
By Lionel Gurret.
Comme vous le savez certainement Kubernetes est une plateforme d’orchestration de conteneurs gratuite et open source. Elle vous permet de gérer les environnements conteneurisés et fournit des fonctionnalités telles que l’auto-réparation, le déploiement, les rollbacks, le scaling et le packaging!
Le stockage n’est peut-être pas votre principale préoccupation si vous exécutez des charges de travail stateless ou si vous débutez avec Kubernetes, mais ce sera l’un des défis que vous devrez relever le jour où vous exécuterez des applications statefulls.
En outre, si vous envisagez de configurer des clusters sur plusieurs datacenters, d’effectuer des sauvegardes, de la haute disponibilité, d’utiliser différents types de stockage, ou de chiffrer vos données… Vous devrez rechercher une solution adaptée à vos besoins…
Avant de présenter Portworx, il est important de passer rapidement en revue les différents types de stockage sur lesquels nous pouvons nous reposer. En effet, la première étape consiste à définir celui que vous utiliserez pour vos conteneur :
Stockage en mode fichier : l’équivalent d’un serveur NFS. Les performances sont inférieures aux deux autres mode de stockage. Cependant, il est le seul à prendre en charge le mode d’accès ReadWriteMany(expliqué dans la prochaine partie de cet article de blog.)
Stockage en mode bloc : l’équivalent à un système de fichiers sur une partition disque. Le plus efficace, mais RWO uniquement.
Stockage en mode objet : Stockage d’objets compatibles S3. C’est à l’application déployée dans le pod à communiquer avec le protocole S3.Notez qu’il existe une norme émergente pour Kubernetes : la Container Object Storage Interface (COSI). qui prend en charge S3, Google Cloud Storage, Azure Blob,…
Voici un résumé :
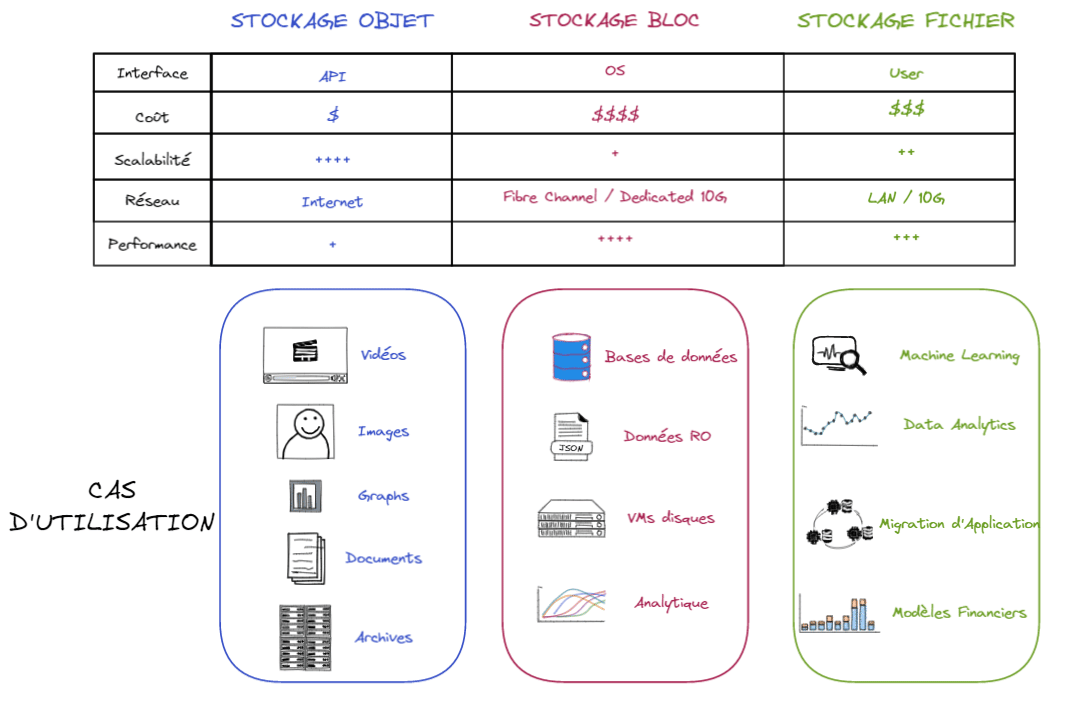
Comme vous pouvez le constater, ils ont tous des avantages et des inconvénients. Comme le stockage en mode fichier organise les données avec une hiérarchie de fichiers et de dossiers et le "block storage" en plusieurs petits blocs de données, le stockage en mode bloc peut être plus souple dans son utilisation que le stockage en mode fichier. Ainsi, il est plus facile d’adapter le stockage en mode bloc aux environnements utilisant des conteneurs. Enfin, le stockage en mode objet pourrait être une excellente alternative si une forte scalabilité est votre priorité.
Portworx est une solution de stockage en mode bloc qui fournit une couche Cloud-Native à partir de laquelle les applications conteneurisées _stateful _consomment par programmation des services de stockage en mode bloc, fichiers et objets directement via le scheduler Kubernetes.
Avec Kubernetes, un PersistentVolume (PV) peut être monté sur un hôte de n’importe quelle manière prise en charge par le provider. Le mode d’accès de chaque PersistentVolume est défini par un mode d’accès spécifique :
Par exemple, le mode d’accès ReadWriteMany peut être utilisé par des applications telles que des serveurs Webs (Nginx, WordPress, etc.) capables de gérer plusieurs instances écrivant sur le même volume. Cependant, il ne sera pas recommandé de l’utiliser pour les bases de données.
Comme nous le verrons ensemble, Portworx est livré avec de nombreuses fonctionnalités et prend en charge les modes d’accès ReadWriteOnce et ReadWriteMany.
De nos jours, la plupart des organisations hébergent une part croissante de leur charge de travail applicative sous forme de conteneurs. Les outils d’orchestration tels que Kubernetes peuvent héberger des centaines et des milliers de ces applications sur de gros clusters.
Ces conteneurs ont besoin d’accéder à un stockage qui peut être provisionné de manière dynamique, à la demande et le plus rapidement possible. Vous pouvez également avoir besoin de quotas, de RBAC (Role Based Access Control) et de cryptage pour sécuriser les données.
Dans une configuration HA, les charges de travail applicatives doivent parfois être déployées dans différentes régions. Le problème avec la plupart des solutions de stockage(par exemple les volumes EBS sur AWS) est que vous ne pouvez l’attacher qu’à un seul nœud.
Tous ces défis peuvent être pris en charge par Portworx. A titre d’information, cette solution de stockage et de gestion de données de bout en bout pour tous vos projets Kubernetes a récemment été acquise par PureStorage pour un montant de 370 millions de dollars.

Portworx peut être installé sur site ou sur des clouds publics tels que GCP, AWS, Azure, etc.
Il est installé à l’aide de conteneurs et il est facile d’installer et de gérer les composants Portworx via de simples fichiers YAML. Vous pouvez installer Portworx dans un modèle "hyperconvergé" (stockage PX et calcul sur les mêmes nœuds) ou "désagrégé" (stockage PX et calcul sur différents nœuds).
Comme la plupart des plates-formes distribuées, Portworx implémente une interface de contrôle et une interface de gestion de données.
L’interface de contrôle (control plane) agit en tant que centre de commande et de contrôle pour tous les nœuds de stockage participant au cluster (le provisionnement et la gestion des volumes).
Chaque nœud de stockage exécute une interface de données (data plane) responsable de la gestion des E/S et des périphériques de stockage connectés (quel volume est monté sur quel nœud).
L’interface de contrôle et de données s’exécutent tous deux en mode distribué. Cela garantit la haute disponibilité du service de stockage. Pour obtenir la meilleure disponibilité, Portworx recommande de configurer au moins trois nœuds de stockage dans un cluster. Selon la taille du cluster, chaque nœud peut faire tourner le control plane ainsi que les composants du data plane. Dans les grands clusters, il est possible d’avoir des nœuds qui ne participent pas au data plane, ce qui signifie qu’ils ne sont pas désignés comme nœuds de stockage.
Portworx fonctionne généralement avec moins de 3% d’overhead !
Enfin, Portworx collecte des métriques à partir des systèmes physiques, des services virtuels, du réseau, des demandes d’E/S, qui peuvent être collectées à l’aide d’outils comme Prometheus et affichées dans des tableaux de bord à l’aide de Grafana.
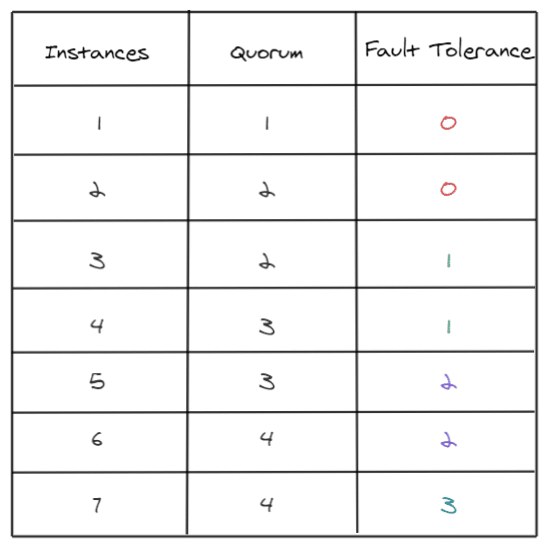
Comme indiqué précédemment, Portworx recommande de faire tourner au moins trois nœuds de stockage dans un cluster. Dans un cluster Portworx, tous les nœuds sont actifs en permanence. Cependant, un leader doit être sélectionné et élu par les membres du cluster. En utilisant le protocole RAFT, à un moment aléatoire et en utilisant des algorithmes, un nœud demandera à d’autres nœuds d’être le leader. Une fois que tous les noeuds seront d’accord sur le noeud "leader", chaque nœud supposera que ce nœud est le leader. Dans le cas où les nœuds ne reçoivent pas de notifications de sa part pendant un certain temps (problème de réseau, leader en panne), les nœuds initieront un nouveau processus d’élection.
Toutes les informations concernant le cluster sont stockées dans une base de données RAFT stockée en interne sur chaque nœud.
Enfin, a titre de rappel, pour calculer le Quorum, vous pouvez utiliser la formule suivante :
quorum = abs (((number of nodes) / 2) + 1)
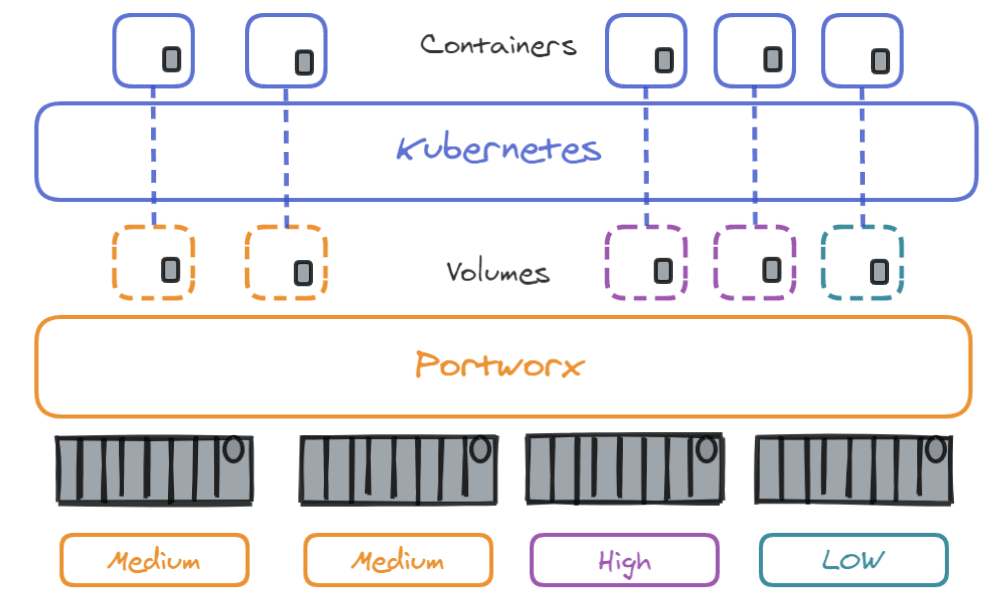
Portworx regroupe le stockage de tous les nœuds de travail (work nodes) Kubernetes du cluster dans un seul grand pool de stockage virtuel. Il est capable d’organiser le stockage par pool en fonction de leur utilisation et de leur priorité d’E/S via les StorageClasses, comme décrit ci-dessous :
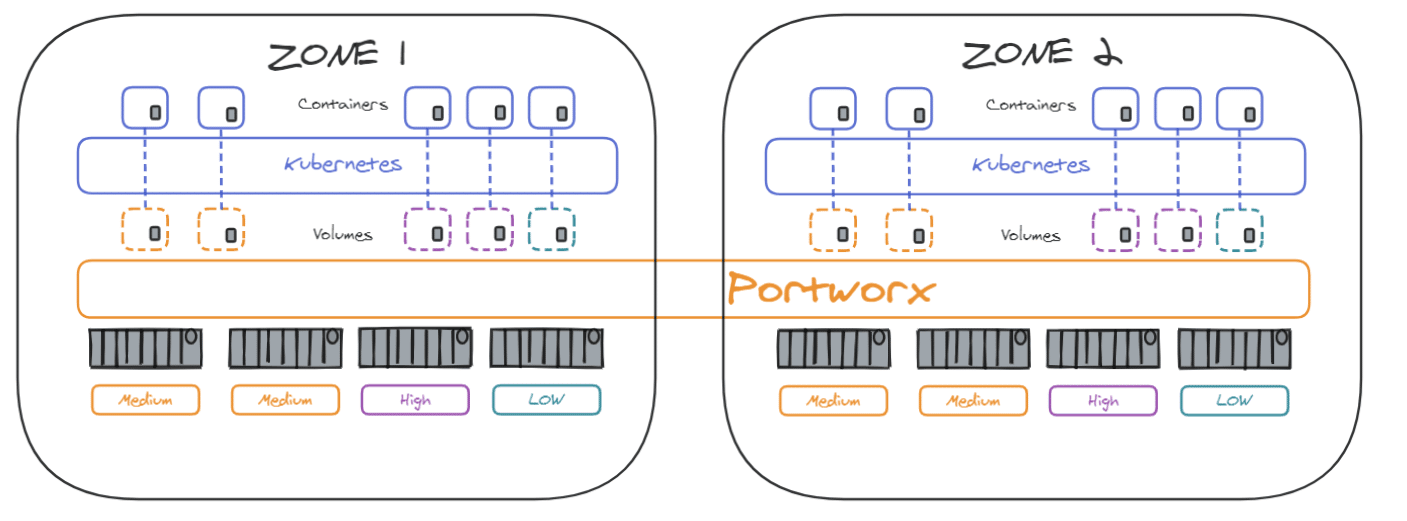
Il existe désormais un pool global de stockage qui peut être utilisé pour créer des volumes utilisés par nos conteneurs. Un grand avantage de Portworx est que même si le stockage est situé sur un nœud spécifique, il vous permet de l’utiliser sur n’importe quel nœud du cluster. Même si les nœuds n’ont aucun stockage sur eux !
Le cluster Portworx peut également être étendu sur des datacenters se situant dans des zones de disponibilité différentes pour assurer la haute disponibilité en cas de panne :
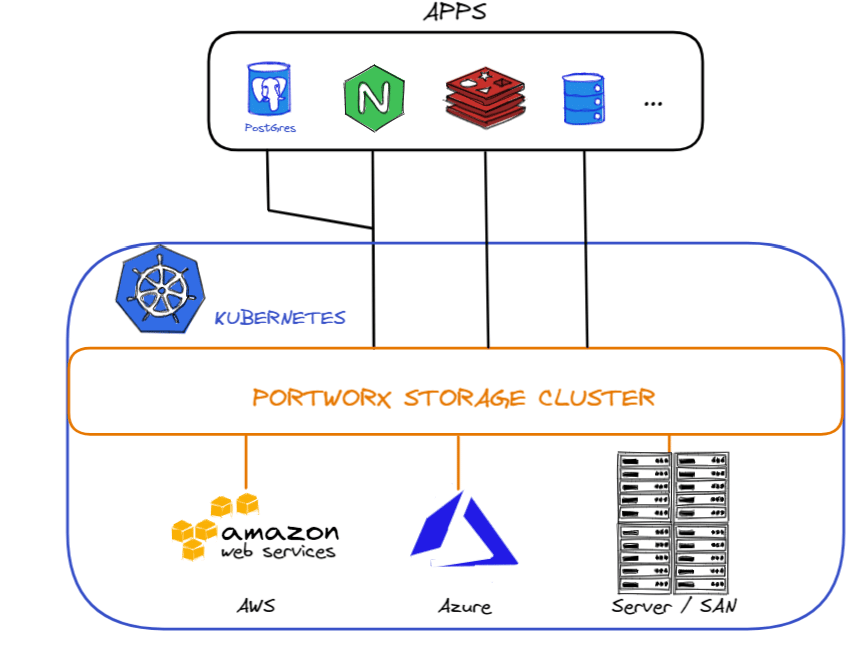
1 – Agrégation de disque (aggregation sets) : lorsque vous créez un volume, il est attaché par défaut à un hôte unique. Via l’agrégation de disque, vous pouvez éventuellement avoir le volume "éclaté" sur différents disques et différents hôtes. Le stockage est ainsi vu comme un seul volume . Cela peut être utile en termes de capacité et de performance. Comme vous pouvez le voir ci-dessous, ce cluster Kubernetes s’appuie sur 3 solutions de stockage différentes (AWS, Azure et un SAN)
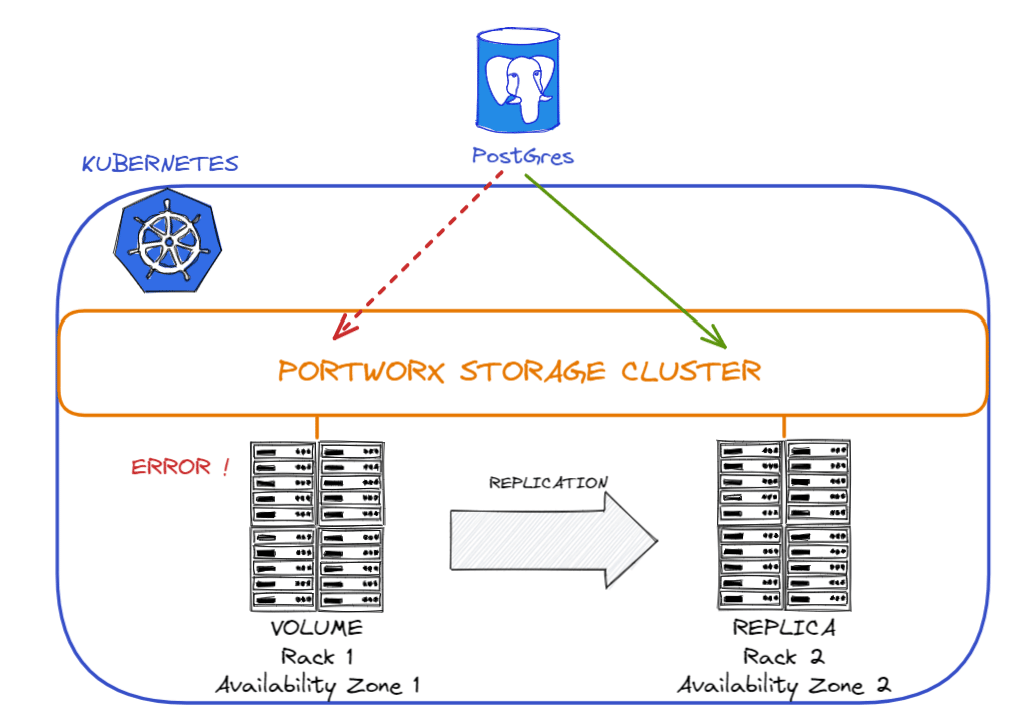
2 – Replication Sets : vous pouvez créer des volumes avec des "Replication Sets", cela vous permettra d’avoir une copie de votre volume. Vous pouvez créer 3 copies par volume.
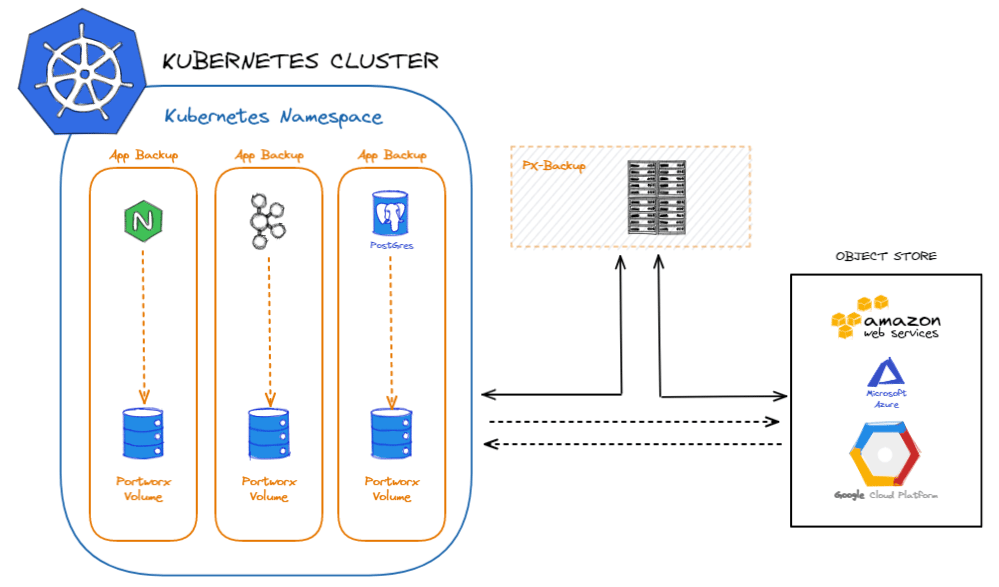
Vous pouvez sauvegarder vos volumes Portworx via AWS, GCP ou Azure. Si vous êtes confronté à une panne, les données sauvegardées peuvent être restaurées dans des volumes avant de migrer les applications. Portworx Backup gère le cycle de vie des données du conteneur, catalogue les métadonnées pertinentes, améliore la visibilité de l’accès aux données et permet la restauration d’applications Kubernetes complètes, y compris les données, la configuration des applications et les ressources Kubernetes en un seul clic.
Lighthouse est un moyen simple, intuitif et graphique de gérer et de surveiller les clusters Portworx. Lighthouse fonctionne comme un conteneur Docker, ce qui permet de l’exécuter sur un ordinateur portable.
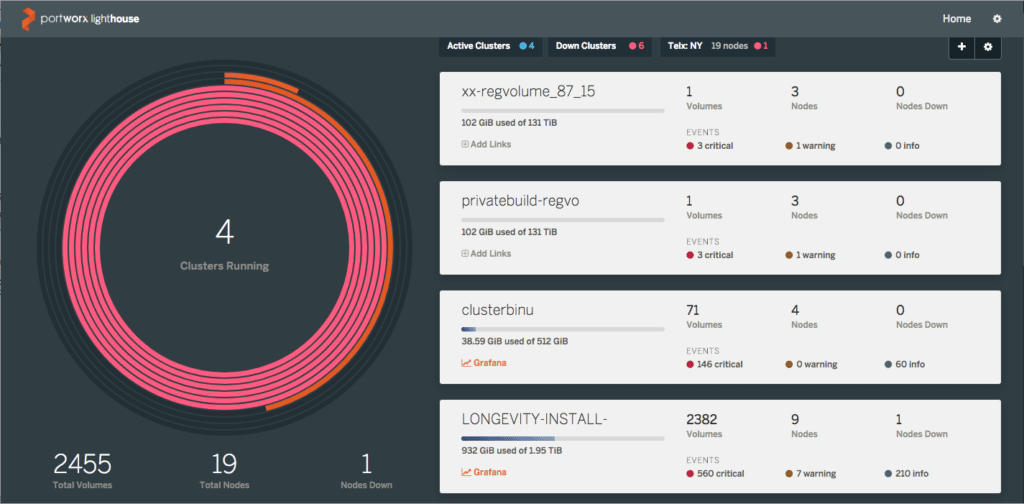
L’ajout ou la suppression de clusters dans cette interface est simple. Cliquez simplement sur les icônes Ajouter/Gérer en haut de l’écran. La vue peut être configurée pour filtrer les clusters en fonction de l’état « actif » ou « inactif », ou par région. Vous pouvez ensuite cliquer sur n’importe quel cluster pour explorer les nœuds, les volumes, les snapshots ou les conteneurs exécutés.
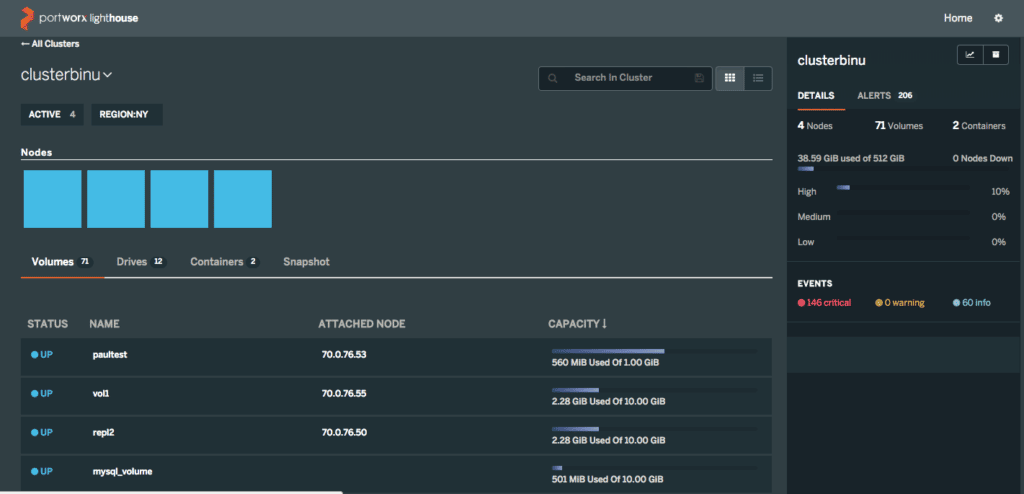
Toutes les données de la page du cluster ci-dessus sont consultables, ce qui facilite la navigation vers des volumes ou des nœuds spécifiques.
Enfin, Portworx est intégré à Prometheus et Grafana depuis un certain temps déjà et dans les dernières versions de Lighthouse, il est possible d’avoir des raccourcis directs vers ces services directement depuis le tableau de bord. Lighthouse offre un moyen rapide de résoudre les problèmes de manière plus approfondie en filtrant en fonction du temps :
Une fois vos volumes créés (voir aide-mémoire), vous devrez attacher votre stockage aux conteneurs.
Pour ce faire, vous pouvez utiliser les commandes suivantes :
# Créer du stockage un volume Docker
$ docker volume create --driver pxd --name px_vol --opt nodes="node1" --opt size=10
# Attacher le stockage à un conteneur Docker
$ docker run -v pwx_vol:/data nginx
# Les deux commandes précédentes en une seule
$ docker run --volume-driver=pxd -v name=pwx_vol,nodes=node01,size=10:/data nginxConsultez la documentation officielle ici.
C’est assez simple, vous devrez exécuter une simple commande kubectl avec un fichier de configuration et toutes les ressources telles que le Namespace, les Daemonsets, les ClusterRoles ou les Services seront provisionnées sur le cluster. D’autres composants seront déployés tels que API Server, Stork ou Lighthouse (discutés dans le cours précédent)
Pour utiliser Portworx sur Kubernetes, vous devrez vous familiariser avec les ressources PersistentVolumes, PersistentVolumeClaims et StorageClass. Vous pouvez trouver des informations directement sur mon site Web ou sur la documentation officielle de Kubernetes.
Étape 1 : Créer une classe de stockage.
Création de la StorageClass que vous utiliserez avec vos PVC :
kubectl create -f examples/volumes/portworx/portworx-sc.yamlExemple :
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: portworx-sc
provisioner: kubernetes.io/portworx-volume
parameters:
repl: "1"Vérifiez que la StorageClass est créée :
kubectl describe storageclass portworx-sc
Name: portworx-sc
IsDefaultClass: No
Annotations: <none>
Provisioner: kubernetes.io/portworx-volume
Parameters: repl=1
No events.Etape 2: Créer une Persistent Volume Claim.
Création de la persistent volume claim :
kubectl create -f examples/volumes/portworx/portworx-volume-pvcsc.yaml Exemple :
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: pvcsc001
annotations:
volume.beta.kubernetes.io/storage-class: portworx-sc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2GiVérifier que la PersistentVolumeClaim a été créée :
kubectl describe pvc pvcsc001
Name: pvcsc001
Namespace: default
StorageClass: portworx-sc
Status: Bound
Volume: pvc-e5578707-c626-11e6-baf6-08002729a32b
Labels: <none>
Capacity: 2Gi
Access Modes: RWO
No Events.Etape 3: Créer un POD qui utilise la Persistent Volume Claim avec la bonne classe de Stockage.
Création du POD :
kubectl create -f examples/volumes/portworx/portworx-volume-pvcscpod.yamlExemple :
apiVersion: v1
kind: Pod
metadata:
name: pvpod
spec:
containers:
- name: test-container
image: gcr.io/google_containers/test-webserver
volumeMounts:
- name: test-volume
mountPath: /test-portworx-volume
volumes:
- name: test-volume
persistentVolumeClaim:
claimName: pvcsc001Comme nous en avons discuté dans un article de blog précédent, les opérateurs Kubernetes ajoutent un point de terminaison à l’API Kubernetes, appelé "custom resource definition" (CRD), ainsi qu’un "control plane" qui surveille et maintient les ressources définies par le CRD.
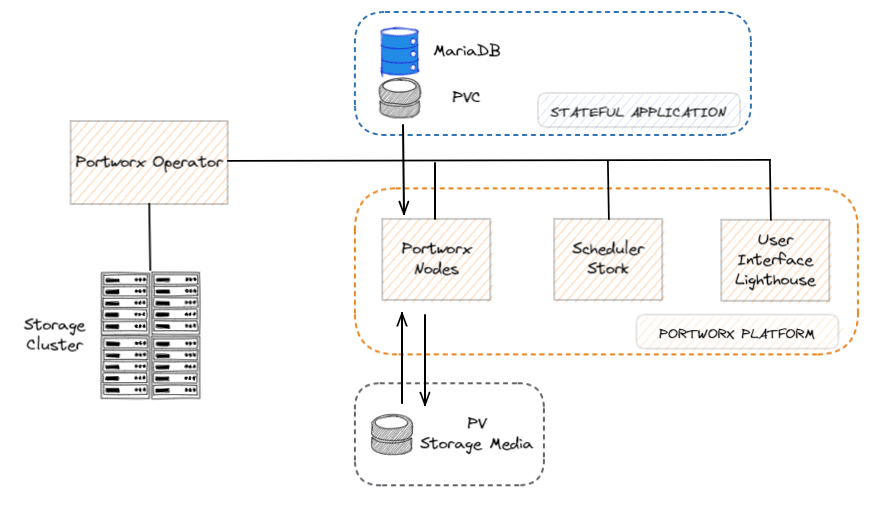
Portworx Operator est là pour vous aider à installer, configurer et mettre à jour Portworx.
Comme le montre le schéma ci-dessous, l’opérateur gère la plate-forme Portworx composée des nœuds Portworx, du scheduler Stork, de l’interface utilisateur Lighthouse et d’autres composants qui rendent l’exécution des applications stateful transparente pour les utilisateurs :
PXCTL est l’utilitaire de ligne de commande, utilisé pour afficher et configurer les modifications apportées à la solution Portworx. Il peut être lié au cluster Portworx, aux volumes, aux snapshots, aux migrations, aux alertes, aux secrets, aux rôles, aux informations d’identification, etc.
Voici quelques commandes de base :
# Afficher l'aide
$ pxctl help
# Vérifier l'état du cluster
$ pxctl status
# Vérifier le status du cluster au format JSON
$ pxctl status --json
# Lister les noeuds dans le cluster, Cluster ID et Cluster UUID
$ pxctl cluster list
# Inspect node
$ pxctl cluster inspect
# Exemple de création de volume
$ pxctl volume create <volname> -s <size default 1GB>
# Lister les volumes
$ pxctl volume list
# Snapshoter un volume
$ pxctl volume snapshot create --name <SnapName> <VolName>
# Lister les storage pools
$ pxctl service pool show
# Updater le "pool IO priority"
$ pxctl service pool update --io_priority=medium 0
# Créer un volume "called user_volume" avec 2 replicas de 2GB
$ pxctl volume create user_volume -r 2 -s 2
# Créer un shared volume
$ pxctl volume create user_volume --shared yes
# Créer un volume avec 2 replicas
$ pxctl volume create rep_volume --repl 2
# Créer un volume avec agrégation (à travers 3 neouds)
$ pxctl volume create vol_b --aggregation_level 3
# Supprimer un volume
$ pxctl volume delete user_volume
# Attacher un volume à un host
$ pxctl host attach testvol
# Détacher un volume d'un host
$ pxctl host detach testvol
# Monter un volume
$ pxctl host mount testvol --path /var/lib/osd/mounts/testvol
# Démonter un volume
$ pxctl host unmount testvol --path /var/lib/osd/mounts/testvolComme décrit dans ce sondage, la question du stockage et avoir une infra déployée sur plusieurs datacenters sont connus comme les principaux défis à relever avec les conteneurs.
Étant donné que de nombreuses entreprises ont d’abord déplacé les charges de travail stateless vers des conteneurs, il est logique qu’elles continuent d’investir dans des solutions pour les services stateful à mesure qu’elles augmentent leur adoption de conteneurs.
Portworx est l’une de ces solutions parmi d’autres telles que Longhorn, StorageOS, Rook, OpenEBS ou Diamanti.
Chaque solution a – bien sûr – des avantages et des inconvénients mais selon moi, les facteurs les plus importants à prendre en compte lors de votre choix de solution de stockage pour les conteneurs et Kubernetes sont les suivants :