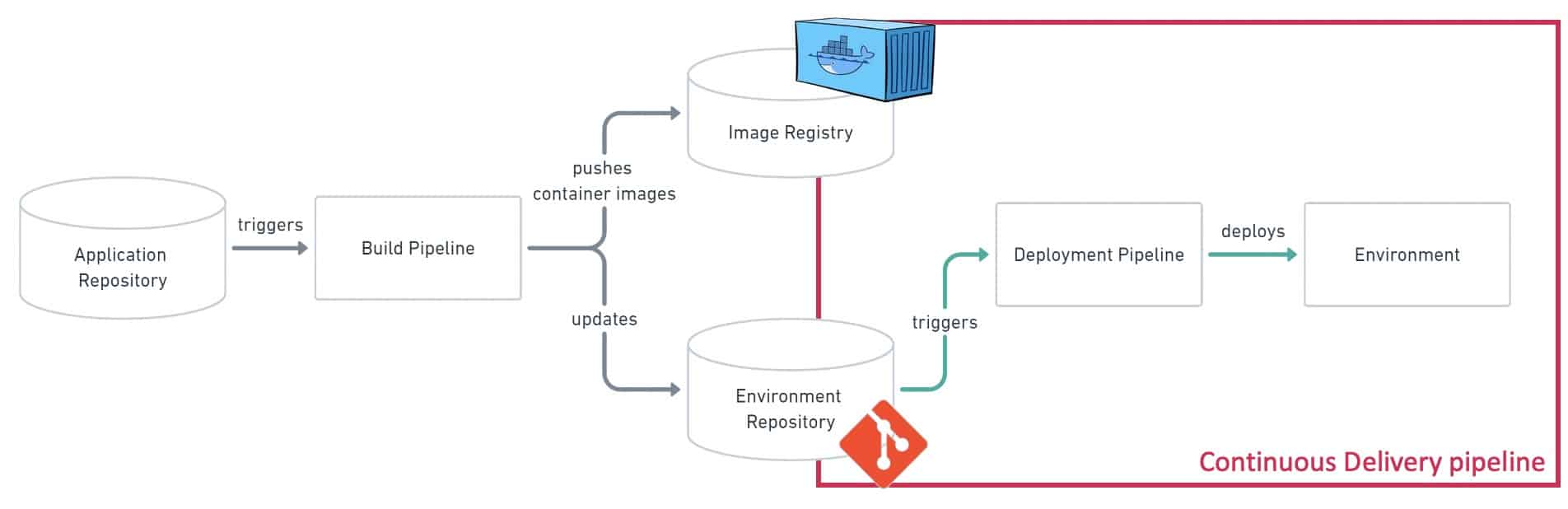
With the well-known and most used push-based approach, the deployment is performed from outside the Kubernetes cluster. As it can achieve the same kind of results about the desired state of the system, it does not offer the feedback loop and the observability provided by the Operator. From a security perspective, the pull-based approach and its Operator are undoubtedly better than credentials with top-level permissions…
As introduced earlier, the push-based approach is preferred in most companies and this is not about to change… Kubernetes and Cloud-native are huge pieces of the Digital Transformation roadmaps, but companies also have legacy infrastructures. While the apps move to Kubernetes, databases or Windows workloads for instance are likely to stay on Virtual Machines for a couple of months – in this context and in combination with Helm, DevOps tools like Ansible remain very convenient.
While CI/CD pipelines are often described as a linear process, the GitOps approach also stands that CI and CD can be separated as two different processes in both pull / push approaches. In some circumstances, it is interesting to think about a set of Microservices – or Product – as a single unit of deployment. With GitOps, we can now manage deployments in different clusters depending on the git branch in a full declarative way!
As part of their Digital Transformation, many companies embrace DevOps methodologies and new technologies such as Containers, Kubernetes and Cloud… The first major milestone is undoubtably the go-live in a Production environment of a Business Application using Git as a Single Source of Truth to describe the Kubernetes resources such as:
With Kubernetes, all these resources are part of the same unit of deployment (or two – one for global resources and namespaces, one for namespace-scoped resources) and they will coexist in the same Git repository…
The ownership and responsibility of the current or the equivalent of the Kubernetes ressources are today distributed throughout IT departments of the company – this is what we call the "millefeuille"…
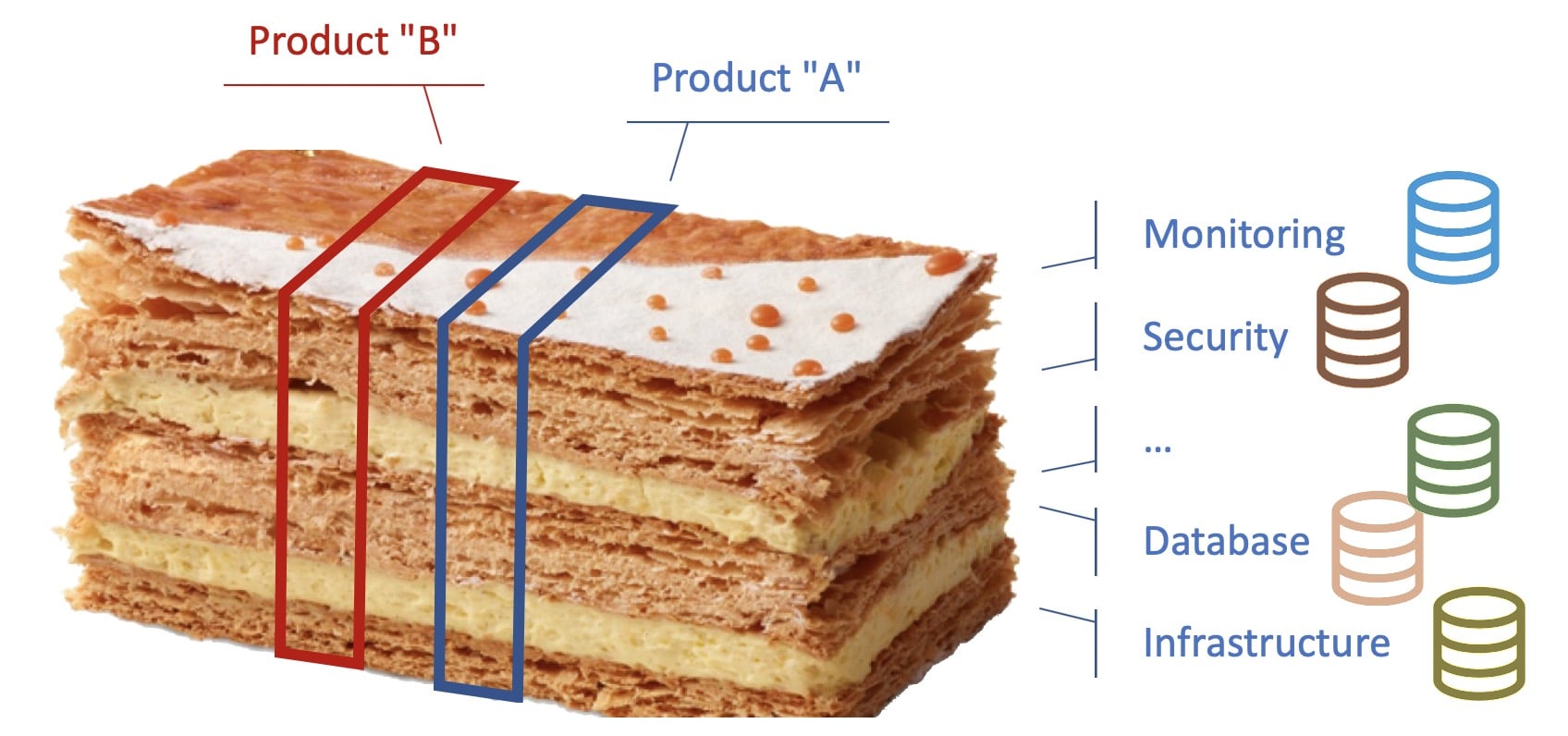
source: based on the interpretation of the millefeuille by Jean-François Piège
Instead of a classic representation of IT services / departments as silos, let’s represent them as the independent layers of the famous French pastry called "millefeuille". In most companies, existing policies, tooling and governance based on ITIL practices make each IT department having its own tools and obviously source of truth from the department perspective.
For instance, the database team generally has an inventory of databases, whereas the network team has a tool to manage network devices and all associated rules/policies without any connection between these two datastores.
With the "millefeuille", each layer is independent and represents an IT department that has its own domain and its own responsibility, leading to partial sources of truth within teams. In the end, a entire deployment is a succession of independent tickets/queues, manual actions, … Troubleshooting an issue in Production often requires to rebuild the knowledge for the Product under investigation.
Thanks to the concept of "context wagon", the story and issues about troubleshooting were greatly depicted in the presentation Operations: The Last Mile Problem For DevOps by Damon Edwards during the DevOps Enterprise Summit London 2018.
While these issues are more DevOps than pure GitOps concerns, the GitOps way of thinking will suffer the same organizational burden and demons of the past. In this context, Kubernetes and GitOps are just another lighthouse telling companies why and how to change their approach to Declarative infrastructure provisioning, environment and change management, … but also to adopt of Product-centric view, that is also largely promoted by Agile methodologies.
However, there is a huge difference:
There are a lot of options to make each team part of the "GitOps" deployment process, using Git collaboration tools such as Pull-Request / Merge-Request reviews and approvals. For instance, the security and network teams may be part of the review and approval of pull requests related to NetworkPolicy resources. For a finer-grained process, the CodeOwner plugin for Git can help in defining individuals or teams responsible of specific files in a repository.
Kubernetes deployments are always described as a single transaction with the API Server through the kubectl CLI. However, either in the Cloud or on-premise, enterprise-grade deployments typically involve external APIs, endpoints or engines to configure.
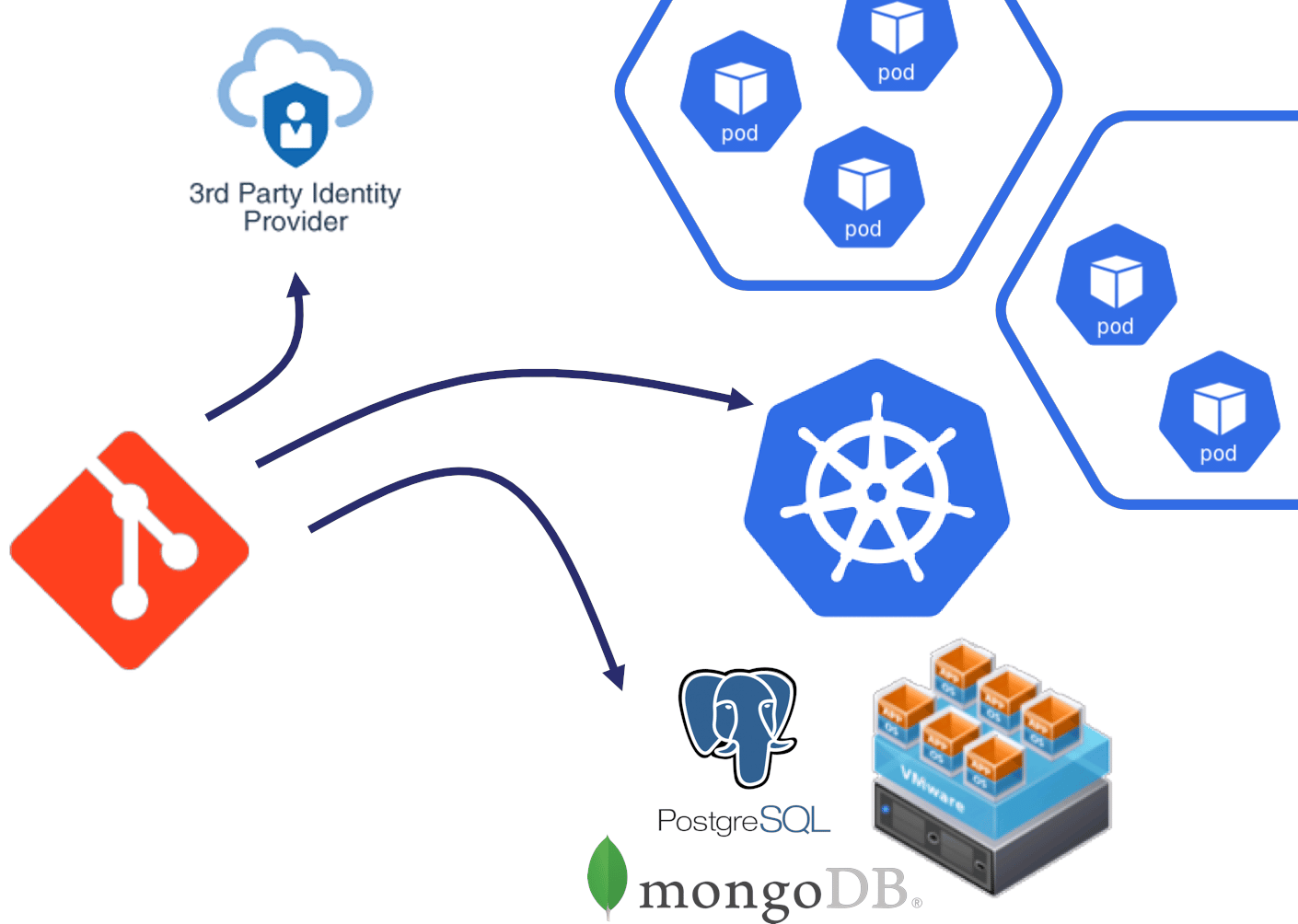
Considering the various system to configure in addition to the Kubernetes workloads, the diagram below represents a serious option to implement the CD pipeline:
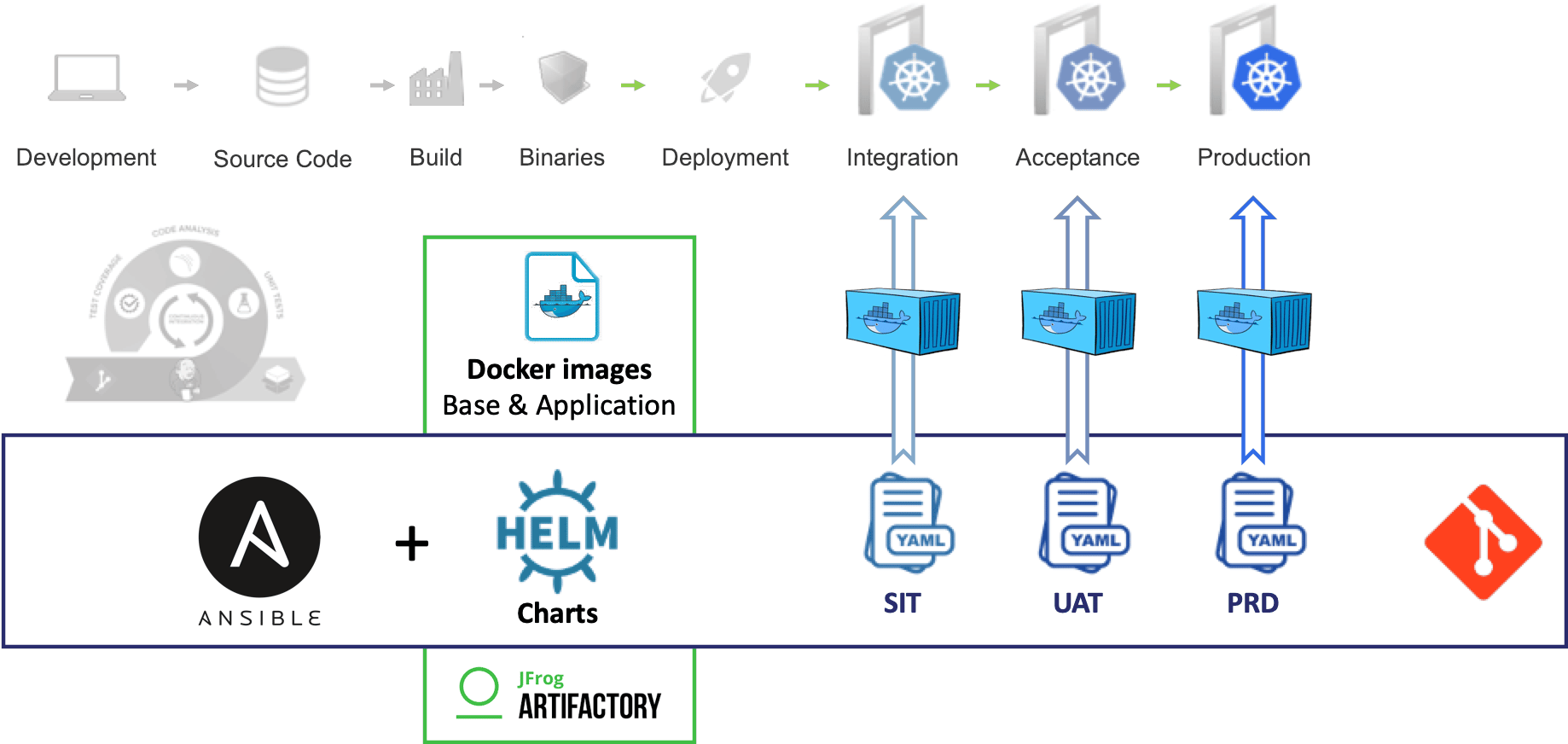
A GitOps push-based approach has been used with a combination of Ansible and Helm to deploy applications in the different Kubernetes environments and on legacy infrastructure.
The CI pipeline produces the Docker images and publishes them into a Container Registry. This is not the purpose of this blog post to describe how to build enterprise-ready docker images or to review the organization of Docker registries but keep in mind it is also a very important part of the DevSecOps approach, to bring automation and security all along the CI/CD pipeline.
Helm was used at the beginning but in the context of some projects we decided to remove it.
Not because of the security: Helm v2 with Tiller was not a security issue — as we can hear very often — thanks to the Tillerless approach. Thus, Helm v3 doesn’t use Tiller anymore.
While Helm is very popular in the Kubernetes ecosystem, we decided not to use it in the context of that story, but why?
Helm or Kubernetes Operators are definitely perfect matches for software editors to distribute their packaged offerings and give their users/customers an easy and standard way to configure and deploy the solution.
While Ansible is perhaps not the best option for Kubernetes deployments (k8s_module), it makes really sense in the Enterprise story of GitOps & pushed-based deployments on Virtual Machine and Kubernetes clusters.
As any design and decisions, we bring on the table opinions that are valid in space – our Enterprise context – and time – before the arrival of Helm 3.
Just like Helm, Ansible has the capability to create templates of Kubernetes resources… but why creating templates?
Each company designing software has a set of common ground practices, tooling and frameworks:

Some people hate frameworks or scripts that hide complexity behind the so-called "black magic". However, it is necessary to bring standards in the enterprise for:
Whether with Helm or Ansible, one should decide the degree of liberty when it comes to templating… what do you expose? what do you allow to be overridden without breaking enterprise or security rules?
These questions would find their answers in a tradeoff between all the DevSecOps stakeholders. However, as a few rules of thumb:
A lot of companies have designed micro-services to answer business needs with more or less success to the extend that some folks now come up with idea to not use microservices…
Monoliths are the future because the problem people are trying to solve with microservices doesn’t really line up with reality. Kelsey Hightower
That said, one key ability – to deploy microservices completely independent of one another – may not be fully respected in the Enterprise context of microservices deployment. Adding to the mix non-frequent releases and a complex release process end up with deploying microservices as a monolith stack – which seems to be a complete anti-pattern at first glance, but can make sense in a declarative Product-centric approach…

With the Kubernetes / GitOps fully declarative approach, it is interesting to maintain a complete and consistent Application Manifest of the Product by leveraging the Enterprise templates described in the previous section.
Either with Ansible or Kubernetes idempotent design, a new deployment of the entire Product only apply changes by comparing the desired GitOps state and the current system state.
The GitOps approach enforces a declarative, complete, versioned and consistent Manifest of the Product, which would delight any Release / Environment Manager.
The journey to Kubernetes tends be long and tedious as it involves many changes including Cloud-Native Applications, CI/CD toolchain, Infrastructure and Environment provisioning, knowledge about containers and orchestration, operational processes, etc. But any journey starts with a first step in the right direction!
The declarative approach — brought by the DevOps movement and enforced by Kubernetes & GitOps — brings a lot of power using Git as the Source of Truth and integrate quite easily in the Enterprise with dozens of applications and IT environments. The story might be seen as a half-way (push-based) GitOps approach — but is the glass half full or half empty?
All these changes shake up more than ever the established assumptions, the existing tooling, the organizational structure and people. Many challenges and solutions have identified during our journey in which security and automation are at the heart.
A few topics have been left aside for a larger consideration than just a section of this article: