
By Gaetan Metzger.
Le platform engineering est une trend. L’IA lui a volé la vedette — mais les deux vont de pair : pas de plateforme solide, pas d’IA exploitable en production. Si le sujet vous est nouveau, l’article dédié au platform engineering pose les fondations.
Mettre en place un Internal Developer Portal, c’est faciliter la collaboration entre équipes et réduire drastiquement la charge cognitive des ingénieurs.
Backstage est un framework open source développé par Spotify en interne pour résoudre exactement ces problèmes à son échelle — des centaines d’équipes, des milliers de services.
Ils savaient dès le départ que chaque équipe a des besoins différents. Et qu’une grande entreprise en a encore plus. C’est pourquoi ils l’ont conçu modulaire et extensible : un core open source sur lequel chaque organisation construit son propre portail.
Spotify a depuis lancé une version managée (Spotify Portal) pour ceux qui ne veulent pas opérer l’infrastructure eux-mêmes. Mais la force de Backstage reste sa capacité à s’adapter à votre contexte — pas l’inverse.
Au-delà de la modularité, Backstage est avant tout une couche d’abstraction. Les briques platform — CI/CD, secrets, provisioning cloud, observabilité — sont souvent puissantes mais difficiles à exploiter pour les équipes produit. Backstage leur offre une interface unifiée : un seul point d’entrée, sans avoir à maîtriser chaque outil sous-jacent.
Un IDP comme Backstage, c’est la cerise sur le gâteau du platform engineering. Tout le travail d’exposition des APIs, de structuration des équipes, d’automatisation des workflows — Backstage lui donne une interface. Il rend visible ce qui est invisible, accessible ce qui est complexe.
Vous connaissez ce scénario.

Ce n’est pas un problème de personnes. C’est un problème de charge cognitive.
Dans les équipes IT, personne ne peut tout savoir. Les systèmes grossissent, les équipes tournent, les contextes changent. Sans structure, chaque information devient une chasse au trésor — et ce coût invisible s’accumule sprint après sprint, jusqu’à ralentir tout le monde.
Un Internal Developer Portal (IDP) règle ce problème à la source : il centralise ce qui existe, qui en est responsable, et comment l’utiliser.
Backstage repose sur trois briques fondamentales :
Software Catalog — la carte de votre système.
Chaque service, API, librairie ou pipeline est référencé avec son propriétaire, ses dépendances, son état. Fini le « je sais pas qui gère ça » — la réponse est dans le catalog, en un clic.
Concrètement, ça ressemble à un fichier catalog-info.yaml à la racine de chaque repo :
# Cas minimal — enregistrer un service dans le catalog
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: payment-service
description: Service de paiement
spec:
type: service
lifecycle: production
owner: team-paymentsUn fichier, un commit, et votre service est visible dans le portail. Mais en pratique, on va plus loin :
# Cas réaliste — avec dépendances, liens et TechDocs
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: payment-service
description: Gère les transactions Stripe et PayPal
annotations:
backstage.io/techdocs-ref: dir:. # active TechDocs sur ce repo
github.com/project-slug: sokube/payment-service
tags:
- payments
- critical
links:
- url: https://grafana.internal/d/payment-dashboard
title: Dashboard Grafana
icon: dashboard
spec:
type: service
lifecycle: production
owner: team-payments
system: checkout-platform
dependsOn:
- component:order-service
- resource:postgres-payments
providesApis:
- payment-apiCe fichier devient la source de vérité du composant : qui en est responsable, de quoi il dépend, quelle API il expose, où est sa doc. Tout ça visible dans le portail, sans réunion, sans ticket.
TechDocs — la documentation là où elle doit être.
La doc vit dans le repo, au format Markdown, versionnée avec le code. Elle s’affiche directement dans Backstage. Plus besoin de fouiller Confluence, de tomber sur une page périmée de 2021.
Scaffolder — l’accélérateur de nouveaux projets.
Des templates as-code pour scaffolder un nouveau service en quelques minutes, avec les bonnes pratiques, les bons secrets, les bonnes configurations — déjà câblés.
Tout ça as code. Versionné. Reviewable. Auditable.
Backstage est une application Node.js/TypeScript composée de deux parties distinctes — souvent hébergées dans un même dépôt, mais que rien n’empêche de séparer :
packages/
app/ # frontend React — ce que voient vos équipes
backend/ # API Express — orchestration, catalog, providersLe frontend est une application React. Il expose les plugins sous forme de pages et d’onglets. Vous pouvez le personnaliser — routing, vues, tableaux de bord — sans toucher au backend.
Le backend orchestre tout : il lit les catalog-info.yaml, interroge les providers externes (GitHub, GitLab, AWS, PagerDuty…), stocke les entités dans une base PostgreSQL, et sert les données aux plugins frontend via une API interne.
Chaque outil de votre stack peut devenir un onglet dans Backstage. Un plugin, c’est un package npm en deux parties :
L’installation se résume à ajouter les packages npm et à les enregistrer dans packages/app/src/App.tsx (frontend) et packages/backend/src/index.ts (backend).
Si une brique manque, il y a de grandes chances qu’un plugin existe déjà. La bibliothèque de plugins Backstage recense plusieurs centaines de contributions communautaires — Kubernetes, Datadog, PagerDuty, GitHub Actions, Vault, ArgoCD… Votre DSI peut intégrer de nouveaux composants dans Backstage sans redévelopper le portail depuis le début. L’extensibilité n’est pas un bonus — c’est un pilier de l’adoption en entreprise.
Le plugin Kubernetes permet de voir directement dans Backstage l’état des deployments et pods liés à un service — sans quitter le portail, sans kubectl.
# plugin frontend
yarn --cwd packages/app add @backstage/plugin-kubernetes
# plugin backend
yarn --cwd packages/backend add @backstage/plugin-kubernetes-backendConfiguration dans app-config.yaml :
kubernetes:
serviceLocatorMethod:
type: multiTenant
clusterLocatorMethods:
- type: config
clusters:
- url: https://k8s.internal
name: production
authProvider: serviceAccount
serviceAccountToken: ${K8S_SERVICE_ACCOUNT_TOKEN}
caData: ${K8S_CA_DATA}Puis une annotation dans le catalog-info.yaml du service pour lier le composant à ses pods :
metadata:
annotations:
backstage.io/kubernetes-label-selector: 'app=payment-service'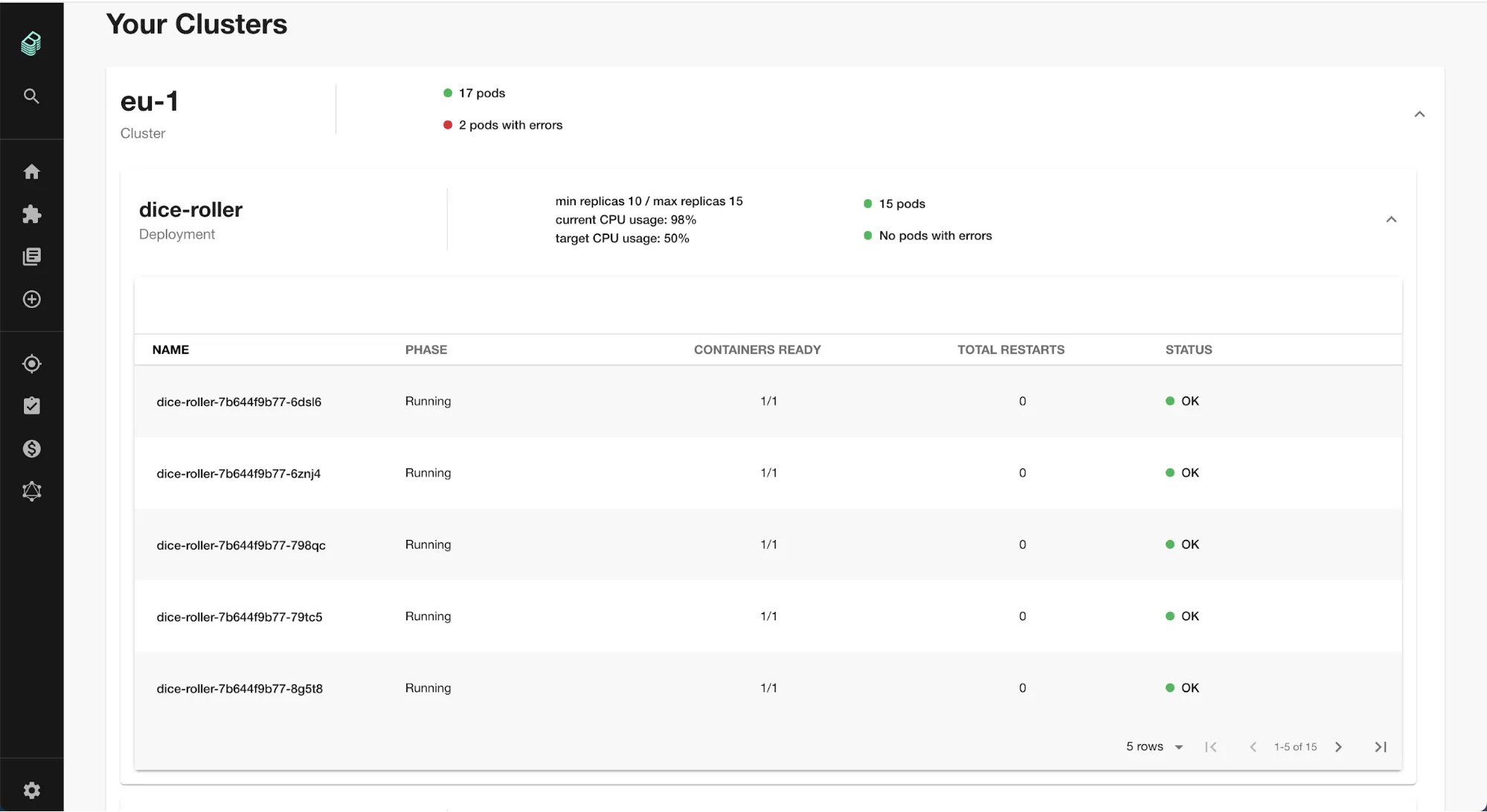
Résultat : un onglet « Kubernetes » apparaît dans la fiche du service. Les devs voient l’état des pods, les derniers déploiements, les erreurs — sans accès direct au cluster. La même logique s’applique à n’importe quel outil de votre stack : Datadog, ArgoCD, Vault, GitHub Actions. Chaque plugin ajoute un onglet, une vue, une intégration — sans réécrire le portail.
Quand on dit que Backstage est « as code », ça ne veut pas dire juste « les fichiers sont dans un repo ». Ça veut dire que Backstage lit vos repos pour se mettre à jour tout seul.
Backstage peut scanner une organisation GitHub ou GitLab entière et importer automatiquement tous les catalog-info.yaml qu’il trouve :
# app-config.yaml — configuration Backstage
catalog:
providers:
github:
myOrg:
organization: sokube
catalogPath: /catalog-info.yaml # cherche ce fichier dans chaque repo
schedule:
frequency: { minutes: 30 } # rescan toutes les 30 minutes
timeout: { minutes: 3 }Un nouveau repo créé avec un catalog-info.yaml apparaît dans le portail à la prochaine sync. Sans action manuelle. Sans ticket « merci d’ajouter notre service dans le catalog ».
C’est la différence fondamentale avec un CMDB ou un spreadsheet : la source de vérité est dans le repo, pas dans un outil externe qu’il faut alimenter à part.
Le champ lifecycle dans le catalog-info.yaml n’est pas cosmétique. Il structure la gouvernance de votre système :
| Lifecycle | Signification |
|---|---|
experimental |
En cours de développement — pas de garantie de stabilité |
production |
Service actif — SLA engagé, breaking changes proscrits |
deprecated |
À migrer — plus maintenu, date de fin de vie connue |
spec:
type: service
lifecycle: deprecated # visible dans le catalog, filtrable, searchable
owner: team-platformLes stakeholders peuvent filtrer le catalog par lifecycle — et identifier en un coup d’œil ce qui est en prod, ce qui est en train de mourir, ce qui est encore en évaluation. La gouvernance par le catalog plutôt que par le spreadsheet.
La visibilité, d’abord. Les managers peuvent voir quels composants sont utilisés, par qui, à quelle fréquence. Ce qui était une boîte noire devient observable.
Ensuite, le cycle de feedback. Un composant exposé dans le catalog peut recevoir des retours directement. Le propriétaire sait si son API est utilisée, si elle pose des problèmes, si elle répond aux besoins. Le cycle de vie d’un service devient vivant — pas figé dans un wiki interne oublié.
Les chiffres parlent d’eux-mêmes : après la mise en place de Backstage, Spotify a mesuré une réduction de 55% du temps d’onboarding de ses ingénieurs. Ce n’est pas un chiffre marketing — c’est le résultat direct d’avoir documenté, centralisé et automatisé ce qui se transmettait auparavant de bouche à oreille.

C’est le point que beaucoup sous-estiment au démarrage : Backstage ne fonctionne bien que si votre plateforme est exposée en API.
Si vos outils internes — CI/CD, secrets management, provisioning cloud, observabilité — ne sont pas consommables programmatiquement, Backstage restera un beau catalog vide. Un portail sans self-service, c’est juste une page Confluence avec un meilleur design.
Un bouton « Créer un ticket Jira » sur une page Confluence, ce n’est pas du self-service. C’est une file d’attente avec une meilleure UX.
API-driven n’est pas une option. C’est le prérequis.
Et c’est là qu’entre en jeu la Team Topology.
Le framework de Skelton & Pais distingue quatre types d’équipes. Deux sont critiques ici :
Backstage est l’interface entre les deux. C’est le « golden path » que la platform team expose aux équipes produit pour qu’elles s’auto-servent — sans dépendre d’un humain pour chaque action.
Sans platform team structurée, sans plateforme exposée en API, Backstage amplifie le vide plutôt que de le combler. L’outil ne remplace pas l’organisation.
Start small.
L’adoption est le plus grand défi. Backstage peut bousculer les habitudes de travail des équipes — comment elles documentent, comment elles créent des projets, comment elles découvrent les services existants.
Si vous démarrez trop large, vous perdez les gens avant qu’ils voient la valeur.
Commencez par une seule équipe, un seul use case concret — le Software Catalog sur un périmètre limité, par exemple. Montrez la valeur rapidement. Laissez les autres équipes venir à vous une fois convaincues.
Chaque stakeholder converti par l’exemple vaut dix fois plus qu’un memo de direction.
Trois choses à retenir :
Et si vous pensez IA : c’est exactement là que Backstage devient stratégique. Une plateforme bien structurée, avec des APIs claires et un portail comme Backstage, est extrêmement propice à une utilisation de l’IA encadrée — des agents capables de provisionner, déployer ou orchestrer en consommant les golden paths définis par votre platform team. Sans cette structure, l’IA reste un outil isolé. Avec elle, c’est un levier de productivité à l’échelle.
